Downloaded 68 times



















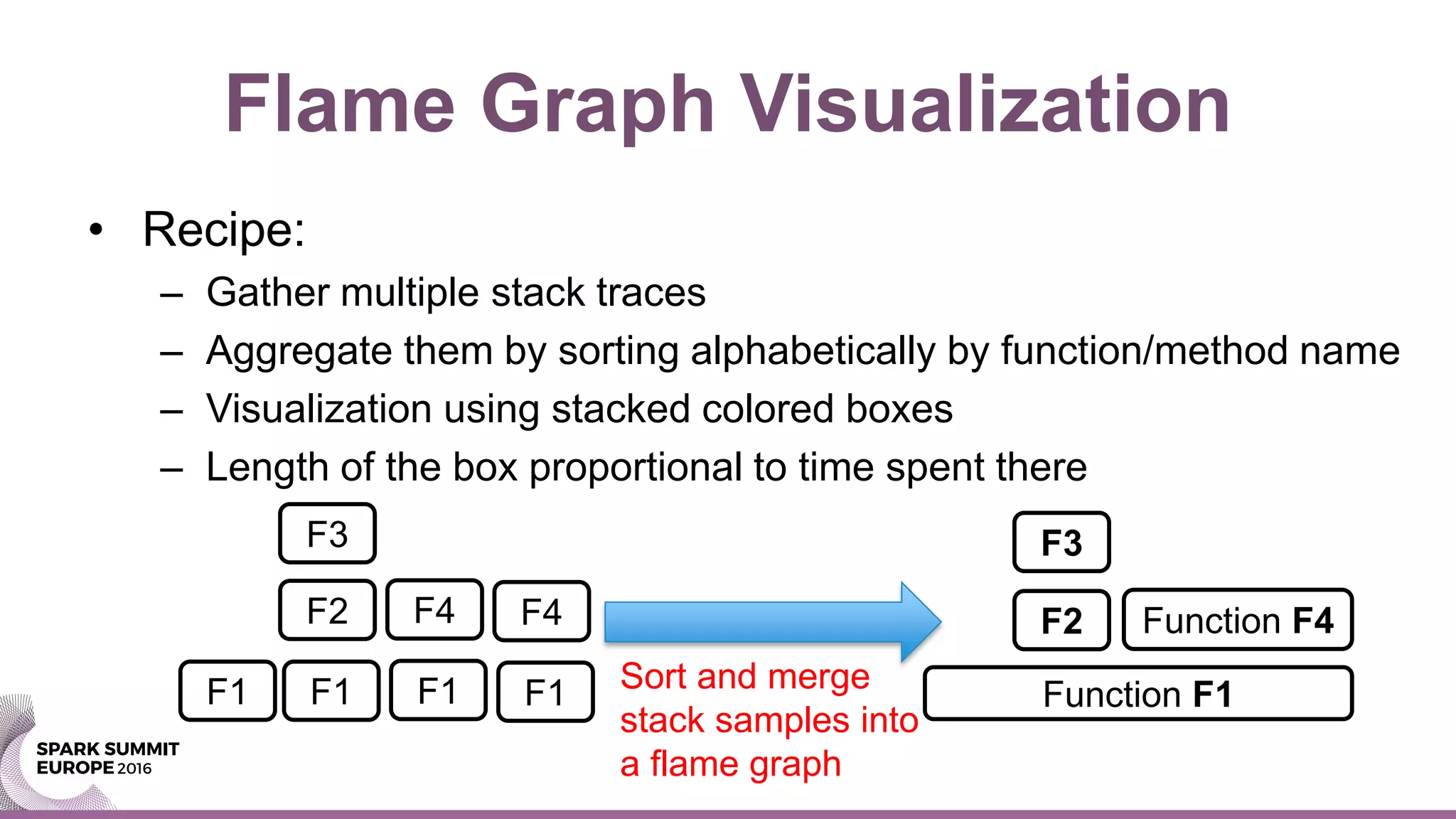















Luca Canali presented on using flame graphs to investigate performance improvements in Spark 2.0 over Spark 1.6 for a CPU-intensive workload. Flame graphs of the Spark 1.6 and 2.0 executions showed Spark 2.0 spending less time in core Spark functions and more time in whole stage code generation functions, indicating improved optimizations. Additional tools like Linux perf confirmed Spark 2.0 utilized CPU and memory throughput better. The presentation demonstrated how flame graphs and other profiling tools can help pinpoint performance bottlenecks and understand the impact of changes like Spark 2.0's code generation optimizations.



























































































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)



