





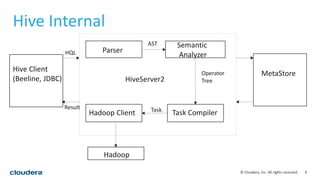
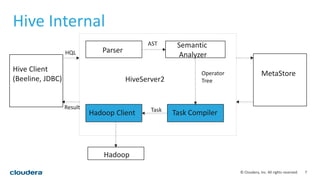
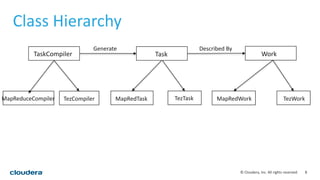
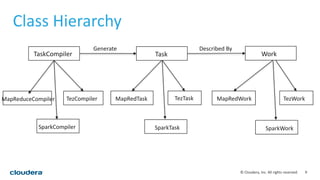
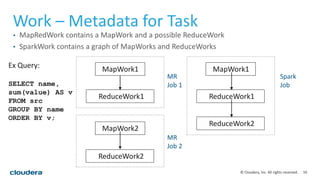


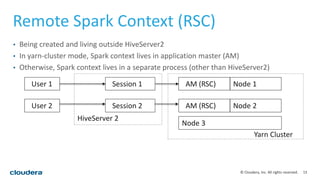


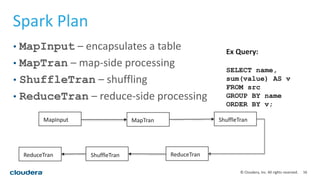










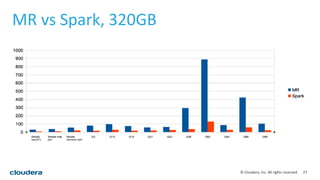
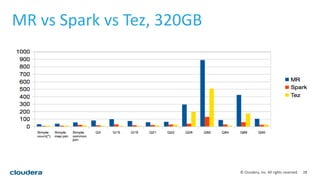
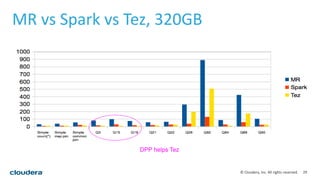

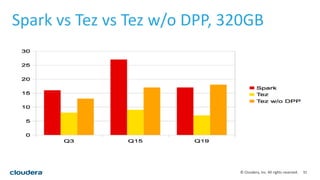
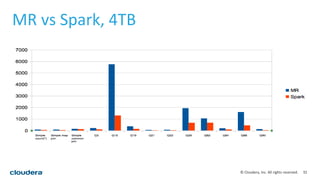
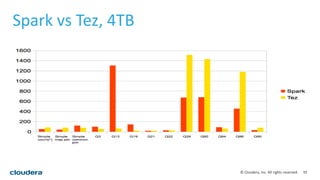
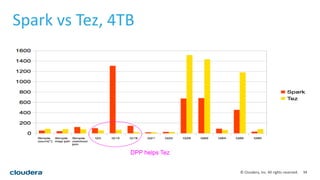
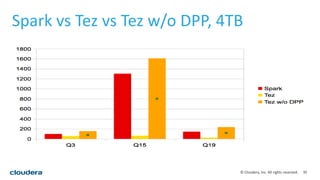
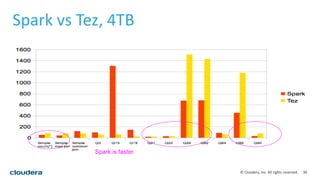
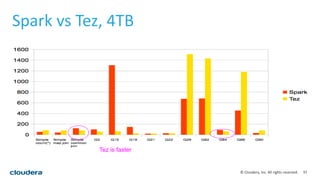



This document discusses empowering Apache Hive with Apache Spark. It provides background on Hive and Spark, outlines the architecture and design principles for integrating the two, discusses challenges, and provides benchmarks comparing performance of Hive on Spark versus Hive on MapReduce and Tez. The key points are: Hive on Spark allows reusing existing Hive code and features while benefiting from Spark's improved performance; efforts involved contributions from both Hive and Spark communities; benchmarks on 320GB and 4TB datasets showed Hive on Spark was sometimes faster than Hive on Tez and significantly faster than Hive on MapReduce, though Tez performance improved with dynamic partition pruning not yet implemented for Hive on Spark.










































































































