



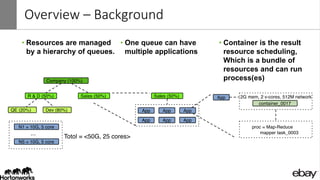
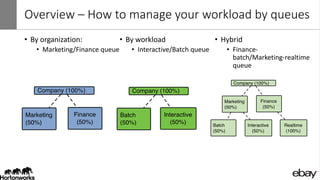


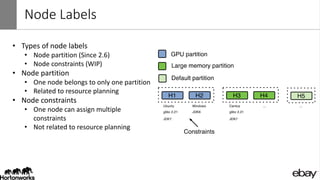
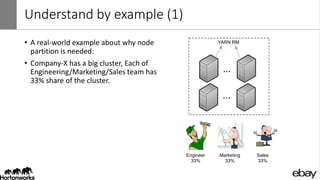
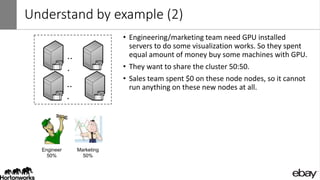
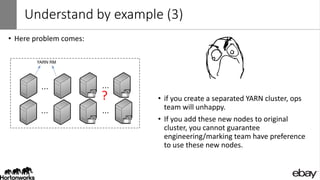
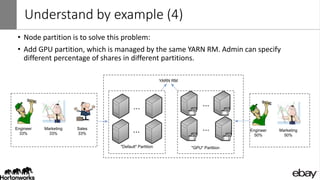
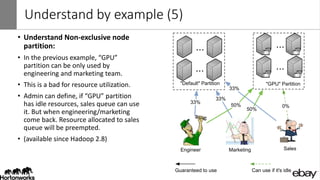
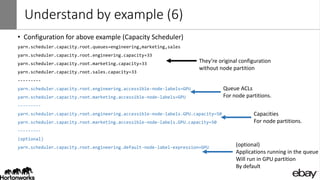
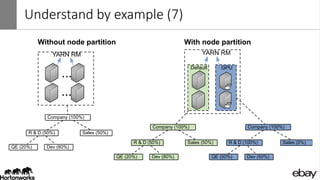
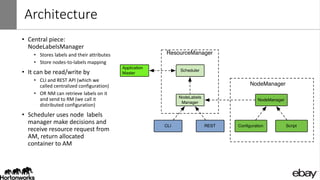


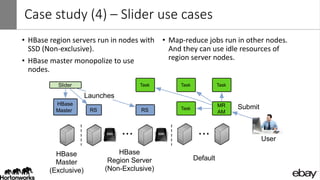

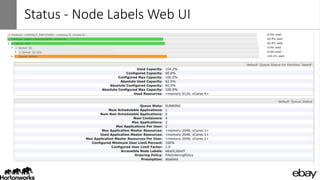




Wangda Tan and Mayank Bansal presented on YARN Node Labels. Node labels allow grouping nodes with similar hardware or software profiles. This allows applications to request specific nodes and improves cluster partitioning and resource management. Key features include exclusive and non-exclusive node partitions, centralized and distributed configuration, and support in projects like Spark, MapReduce, Slider, and Ambari. Future work includes adding node constraints and supporting node labels in other schedulers like FairScheduler. Node labels help optimize cluster resource utilization and isolate workloads.










































































































