Downloaded 192 times









![11© Cloudera, Inc. All rights reserved.
Tables and tablets
• Each table is horizontally partitioned into tablets
• Range or hash partitioning
• PRIMARY KEY (host, metric, timestamp) DISTRIBUTE BY
HASH(timestamp) INTO 100 BUCKETS
• Translation: bucketNumber = hashCode(row[‘timestamp’]) % 100
• Each tablet has N replicas (3 or 5), kept consistent with Raft consensus
• Tablet servers host tablets on local disk drives](https://image.slidesharecdn.com/4gmikepercy-161103202314/85/Spark-Summit-EU-talk-by-Mike-Percy-11-320.jpg)








![20© Cloudera, Inc. All rights reserved.
Spark DataSource optimizations
Column projection and predicate pushdown
- Only read the referenced columns
- Convert ‘WHERE’ clauses into Kudu predicates
- Kudu predicates automatically convert to primary key scans, etc
scala> sqlContext.sql("select avg(value) from metrics where host =
'e1103.halxg.cloudera.com'").explain
== Physical Plan ==
TungstenAggregate(key=[], functions=[(avg(value#3),mode=Final,isDistinct=false)], output=[_c0#94])
+- TungstenExchange SinglePartition, None
+- TungstenAggregate(key=[], functions=[(avg(value#3),mode=Partial,isDistinct=false)],
output=[sum#98,count#99L])
+- Project [value#3]
+- Scan org.apache.kudu.spark.kudu.KuduRelation@e13cc49[value#3]
PushedFilters: [EqualTo(host,e1103.halxg.cloudera.com)]](https://image.slidesharecdn.com/4gmikepercy-161103202314/85/Spark-Summit-EU-talk-by-Mike-Percy-20-320.jpg)




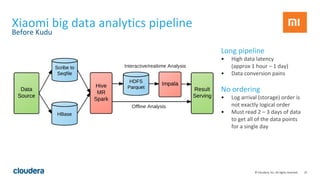
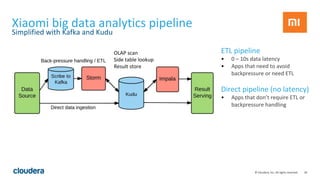
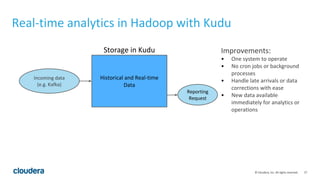

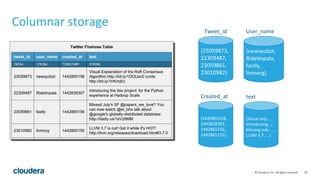
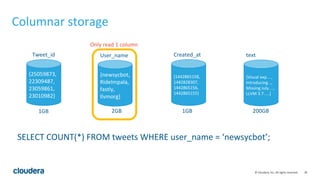








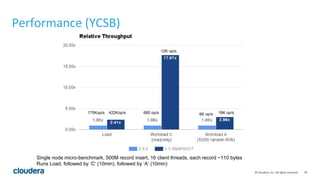

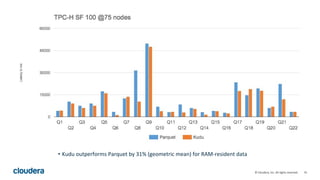





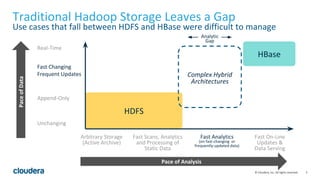
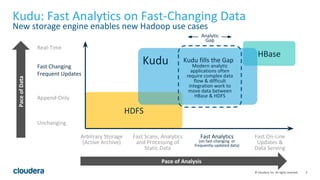
The document discusses Apache Kudu, an open source storage layer for Apache Hadoop that enables fast analytics on fast data. Kudu is designed to fill the gap between HDFS and HBase by providing fast analytics capabilities on fast-changing or frequently updated data. It achieves this through its scalable and fast tabular storage design that allows for both high insert/update throughput and fast scans/queries. The document provides an overview of Kudu's architecture and capabilities, examples of how to use its NoSQL and SQL APIs, and real-world use cases like enabling low-latency analytics pipelines for companies like Xiaomi.











































































































