Download as PDF, PPTX




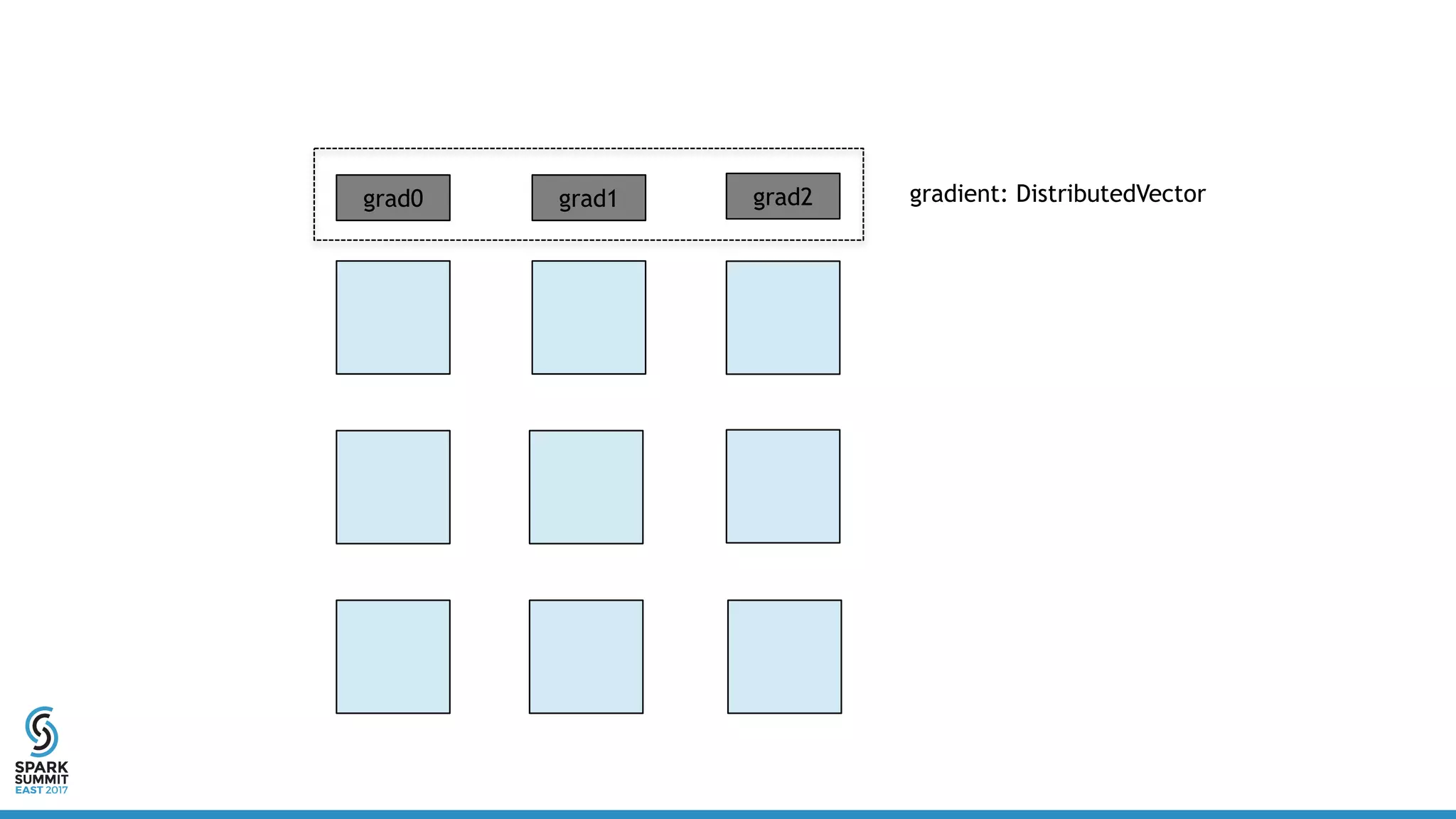
![Distributed Vector
Driver
[2.5, 6.8, 3.1, 9.0, 0.7, 1.9, 2.6, 8.7, 6.2, 1.1, 5.0, 0.0]
worker0 worker1 worker2 worker3](https://image.slidesharecdn.com/5302yanboliang-170215231221/75/Scaling-Apache-Spark-MLlib-to-Billions-of-Parameters-Spark-Summit-East-talk-by-Yanbo-Liang-13-2048.jpg)
![Distributed Vector
Driver
[2.5, 6.8, 3.1, 9.0, 0.7, 1.9, 2.6, 8.7, 6.2, 1.1, 5.0, 0.0]
[2.5, 6.8, 3.1]
worker0
[9.0, 0.7, 1.9]
worker1
[2.6, 8.7, 6.2]
worker2
[1.1, 5.0, 0.0]
worker3](https://image.slidesharecdn.com/5302yanboliang-170215231221/75/Scaling-Apache-Spark-MLlib-to-Billions-of-Parameters-Spark-Summit-East-talk-by-Yanbo-Liang-14-2048.jpg)
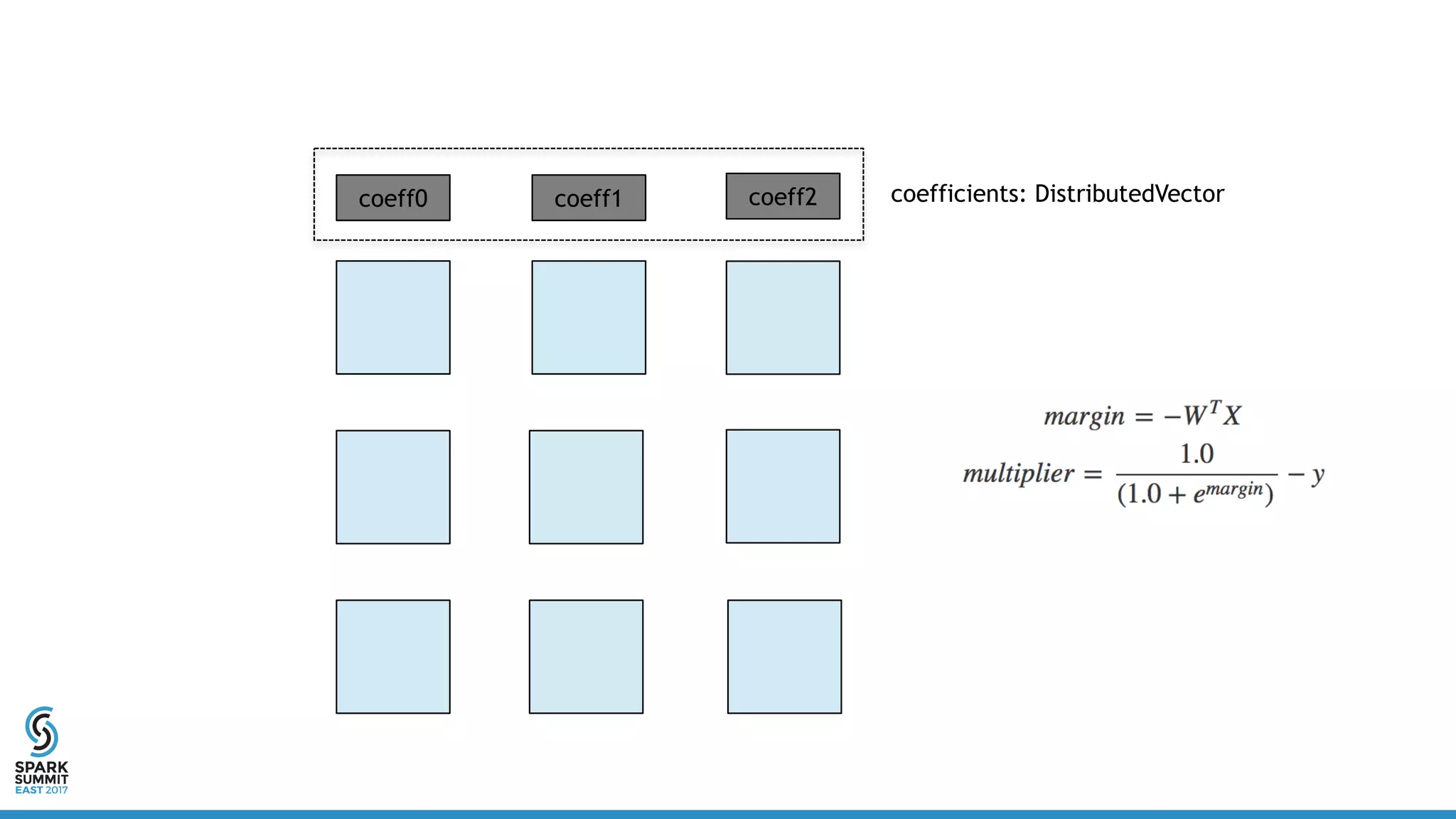
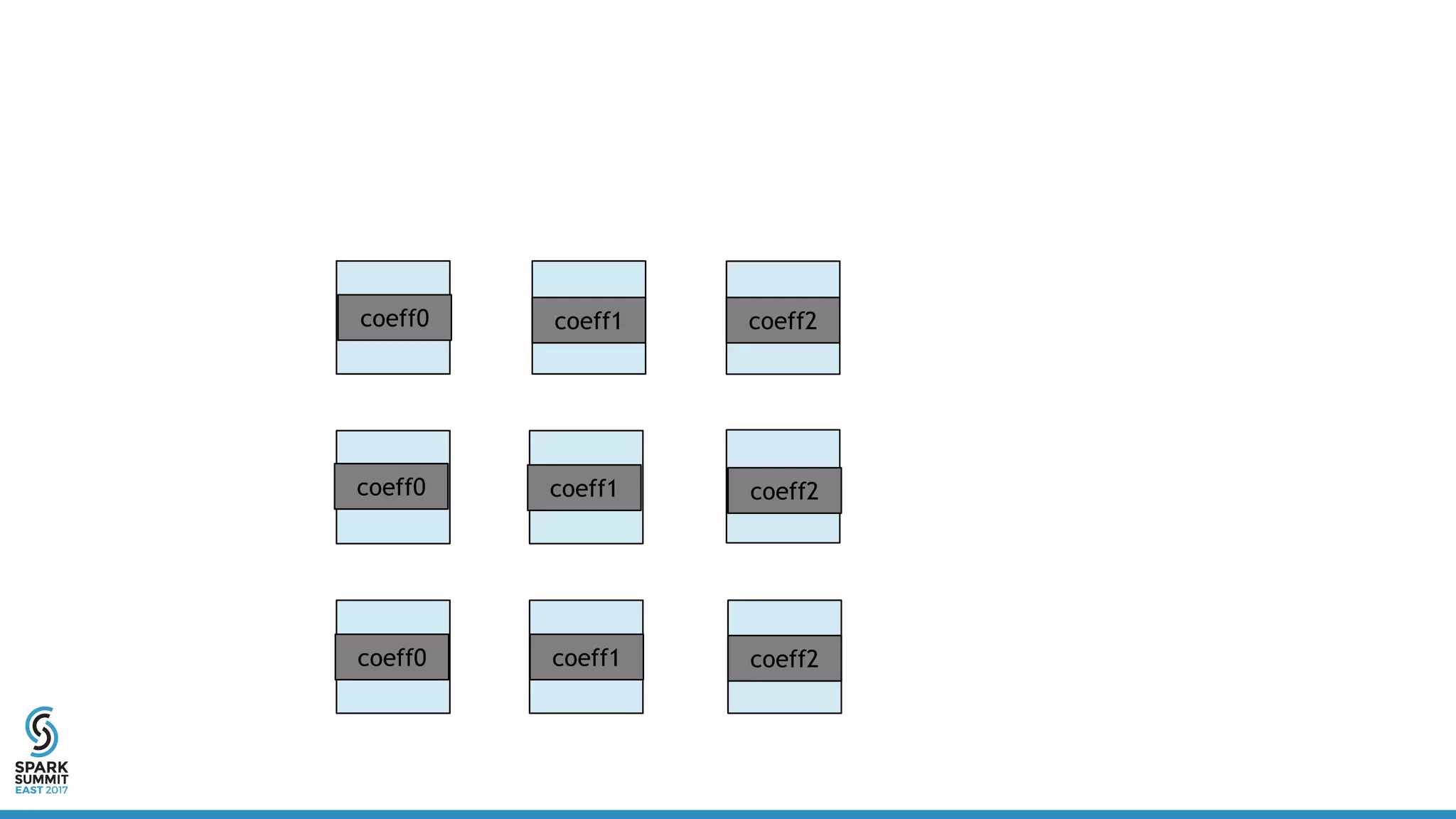
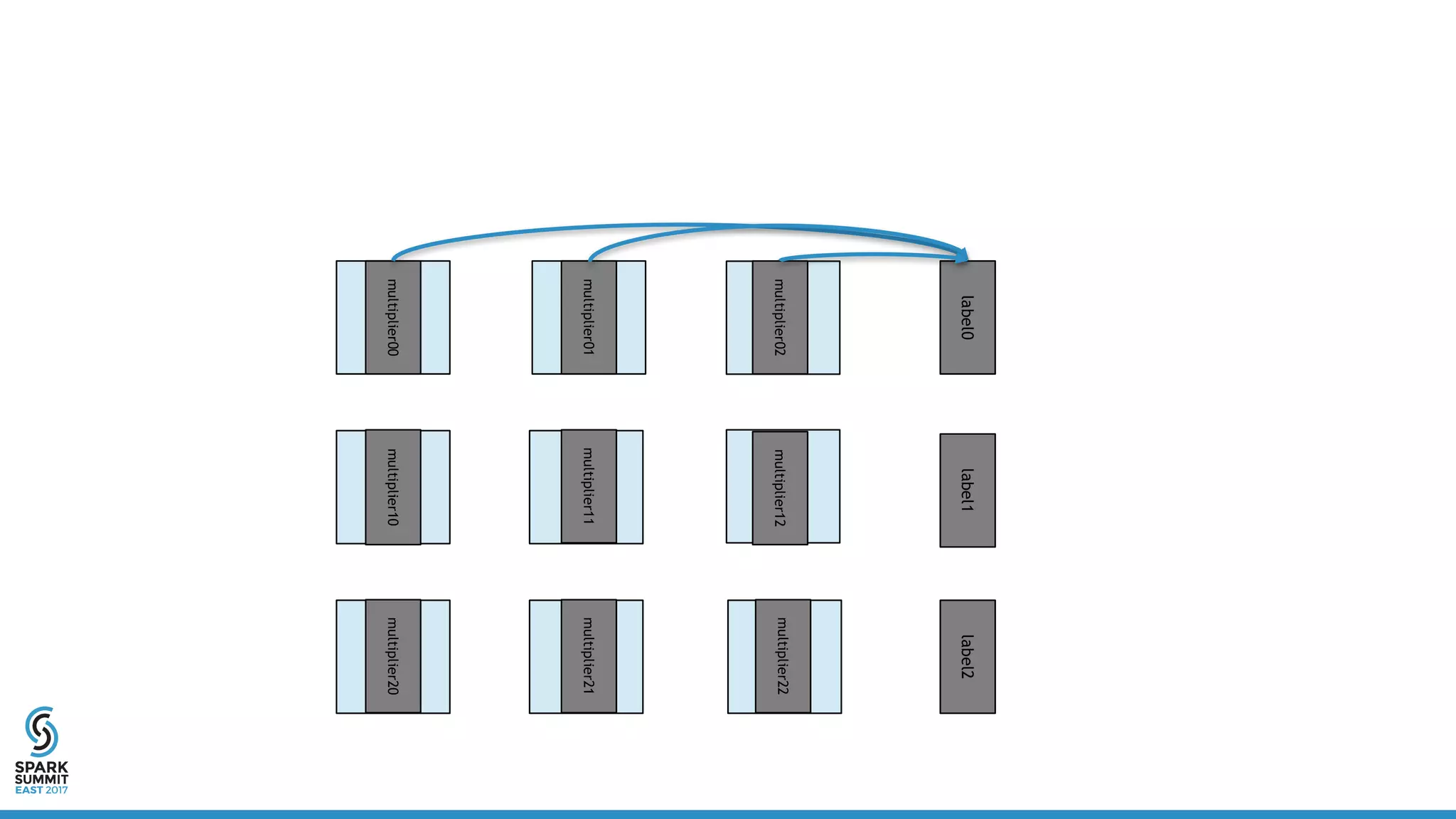
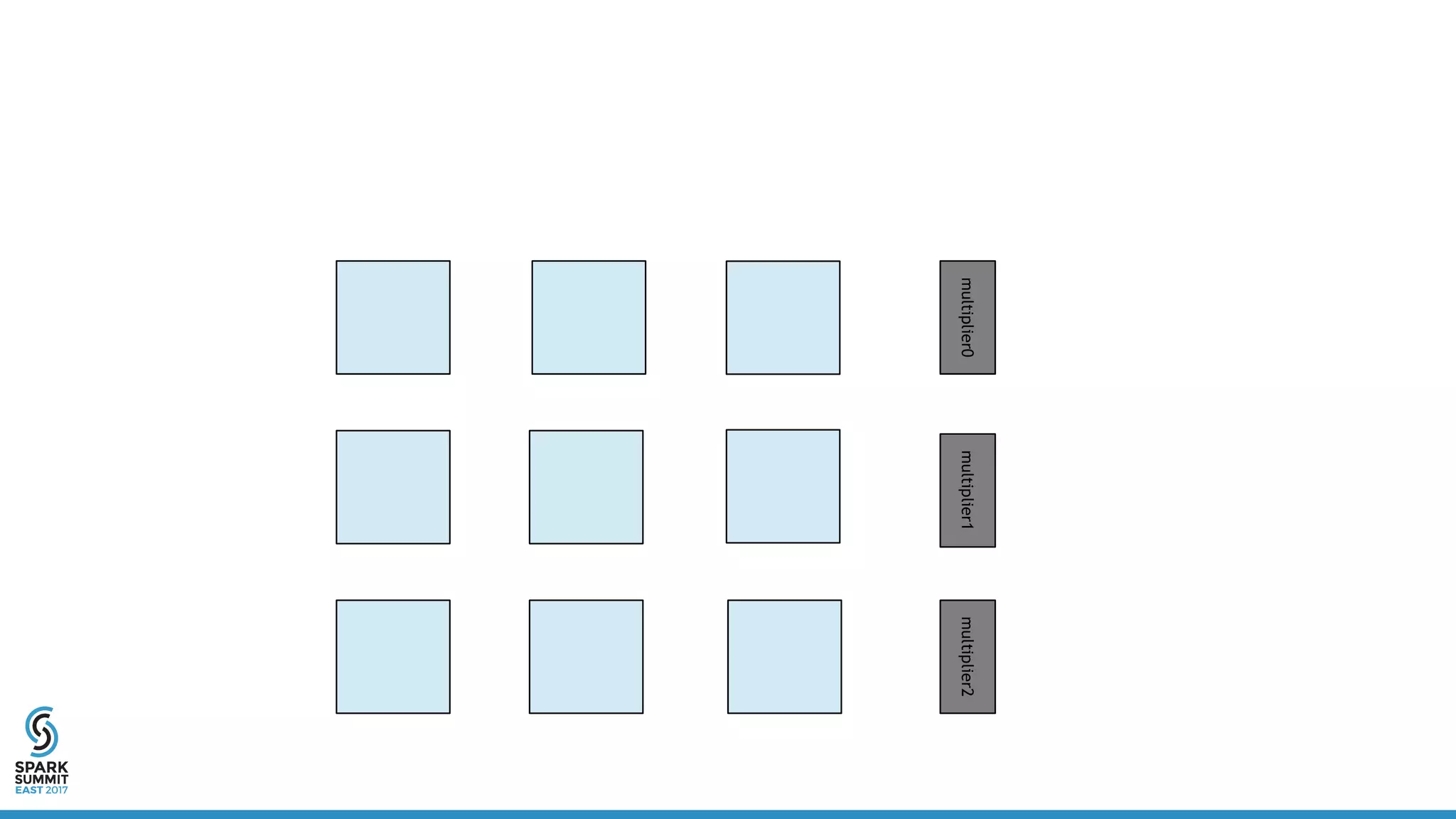
![Distributed Vector
• Definition:
• Linear algebra operations:
– a * x + y
– a * x + b * y + c * z + …
– x.dot(y)
– x.norm
– …
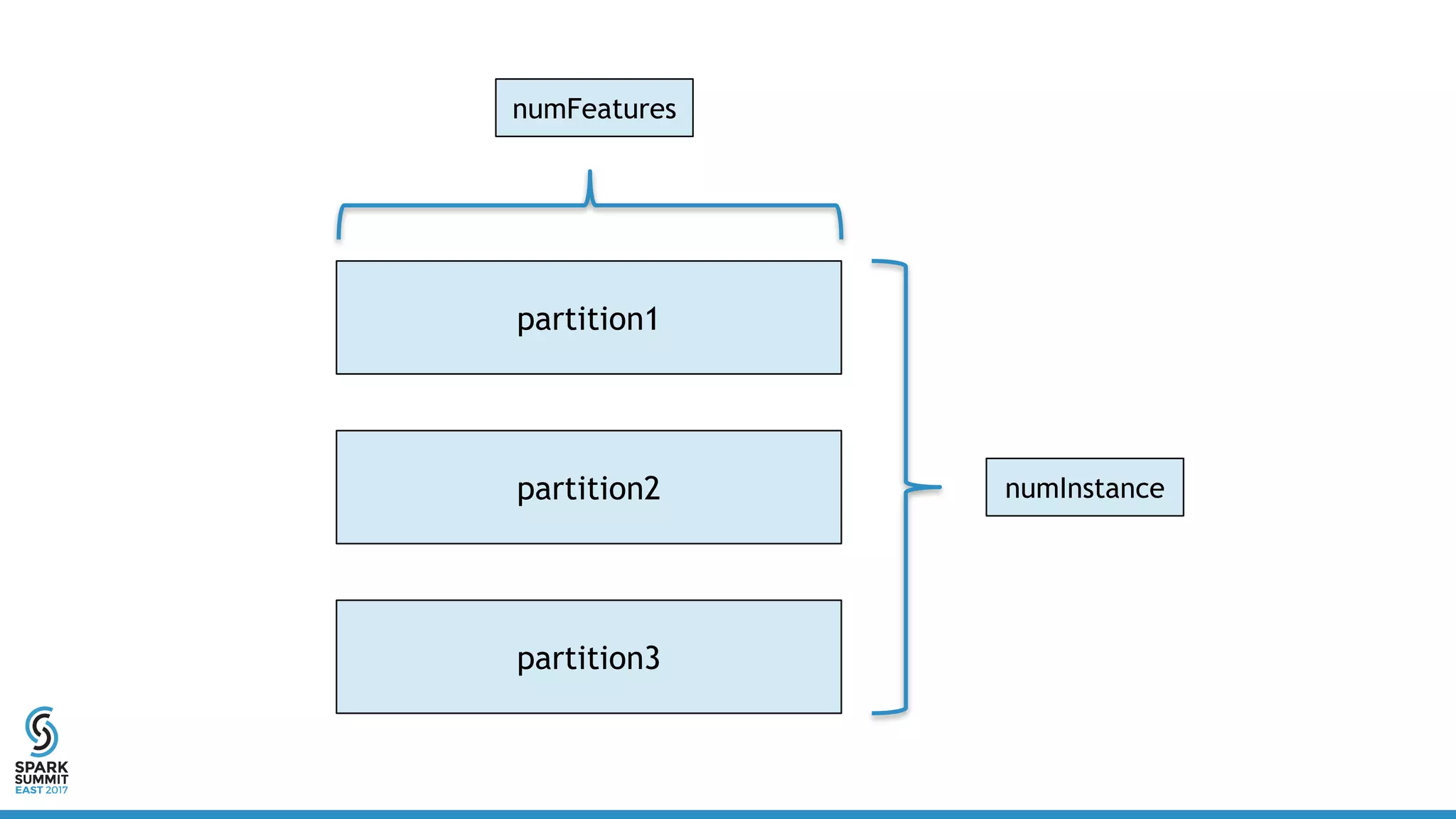
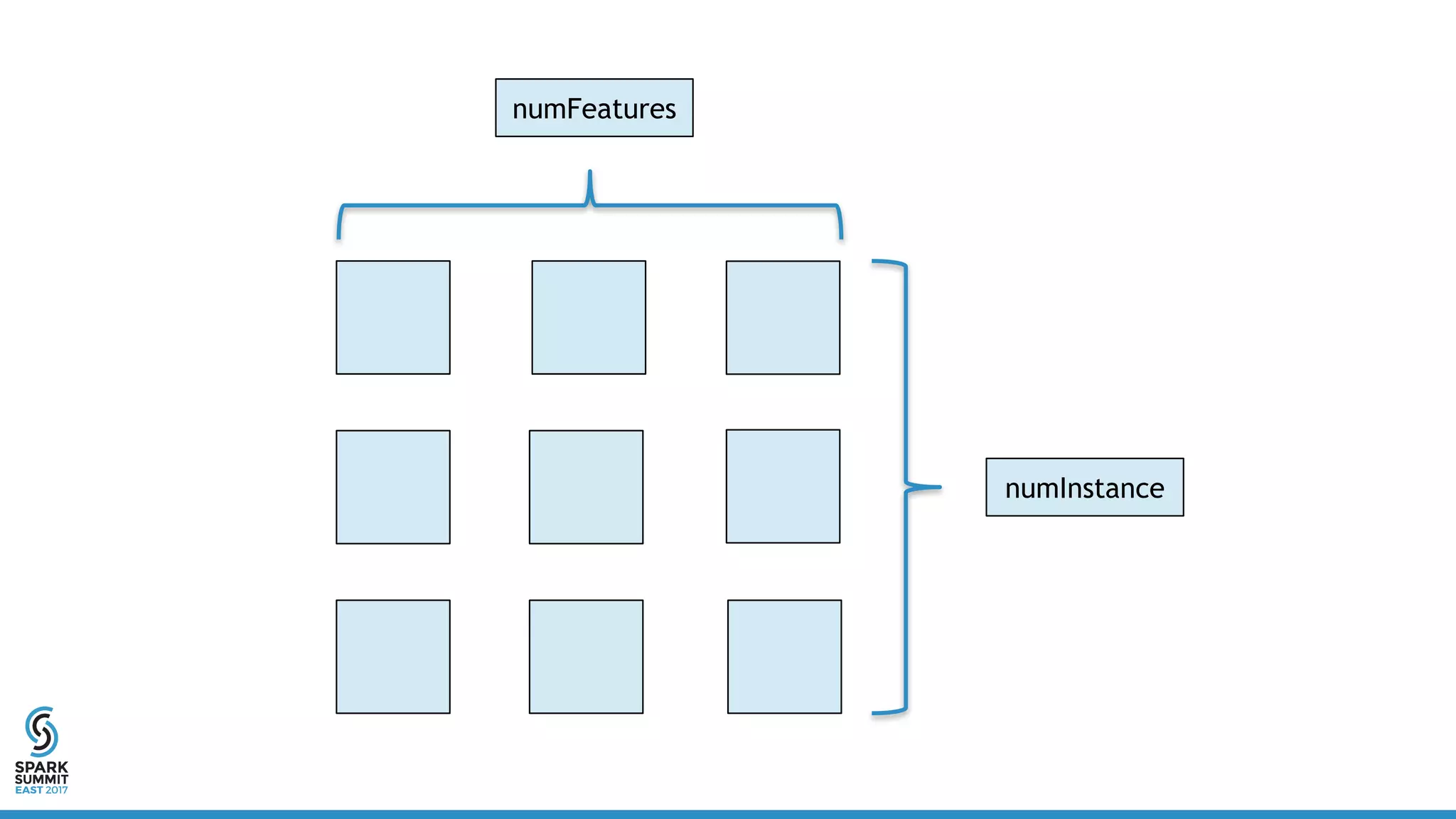
class DistribuedVector(
val values: RDD[Vector],
val sizePerPart: Int,
val numPartitions: Int,
val size: Long)](https://image.slidesharecdn.com/5302yanboliang-170215231221/75/Scaling-Apache-Spark-MLlib-to-Billions-of-Parameters-Spark-Summit-East-talk-by-Yanbo-Liang-15-2048.jpg)





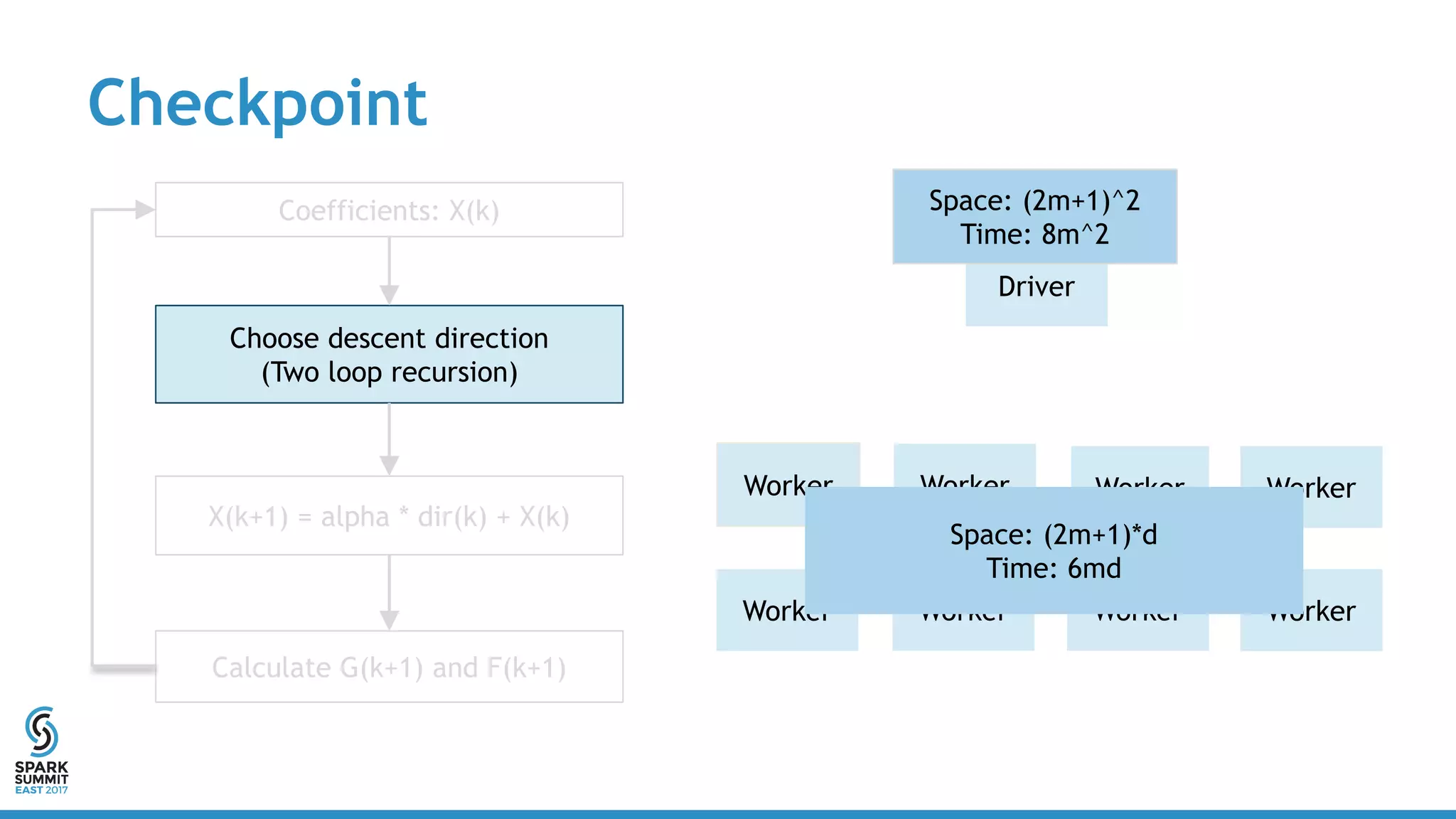


![APIs
val dataset: Dataset[_] =
spark.read.format("libsvm").load("data/a9a")
val trainer = new VLogisticRegression()
.setColsPerBlock(100)
.setRowsPerBlock(10)
.setColPartitions(3)
.setRowPartitions(3)
.setRegParam(0.5)
val model = trainer.fit(dataset)
println(s"Vector-free logistic regression coefficients:
${model.coefficients}")](https://image.slidesharecdn.com/5302yanboliang-170215231221/75/Scaling-Apache-Spark-MLlib-to-Billions-of-Parameters-Spark-Summit-East-talk-by-Yanbo-Liang-36-2048.jpg)

![APIs
val dataset: Dataset[_] =
spark.read.format("libsvm").load("data/a9a")
val trainer = new LogisticRegression()
.setColsPerBlock(100)
.setRowsPerBlock(10)
.setColPartitions(3)
.setRowPartitions(3)
.setRegParam(0.5)
.setSolver(“vl-bfgs”)
val model = trainer.fit(dataset)
println(s"Vector-free logistic regression coefficients:
${model.coefficients}")](https://image.slidesharecdn.com/5302yanboliang-170215231221/75/Scaling-Apache-Spark-MLlib-to-Billions-of-Parameters-Spark-Summit-East-talk-by-Yanbo-Liang-39-2048.jpg)





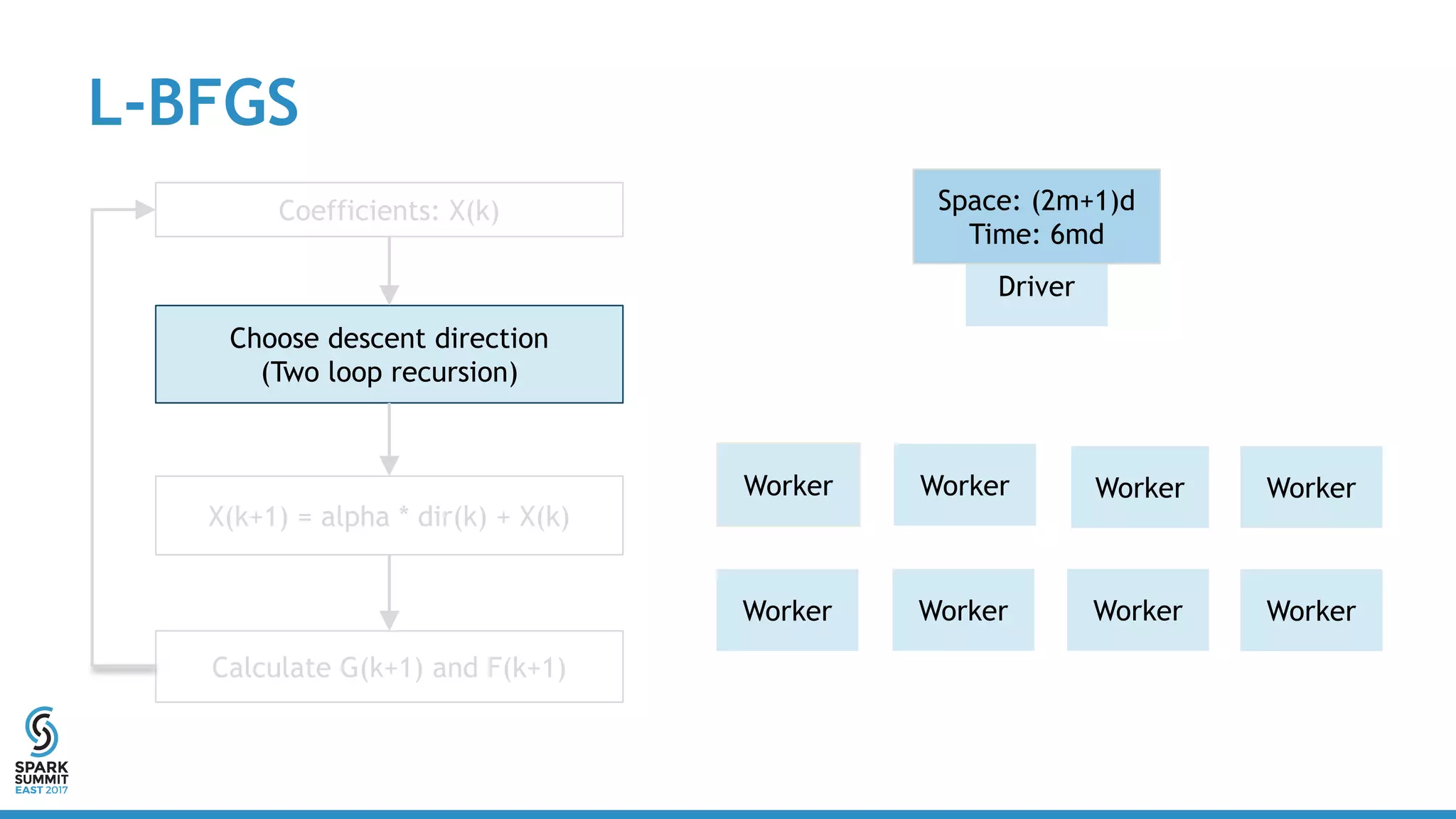
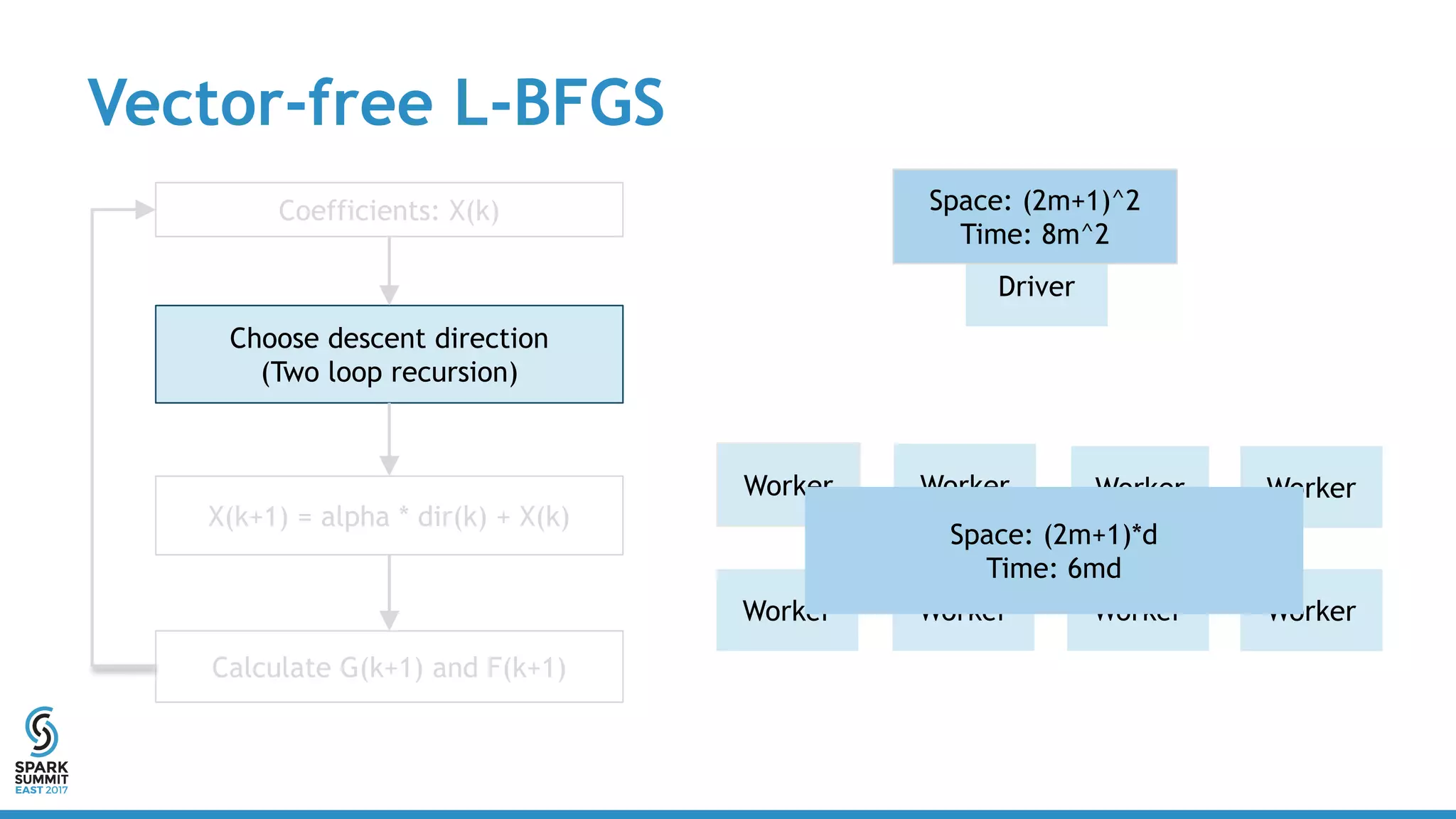
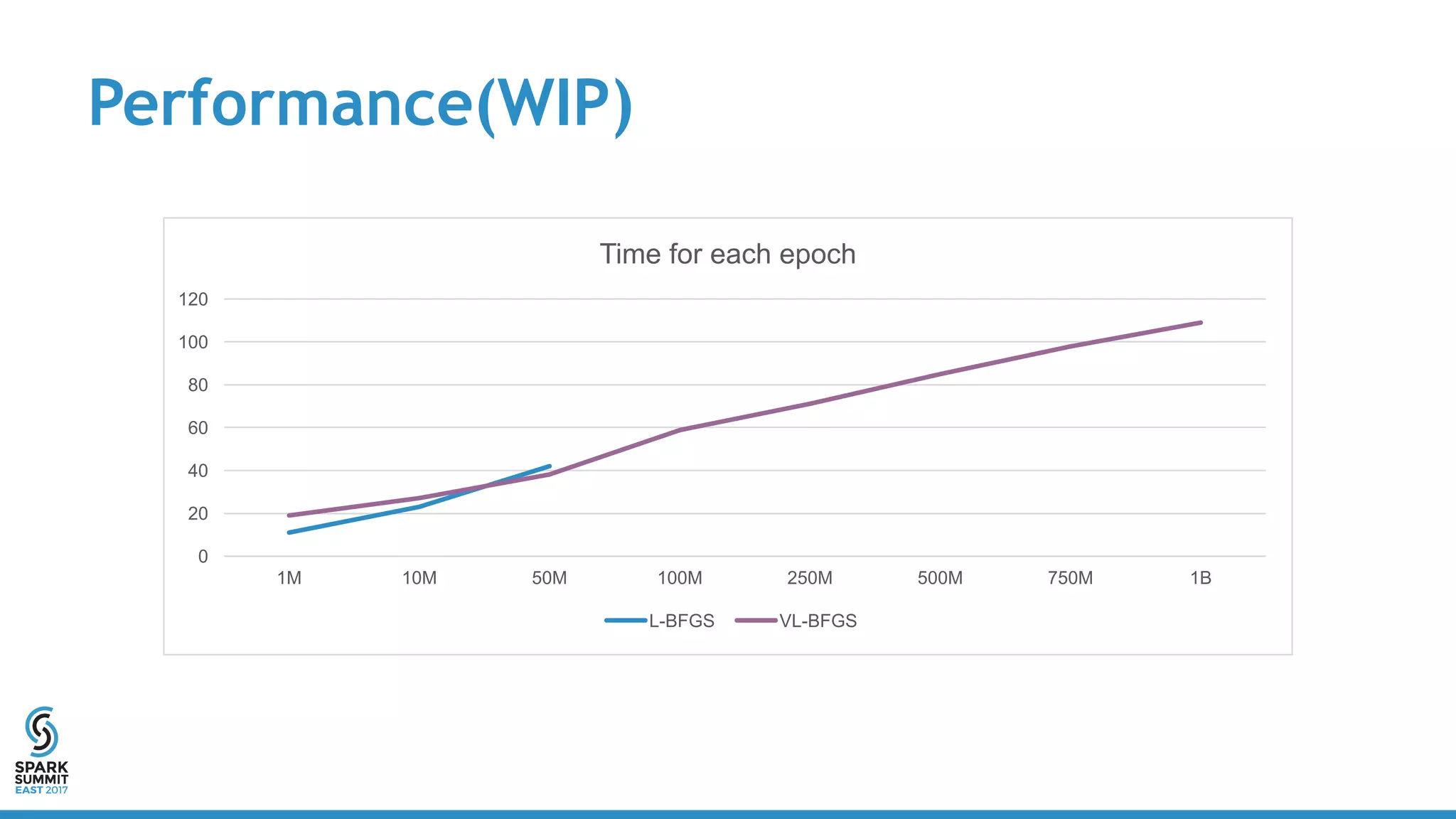
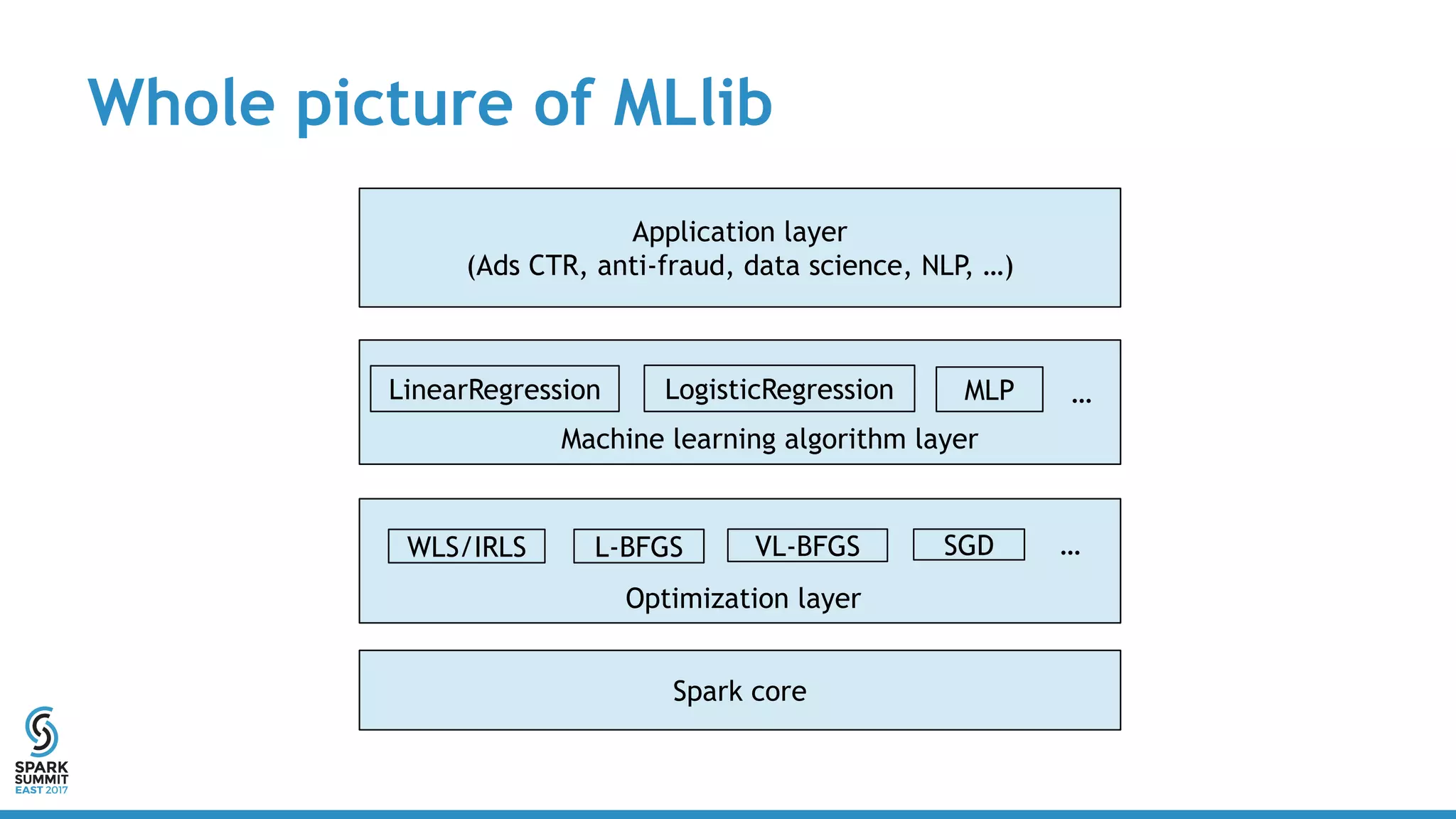
The document discusses scaling Apache Spark's MLlib to handle billions of parameters using a vector-free L-BFGS algorithm for logistic regression. It outlines performance metrics, integration with existing MLlib, and future work opportunities while emphasizing a full distributed computation model without requiring special resources. Key takeaways include the API consistency with Breeze L-BFGS and its deployment ease within Spark clusters.























































































