Downloaded 42 times




![Which Scale-out Framework ?
[Picture Courtesy: Amir H. Payberah]
● Tuning of Spark internal Parameters
● Tuning of JVM Parameters (Heap size etc..)
● Micro-architecture Level Analysis using Hardware Performance Counters.](https://image.slidesharecdn.com/5aahsanjavedawan-161103184524/85/Spark-Summit-EU-talk-by-Ahsan-Javed-Awan-6-320.jpg)

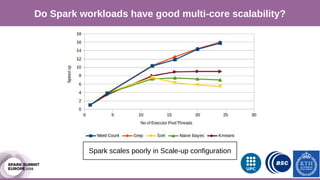
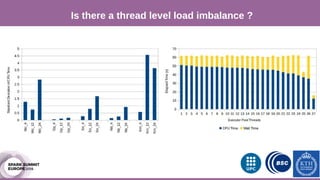
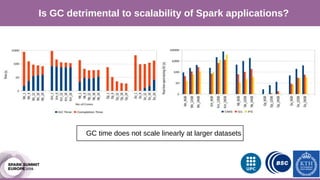
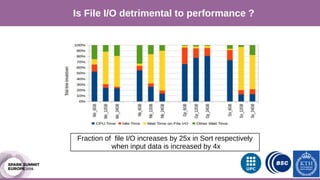

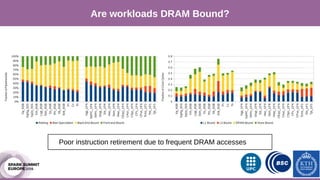
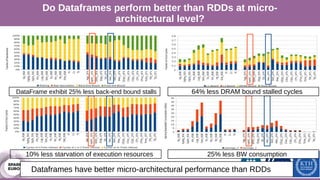
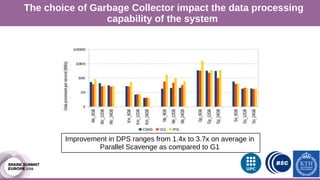
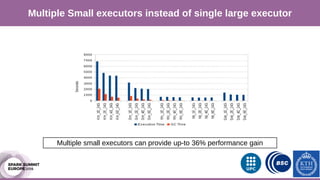
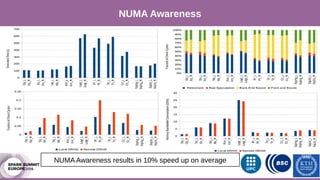
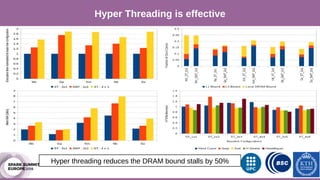

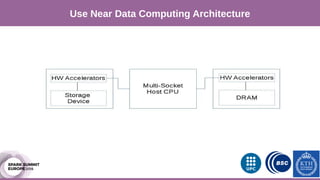

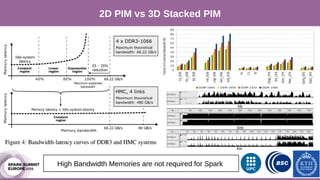
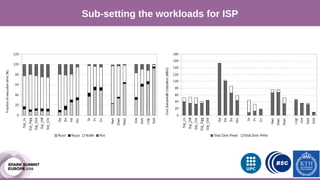





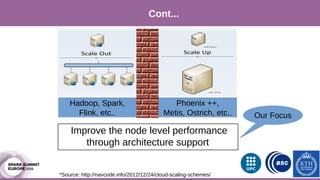
The document discusses performance characterization of in-memory data analytics using Apache Spark on a scale-up server. It identifies problems like poor multicore scalability, thread load imbalance, I/O wait times, and GC overhead. Solutions proposed include NUMA awareness, hyperthreading, disabling next-line prefetchers, using parallel scavenge GC, multiple small executors, and a future node architecture based on a hybrid in-storage processing and 2D processing-in-memory design. The work aims to improve node-level performance through architecture support for emerging big data workloads.





































































































