Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Katsuya Ito
PDF, PPTX
3,107 views
異常検知と変化検知で復習するPRML
MLPシリーズの赤い本異常検知と変化検知で、 パターン認識と機械学習を復習します。 ホテリングのt2・ナイーブベイズ・kNN・SVM・混合分布・ガウス過程などを復習します。
Engineering
◦
Read more
8
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 56
2
/ 56
3
/ 56
4
/ 56
5
/ 56
6
/ 56
7
/ 56
8
/ 56
9
/ 56
10
/ 56
11
/ 56
12
/ 56
13
/ 56
14
/ 56
15
/ 56
16
/ 56
17
/ 56
18
/ 56
19
/ 56
20
/ 56
21
/ 56
22
/ 56
23
/ 56
24
/ 56
25
/ 56
26
/ 56
27
/ 56
28
/ 56
29
/ 56
30
/ 56
31
/ 56
32
/ 56
33
/ 56
34
/ 56
35
/ 56
36
/ 56
37
/ 56
38
/ 56
39
/ 56
40
/ 56
41
/ 56
42
/ 56
43
/ 56
44
/ 56
45
/ 56
46
/ 56
47
/ 56
48
/ 56
49
/ 56
50
/ 56
51
/ 56
52
/ 56
53
/ 56
54
/ 56
55
/ 56
56
/ 56
More Related Content
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
時系列分析による異常検知入門
by
Yohei Sato
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
深層生成モデルと世界モデル
by
Masahiro Suzuki
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
GAN(と強化学習との関係)
by
Masahiro Suzuki
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
時系列分析による異常検知入門
by
Yohei Sato
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
What's hot
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
PDF
AutoEncoderで特徴抽出
by
Kai Sasaki
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
「世界モデル」と関連研究について
by
Masahiro Suzuki
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
PDF
Variational AutoEncoder
by
Kazuki Nitta
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
近年のHierarchical Vision Transformer
by
Yusuke Uchida
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
AutoEncoderで特徴抽出
by
Kai Sasaki
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
「世界モデル」と関連研究について
by
Masahiro Suzuki
グラフニューラルネットワーク入門
by
ryosuke-kojima
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
機械学習モデルの判断根拠の説明
by
Satoshi Hara
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
Variational AutoEncoder
by
Kazuki Nitta
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
Bayesian Neural Networks : Survey
by
tmtm otm
Similar to 異常検知と変化検知で復習するPRML
PPTX
異常検知と変化検知の1~3章をまとめてみた
by
Takahiro Yoshizawa
PDF
単純ベイズ法による異常検知 #ml-professional
by
Ai Makabi
PDF
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
PDF
Prml 10 1
by
正志 坪坂
PPTX
PRML4.3
by
hiroki yamaoka
PDF
R実践 機械学習による異常検知 02
by
akira_11
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
Anomaly detection survey
by
ぱんいち すみもと
PPT
ma92007id395
by
matsushimalab
PDF
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
PDF
PRML 6.4-6.5
by
正志 坪坂
PPTX
DLLab 異常検知ナイト 資料 20180214
by
Kosuke Nakago
PDF
[ICLR/ICML2019読み会] Data Interpolating Prediction: Alternative Interpretation ...
by
Takuya Shimada
PPTX
【招待講演】パラメータ制約付き行列分解のベイズ汎化誤差解析【StatsML若手シンポ2020】
by
Naoki Hayashi
PDF
Oshasta em
by
Naotaka Yamada
PDF
パターン認識 04 混合正規分布
by
sleipnir002
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PDF
クラシックな機械学習の入門 4. 学習データと予測性能
by
Hiroshi Nakagawa
異常検知と変化検知の1~3章をまとめてみた
by
Takahiro Yoshizawa
単純ベイズ法による異常検知 #ml-professional
by
Ai Makabi
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
Prml 10 1
by
正志 坪坂
PRML4.3
by
hiroki yamaoka
R実践 機械学習による異常検知 02
by
akira_11
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
Anomaly detection survey
by
ぱんいち すみもと
ma92007id395
by
matsushimalab
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
PRML 6.4-6.5
by
正志 坪坂
DLLab 異常検知ナイト 資料 20180214
by
Kosuke Nakago
[ICLR/ICML2019読み会] Data Interpolating Prediction: Alternative Interpretation ...
by
Takuya Shimada
【招待講演】パラメータ制約付き行列分解のベイズ汎化誤差解析【StatsML若手シンポ2020】
by
Naoki Hayashi
Oshasta em
by
Naotaka Yamada
パターン認識 04 混合正規分布
by
sleipnir002
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
クラシックな機械学習の入門 4. 学習データと予測性能
by
Hiroshi Nakagawa
More from Katsuya Ito
PDF
ICML2021の連合学習の論文
by
Katsuya Ito
PDF
金融時系列解析入門 AAMAS2021 著者発表会
by
Katsuya Ito
PDF
西山計量経済学第8章 制限従属変数モデル
by
Katsuya Ito
PDF
CF-FinML 金融時系列予測のための機械学習
by
Katsuya Ito
PDF
非同期時系列のLead-lag効果推定のための新しい推定量
by
Katsuya Ito
PDF
表明保証と補償責任
by
Katsuya Ito
PDF
Gali3章Monetary Policy, Inflation, and the Business Cycle~the basic new keynes...
by
Katsuya Ito
PDF
新問題研究 要件事実
by
Katsuya Ito
PDF
Dynamic Time Warping を用いた高頻度取引データのLead-Lag 効果の推定
by
Katsuya Ito
PDF
Convex Analysis and Duality (based on "Functional Analysis and Optimization" ...
by
Katsuya Ito
PPTX
量子プログラミング入門
by
Katsuya Ito
PDF
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた
by
Katsuya Ito
PDF
ICLR 2018 Best papers 3本を紹介
by
Katsuya Ito
PPTX
計算数学I TA小話①(TeXについて)
by
Katsuya Ito
PPTX
Black-Scholesの面白さ
by
Katsuya Ito
PDF
深層ニューラルネットワークの積分表現(Deepを定式化する数学)
by
Katsuya Ito
PDF
Goodfellow先生おすすめのGAN論文6つを紹介
by
Katsuya Ito
PDF
とぽろじー入門(画像なし版)
by
Katsuya Ito
ICML2021の連合学習の論文
by
Katsuya Ito
金融時系列解析入門 AAMAS2021 著者発表会
by
Katsuya Ito
西山計量経済学第8章 制限従属変数モデル
by
Katsuya Ito
CF-FinML 金融時系列予測のための機械学習
by
Katsuya Ito
非同期時系列のLead-lag効果推定のための新しい推定量
by
Katsuya Ito
表明保証と補償責任
by
Katsuya Ito
Gali3章Monetary Policy, Inflation, and the Business Cycle~the basic new keynes...
by
Katsuya Ito
新問題研究 要件事実
by
Katsuya Ito
Dynamic Time Warping を用いた高頻度取引データのLead-Lag 効果の推定
by
Katsuya Ito
Convex Analysis and Duality (based on "Functional Analysis and Optimization" ...
by
Katsuya Ito
量子プログラミング入門
by
Katsuya Ito
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた
by
Katsuya Ito
ICLR 2018 Best papers 3本を紹介
by
Katsuya Ito
計算数学I TA小話①(TeXについて)
by
Katsuya Ito
Black-Scholesの面白さ
by
Katsuya Ito
深層ニューラルネットワークの積分表現(Deepを定式化する数学)
by
Katsuya Ito
Goodfellow先生おすすめのGAN論文6つを紹介
by
Katsuya Ito
とぽろじー入門(画像なし版)
by
Katsuya Ito
Recently uploaded
PDF
krsk_aws_re-growth_aws_devops_agent_20251211
by
uedayuki
PDF
ソフトとハードの二刀流で実現する先進安全・自動運転のアルゴリズム開発【DENSO Tech Night 第二夜】 ー高精度な画像解析 / AI推論モデル ...
by
dots.
PDF
ソフトウェアエンジニアがクルマのコアを創る!? モビリティの価値を最大化するソフトウェア開発の最前線【DENSO Tech Night 第一夜】
by
dots.
PDF
2025/12/12 AutoDevNinjaピッチ資料 - 大人な男のAuto Dev環境
by
Masahiro Takechi
PDF
音楽アーティスト探索体験に特化した音楽ディスカバリーWebサービス「DigLoop」|Created byヨハク技研
by
yohakugiken
PPTX
君をむしばむこの力で_最終発表-1-Monthon2025最終発表用資料-.pptx
by
rintakano624
krsk_aws_re-growth_aws_devops_agent_20251211
by
uedayuki
ソフトとハードの二刀流で実現する先進安全・自動運転のアルゴリズム開発【DENSO Tech Night 第二夜】 ー高精度な画像解析 / AI推論モデル ...
by
dots.
ソフトウェアエンジニアがクルマのコアを創る!? モビリティの価値を最大化するソフトウェア開発の最前線【DENSO Tech Night 第一夜】
by
dots.
2025/12/12 AutoDevNinjaピッチ資料 - 大人な男のAuto Dev環境
by
Masahiro Takechi
音楽アーティスト探索体験に特化した音楽ディスカバリーWebサービス「DigLoop」|Created byヨハク技研
by
yohakugiken
君をむしばむこの力で_最終発表-1-Monthon2025最終発表用資料-.pptx
by
rintakano624
異常検知と変化検知で復習するPRML
1.
異常検知と変化検知 で 復習するPRML 2018/06/10 Katsuya ITO @UT
2.
目次 1. 異常検知の基本 2. ホテリングのT2法 3.
ナイーブベイズ法 4. 近傍法 5. 混合分布モデル 6. SVM 7. ガウス過程
3.
Chapter 1 異常検知・変化検知の基本 異常検知の定義・異常検知をする方法・異常検知機の評価方法について
4.
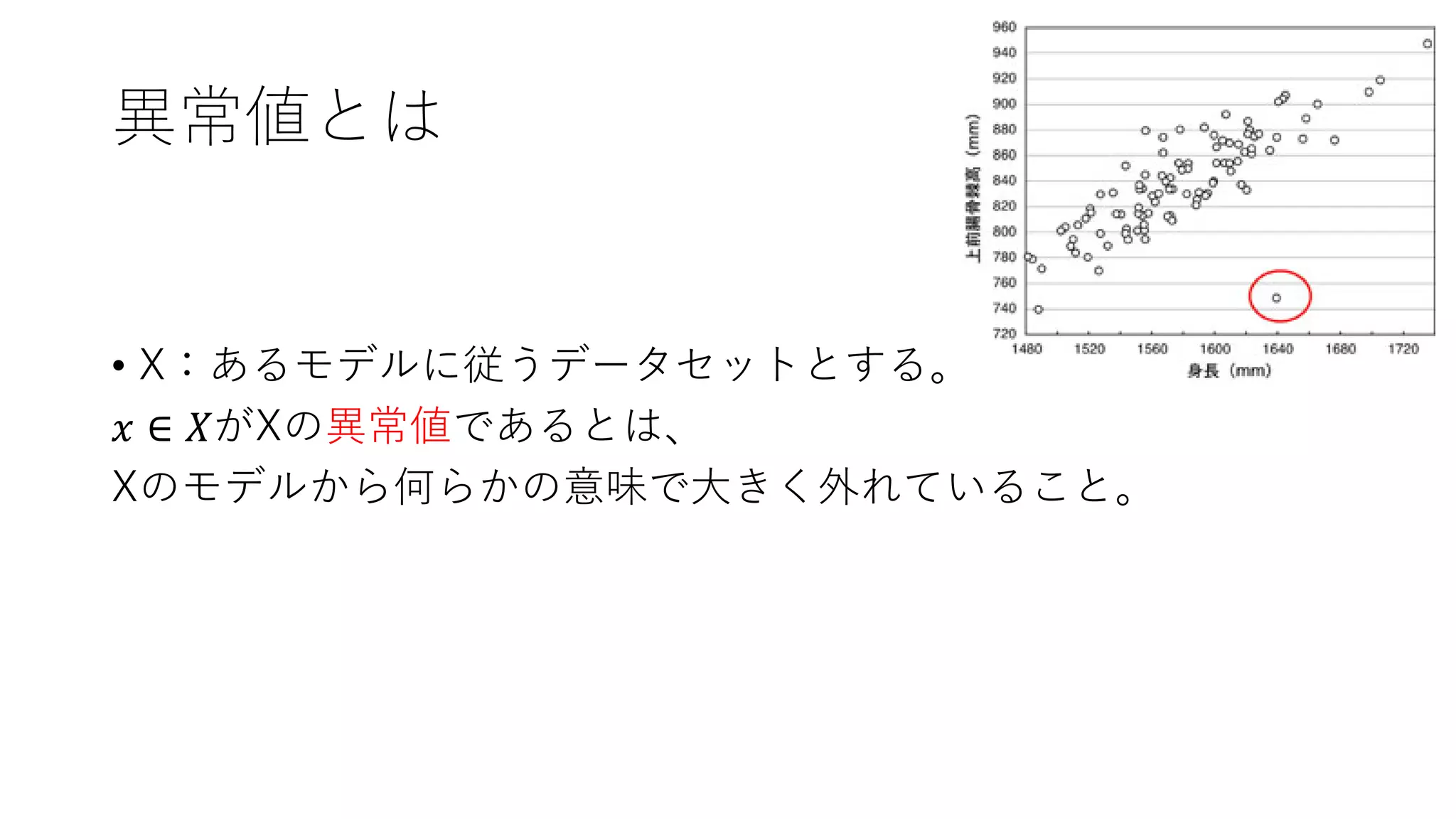
異常値とは • X:あるモデルに従うデータセットとする。 𝑥 ∈
𝑋がXの異常値であるとは、 Xのモデルから何らかの意味で大きく外れていること。
5.
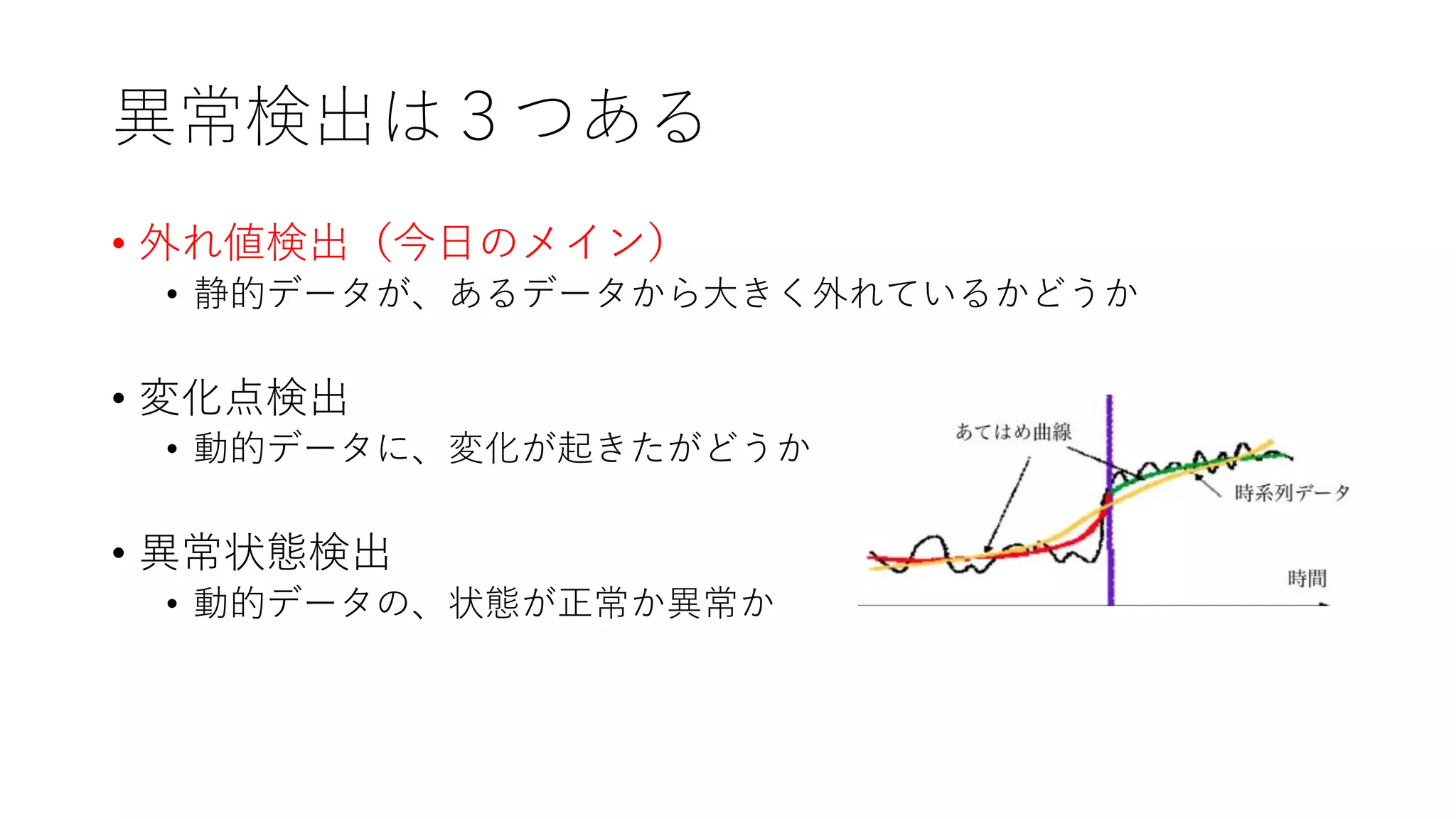
異常検出は3つある • 外れ値検出(今日のメイン) • 静的データが、あるデータから大きく外れているかどうか •
変化点検出 • 動的データに、変化が起きたがどうか • 異常状態検出 • 動的データの、状態が正常か異常か
6.
参考 https://www.slideshare.net/yokkuns/ss-8425312
7.
異常値検出の流れ • ①データセットXを得る • ②データセットXが従うモデルpを確定する •
分布の決定・分布のパラメータ推定 • ③データ点xがpにおいてどれだけ外れているかを計算 • =異常度
8.
異常度はどうやって計算すればいいのか • ①データセットXを得る • ②データセットXが従うモデルpを確定する •
分布の決定・分布のパラメータ推定 • ③データ点xがpにおいてどれだけ外れているかを計算
9.
異常度の計算法(教師あり) • データセット 𝐷
= 𝑥1, 𝑦1 , 𝑥2, 𝑦2 , … , 𝑥 𝑛, 𝑦𝑛 • 𝑥𝑖が異常であるとき𝑦𝑖 = 1 • 𝑥𝑖が異常でないとき𝑦𝑖 = 0 • が与えられたときに、点xの異常値かどうか ln 𝑝 𝑥 𝑦 = 1, 𝐷 𝑝 𝑥 𝑦 = 0, 𝐷 が閾値を超えたらy=1と判断する
10.
異常度の計算法(教師なし) • データセット 𝐷
= 𝑥1, 𝑥2, … , 𝑥 𝑛 が与えられたときに、点xの異常値かどうか −ln 𝑝(𝑥|𝐷) が閾値を超えたら異常値と判断する
11.
異常検出器の評価方法 異常を検出できるか・できないかが図りたい。 • ① 正常標本精度 =誤報しなかった確率=#{正常かつ正常と判断}/#{正常} •
② 異常標本精度 =正確に異常検出できた確率=#{異常かつ異常と判断}/#{異常} • ③ ROC曲線 閾値を動かし(誤報確率,正常検出確率)をプロットしたときの曲線 (の下の面積=AUCが大きいほど良い)
12.
わかりにくいので例 ※PyTorchではない
13.
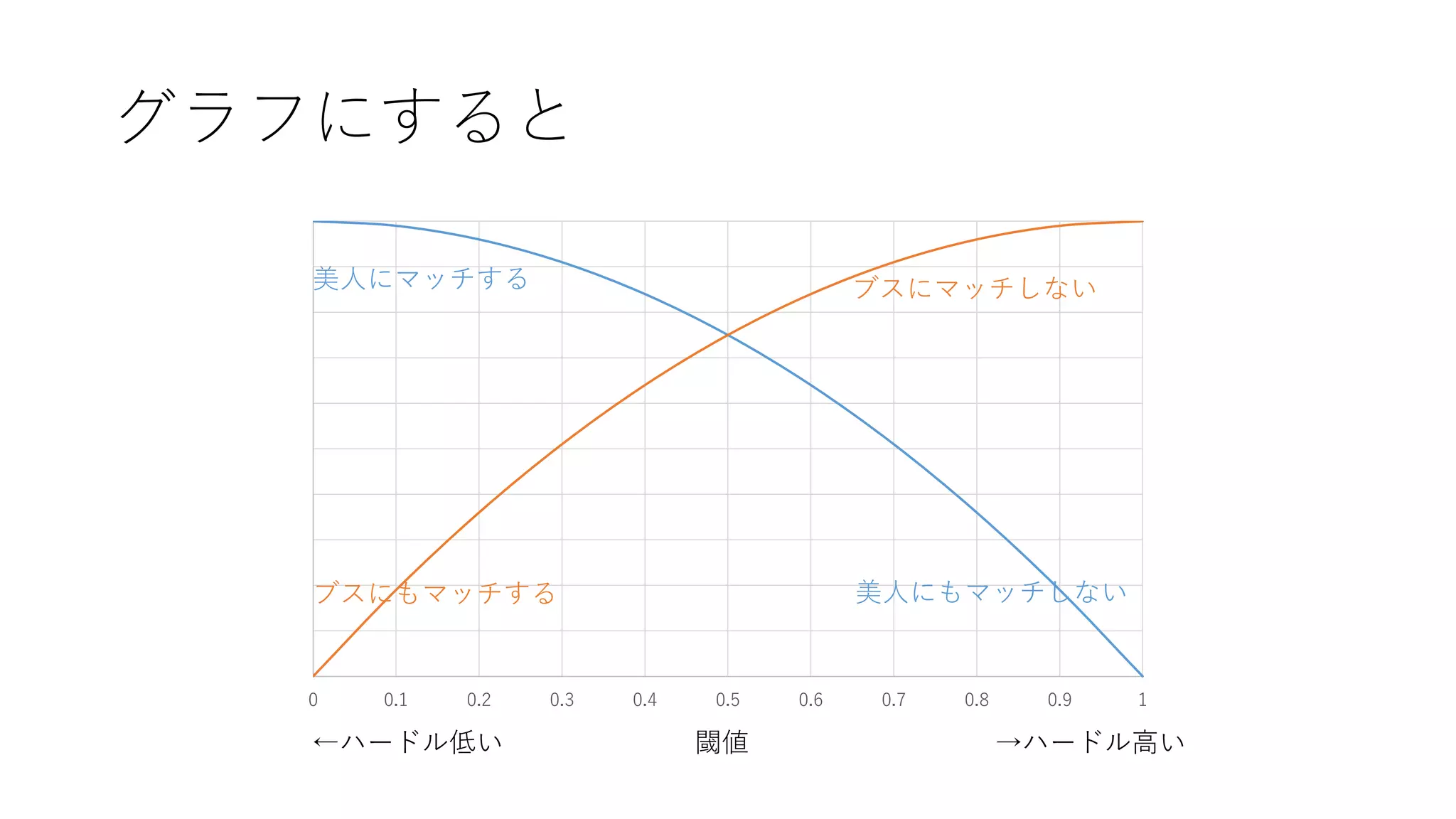
例:Tinder • 異常な事象=Tinderでかわいい女の子が登場 • 検出器=自分。異常度(可愛い度)がある閾値を超えたらLike •
閾値が低い→みんなLikeする →かわいい女の子と沢山マッチ・ブスとも沢山マッチする • 閾値が低い→あまりLikeしない →ブスとマッチ率は下がる・かわいい女の子も逃す
14.
グラフにすると 0 0.1 0.2
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 ブスにマッチしない 美人にもマッチしない ←ハードル低い 閾値 →ハードル高い 美人にマッチする ブスにもマッチする
15.
ネイマン-ピアソンの補題 [補題] ln 𝑝 𝑥 𝑦
= 1, 𝐷 𝑝 𝑥 𝑦 = 0, 𝐷 で与えられた異常度は、 ある一定の正常標本精度のもとで、異常標本精度を最大化する。 [証明] ラグランジュの未定乗数法
16.
Chapter 2 HotellingのT2法 データが多次元正規分布に従うとした場合の異常検知法
17.
PRML復習問題(1) M次元正規分布の確立密度関数を書きなさい。 平均はμ、分散共分散行列はΣとする。
18.
PRML復習問題(1) 答 M次元正規分布の確立密度関数を書きなさい。 平均はμ、分散共分散行列はΣとする。 𝑁 𝑥
𝜇, Σ = Σ − 1 2 (2𝜋) 𝑀/2 exp{− 1 2 𝑥 − 𝜇 𝑇 Σ−1 𝑥 − 𝜇 }
19.
PRML復習問題(2) • 𝑋1, 𝑋2,
・・・𝑋 𝑛~𝑁 0,1 ,iidの確率変数を用いて (1)χ2乗分布 自由度k (2)F分布 自由度(l,m) に従うような確率変数を定義せよ。
20.
PRML復習問題(2)答 • 𝑋1, 𝑋2,
・・・𝑋 𝑛~𝑁 0,1 ,iidの確率変数を用いて (1)χ2乗分布 自由度k (2)F分布 自由度(l,m) に従うような確率変数を定義せよ。 (1)𝜒 k = 𝑋1 2 + ⋯ + 𝑋 𝑘 2 (2)𝐹 𝑙, 𝑚 = 𝜒 𝑙 𝑙 / 𝜒m 𝑚 :分散の比
21.
HotellingのT2法 [定理] 𝑇2 = N − M 𝑁
+ 1 𝑀 a x = − N − M 𝑁 + 1 𝑀 ln(p x D ) は自由度(M,N-M)のF分布に従う。 N>>Mのとき、自由度M、スケール因子1のχ2乗分布に従う
22.
マハラノビス距離(PRML復習) • 𝑁 𝑥
𝜇, Σ = Σ − 1 2 (2𝜋) 𝑀/2 exp{− 1 2 𝑥 − 𝜇 𝑇 Σ−1 𝑥 − 𝜇 } 𝑎 𝑥 = − ln 𝑝 𝑥 𝐷 の定数項を無視して考えると、 𝑥 − 𝜇 𝑇Σ−1 𝑥 − 𝜇 • これはマハラノビス距離 →つまりT2法はマハラノビス距離が大きいものを異常とする。 https://www.slideshare.net/SeiichiUchida/21-77833992
23.
Chapter 3 Naïve Bayes法 データセットが各成分が独立としたときのT2法
24.
PRML復習問題(3) • 迷惑メールの分類問題を考える。 • まずM単語収録されている辞書を用意する。 •
𝑥𝑖=(単語iの出現回数)としてM次元のベクトルを作る。 • このとき、xは単語iの出現確率𝜃𝑖に従う多項分布と考えれる。 • [問題] xが従っている多項分布の確率密度関数を書け。 http://machine-learning.hatenablog.com/entry/2016/03/26/211106
25.
PRML復習問題(3)答 • 迷惑メールの分類問題を考える。 • まずM単語収録されている辞書を用意する。 •
𝑥𝑖=(単語iの出現回数)としてM次元のベクトルを作る。 • このとき、xは単語iの出現確率𝜃𝑖に従う多項分布と考えれる。 • [問題] xが従っている多項分布の確率密度関数を書け。 • [答]𝑀𝑢𝑙𝑡 𝑥 𝜃 = 𝑥1+⋯+𝑥 𝑀 ! 𝑥1!𝑥2!⋯𝑥 𝑀! 𝜃1 x1 𝜃2 x2 ⋯ 𝜃M xM
26.
迷惑メールを単純ベイズ分類器で判別 • 今回は教師あり学習 • メールの単語出現回数は多項分布に従うとする。 •
辞書をM単語与える • 普通のメールの単語出現回数はMult(x|θ) • 迷惑なメールの単語出現回数はMult(x|φ) に従っているとすると、 [問]𝑥 ∈ 𝑅 𝑀を与えたときの異常度は?
27.
迷惑メールを単純ベイズ分類器で判別 [問]𝑥 ∈ 𝑅
𝑀 を与えたときの異常度は? ln Mult(x|φ) Mult(x|θ) 𝑀𝑢𝑙𝑡 𝑥 𝜃 = 𝑥1+⋯+𝑥 𝑀 ! 𝑥1!𝑥2!⋯𝑥 𝑀! 𝜃1 x1 𝜃2 x2 ⋯ 𝜃M xM の第1項は消える。 よって、 ln Mult(x|φ) Mult(x|θ) = ln{ෑ i 𝜙𝑖 𝜃𝑖 xi } = i 𝑥𝑖 ln 𝜙𝑖 𝜃𝑖
28.
PRML復習問題(4) [問] 最尤推定とMAP推定について説明せよ。
29.
PRML復習問題(4)答 [問] 最尤推定とMAP推定について説明せよ。 [答] データ𝐷=
𝑥𝑖 𝑖 、Dは𝑝 𝑥 𝜃 という確率分布に従うとする。 パラメータθを求める方法として、最尤推定とMAP推定がある。 どちらも、尤度𝑝 𝜃 𝐷 を最大化するθを求めるが、 最尤推定はDのみからθを最大化し、 MAP推定はθに事前分布を仮定し𝑝 𝜃 𝐷 ~𝑝 𝐷 𝜃 𝑝 𝜃 を最大化。
30.
ベイズ決定則 [定理(ベイズ決定則)] ln 𝑝 y =
1 x 𝑝 y = 0 x >0 ならば異常 y=1とみなすとき、 これは誤り確率(=異常を正常とみなす+正常を異常とみなす) を最小化する。 [参考] 頻度主義 vs ベイジアン • ネイマンピアソンはp(x|y=1)とp(x|y=0)の比が閾値を超えると異常 • ベイズ決定則はp(x|y=1)/p(x|y=0)>p(y=0)/p(y=1)となると異常
31.
Chapter 4 近傍法とマージン最大化 k近傍法でやってみよう
32.
マージン最大化法 kNNで異常値を予測できそうな事はわかる。 • 距離をどうすればいいのかという問題になる。 1.マハラノビス距離 2.マージン最大化法
33.
マージン最大化法 kNNで異常値を予測できそうな事はわかる。 • 距離をどうすればいいのかという問題になる。 1.マハラノビス距離 2.マージン最大化法 =同一ラベルの距離は短くする 異常ラベルからの距離は大きくする
34.
マージン最大化 • A:半正定値行列(復習!)とする。 𝑑 𝐴 2 (x,
y) = 𝑥 − 𝑦 𝑇 𝐴 𝑥 − 𝑦 で距離を定める。Aが満たす条件は、 𝑥 𝑛が与えられ、𝑥 𝑛の同一ラベルk最近傍標本を𝑁 𝑛とする 𝜙n 𝐴 = σi∈Nn 𝑑 𝐴 2 𝑥 𝑛, 𝑥𝑖 𝜓n 𝐴 = 𝑗∈Nn 𝑙 yl≠yn 1 + 𝑑 𝐴 2 𝑥 𝑛, 𝑥𝑗 − 𝑑 𝐴 2 𝑥 𝑛, 𝑥𝑙 + をそれぞれ最小化する。(やり方は勾配で)
35.
Chapter 5 混合分布による異常検知 データセットが混合正規分布としたときのT2法
36.
混合正規分布(PRML復習) • xがk次の混合正規分布に従うとは、 重み𝜋𝑖とi要素の平均𝜇𝑖,分散共分散行列Σ𝑖が存在して、 𝑃 x
= 𝑖=1,⋯,k 𝜋𝑖 𝑁 𝑥 𝜇𝑖, Σ𝑖 となること。ただし、σ𝑖 𝜋𝑖 = 1
37.
PRML復習問題(5) • 混合正規分布のパラメータ推定をEMアルゴリズムでせよ
38.
PRML復習問題(5)答 • 混合正規分布のパラメータ推定をEMアルゴリズムでせよ • [E-step]
パラメータを使って、負担率の計算 • [M-step] 負担率を使って、尤度を最大化するパラメータ計算
39.
PRML復習問題(5)答 • 混合正規分布のパラメータ推定をEMアルゴリズムでせよ • [E-step] •
[M-step] ←データnがクラスkに 属しているっぽさ ←kっぽいやつは重くする →あとは異常度を計算するだけ!
40.
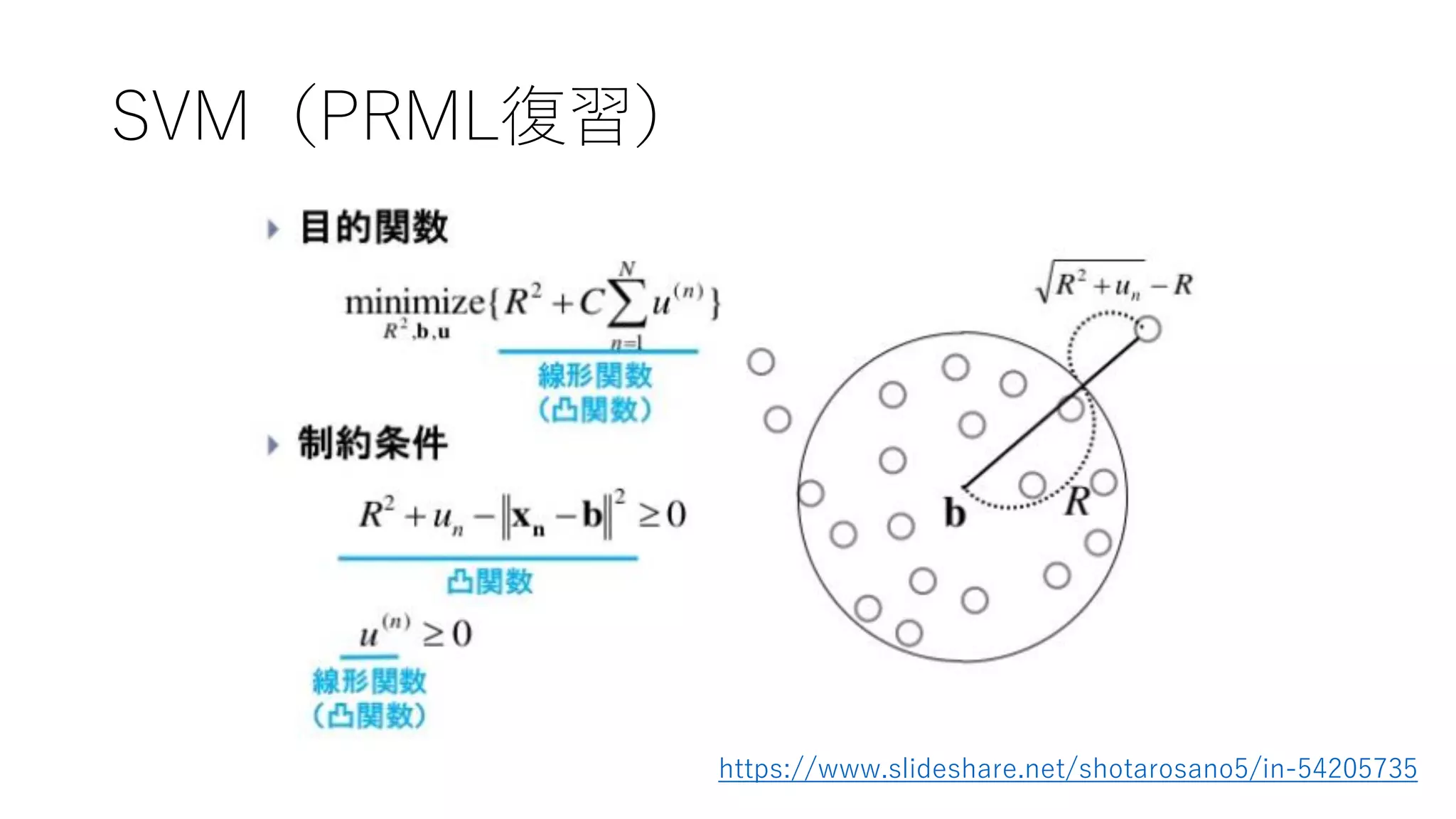
Chapter 6 SVMによる異常検知
41.
SVM(PRML復習) https://www.slideshare.net/shotarosano5/in-54205735
42.
SVM(復習) 方針 ①R,b,uについて最適解を求める ②αについて最適解を求める
43.
SVM(復習) 方針 ①R,b,uについて最適解を求める ②αについて最適解を求める
44.
SVM(復習) 方針 ①R,b,uについて最適解を求める →消去する ②αについて最適解を求める SMO法・双対座標降下法など https://www.slideshare.net/JungkyuLee1/svm-4rd-edition 37枚目からがSMO・双対座標降下に詳しい
45.
Chapter7 方向データの異常検知 単位ベクトルデータはフォンミーゼスフィッシャー分布に従うので、 それでやればいいよね(飛ばす)
46.
Chapter8 Gauss過程による異常検知
47.
PRML復習 Gauss過程 • 次のような線形回帰モデルを考える。 •
係数の分布は正規とする。 • Yを1つのベクトルにまとめて、 とおくと、
48.
PRML復習問題(6) • 前頁のように、 と仮定するとき、yの従う分布を求めよ。
49.
PRML復習問題(6)答 • 前頁のように、 と仮定するとき、yの従う分布を求めよ。答:正規分布N(0,K)
50.
PRML復習問題(7) • 次のようなノイズがあるモデルを考える。 • ただし、yは前頁までで求めたもの。このとき、 •
と仮定するとき、tの分布を求めよ。
51.
PRML復習問題(7)答 • 親の顔よりみたアレを覚えていますか?という問題
53.
PRML復習問題(7)答 • 親の顔よりみたアレを覚えていますか?という問題
54.
Gauss過程による異常度 • ガウス過程による予測の結果を思い出すと、 • よって
55.
赤い本のその後 • Chapter10 疎構造学習 http://latent-dynamics.net/01/2010_LD_Ide.pdf •
杉山先生と共著なこともあって、最後2章は密度比推定。
56.
密度比推定で異常検知 https://speakerdeck.com/oshokawa/mi-du-bi-tui-ding-niyoruyi-chang-jian-zhi?slide=67
Download









![ネイマン-ピアソンの補題
[補題]
ln
𝑝 𝑥 𝑦 = 1, 𝐷
𝑝 𝑥 𝑦 = 0, 𝐷
で与えられた異常度は、
ある一定の正常標本精度のもとで、異常標本精度を最大化する。
[証明]
ラグランジュの未定乗数法](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-15-2048.jpg)





![HotellingのT2法
[定理]
𝑇2
=
N − M
𝑁 + 1 𝑀
a x = −
N − M
𝑁 + 1 𝑀
ln(p x D )
は自由度(M,N-M)のF分布に従う。
N>>Mのとき、自由度M、スケール因子1のχ2乗分布に従う](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-21-2048.jpg)


![PRML復習問題(3)
• 迷惑メールの分類問題を考える。
• まずM単語収録されている辞書を用意する。
• 𝑥𝑖=(単語iの出現回数)としてM次元のベクトルを作る。
• このとき、xは単語iの出現確率𝜃𝑖に従う多項分布と考えれる。
• [問題] xが従っている多項分布の確率密度関数を書け。
http://machine-learning.hatenablog.com/entry/2016/03/26/211106](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-24-2048.jpg)
![PRML復習問題(3)答
• 迷惑メールの分類問題を考える。
• まずM単語収録されている辞書を用意する。
• 𝑥𝑖=(単語iの出現回数)としてM次元のベクトルを作る。
• このとき、xは単語iの出現確率𝜃𝑖に従う多項分布と考えれる。
• [問題] xが従っている多項分布の確率密度関数を書け。
• [答]𝑀𝑢𝑙𝑡 𝑥 𝜃 =
𝑥1+⋯+𝑥 𝑀 !
𝑥1!𝑥2!⋯𝑥 𝑀!
𝜃1
x1
𝜃2
x2
⋯ 𝜃M
xM](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-25-2048.jpg)
![迷惑メールを単純ベイズ分類器で判別
• 今回は教師あり学習
• メールの単語出現回数は多項分布に従うとする。
• 辞書をM単語与える
• 普通のメールの単語出現回数はMult(x|θ)
• 迷惑なメールの単語出現回数はMult(x|φ)
に従っているとすると、
[問]𝑥 ∈ 𝑅 𝑀を与えたときの異常度は?](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-26-2048.jpg)
![迷惑メールを単純ベイズ分類器で判別
[問]𝑥 ∈ 𝑅 𝑀
を与えたときの異常度は?
ln
Mult(x|φ)
Mult(x|θ)
𝑀𝑢𝑙𝑡 𝑥 𝜃 =
𝑥1+⋯+𝑥 𝑀 !
𝑥1!𝑥2!⋯𝑥 𝑀!
𝜃1
x1
𝜃2
x2
⋯ 𝜃M
xM
の第1項は消える。
よって、
ln
Mult(x|φ)
Mult(x|θ)
= ln{ෑ
i
𝜙𝑖
𝜃𝑖
xi
} =
i
𝑥𝑖 ln
𝜙𝑖
𝜃𝑖](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-27-2048.jpg)
![PRML復習問題(4)
[問] 最尤推定とMAP推定について説明せよ。](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-28-2048.jpg)
![PRML復習問題(4)答
[問] 最尤推定とMAP推定について説明せよ。
[答] データ𝐷= 𝑥𝑖 𝑖 、Dは𝑝 𝑥 𝜃 という確率分布に従うとする。
パラメータθを求める方法として、最尤推定とMAP推定がある。
どちらも、尤度𝑝 𝜃 𝐷 を最大化するθを求めるが、
最尤推定はDのみからθを最大化し、
MAP推定はθに事前分布を仮定し𝑝 𝜃 𝐷 ~𝑝 𝐷 𝜃 𝑝 𝜃 を最大化。](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-29-2048.jpg)
![ベイズ決定則
[定理(ベイズ決定則)]
ln
𝑝 y = 1 x
𝑝 y = 0 x
>0 ならば異常 y=1とみなすとき、
これは誤り確率(=異常を正常とみなす+正常を異常とみなす)
を最小化する。
[参考] 頻度主義 vs ベイジアン
• ネイマンピアソンはp(x|y=1)とp(x|y=0)の比が閾値を超えると異常
• ベイズ決定則はp(x|y=1)/p(x|y=0)>p(y=0)/p(y=1)となると異常](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-30-2048.jpg)







![PRML復習問題(5)答
• 混合正規分布のパラメータ推定をEMアルゴリズムでせよ
• [E-step] パラメータを使って、負担率の計算
• [M-step] 負担率を使って、尤度を最大化するパラメータ計算](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-38-2048.jpg)
![PRML復習問題(5)答
• 混合正規分布のパラメータ推定をEMアルゴリズムでせよ
• [E-step]
• [M-step]
←データnがクラスkに
属しているっぽさ
←kっぽいやつは重くする
→あとは異常度を計算するだけ!](https://image.slidesharecdn.com/9qx9pdsrsywgs93bmtyc-signature-22a53ed426055cd28831dd0fe3f7c794bcd6f0ebd328ce92fdd947fa62a3ac67-poli-180610124031/75/PRML-39-2048.jpg)

















![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)















![[ICLR/ICML2019読み会] Data Interpolating Prediction: Alternative Interpretation ...](https://cdn.slidesharecdn.com/ss_thumbnails/20190721shimada-190721024027-thumbnail.jpg?width=640&height=640&fit=bounds)





























