Recommended
PDF
PDF
PDF
PPTX
PDF
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
PDF
PDF
状態空間モデルの考え方・使い方 - TokyoR #38
PPTX
PDF
PDF
PDF
Control as Inference (強化学習とベイズ統計)
PDF
PDF
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
PDF
PDF
PRML上巻勉強会 at 東京大学 資料 第1章後半
PDF
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
PDF
PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半
PDF
PDF
PDF
PDF
PDF
PPTX
PDF
PDF
PDF
More Related Content
PDF
PDF
PDF
PPTX
PDF
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
PDF
PDF
状態空間モデルの考え方・使い方 - TokyoR #38
What's hot
PPTX
PDF
PDF
PDF
Control as Inference (強化学習とベイズ統計)
PDF
PDF
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
PDF
PDF
PRML上巻勉強会 at 東京大学 資料 第1章後半
PDF
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
PDF
PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半
PDF
PDF
PDF
PDF
PDF
PPTX
PDF
Viewers also liked
PDF
PDF
PDF
PDF
DOCX
Gr 8 music q3 page 121 #mcspicyishere http://ph.sharings.cc/teachermarley/s...
PDF
Similar to パターン認識 04 混合正規分布
PPTX
PDF
PDF
PDF
PDF
[PRML] パターン認識と機械学習(第1章:序論)
PDF
PDF
PDF
PDF
PPTX
PDF
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
PDF
Bishop prml 9.3_wk77_100408-1504
PPTX
PPTX
[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging
PPTX
PDF
PDF
PDF
PDF
More from sleipnir002
PDF
PDF
PDF
How to use animation packages in R(Japanese)
PDF
PPTX
PDF
PDF
Recently uploaded
PDF
Help_Center_Index_spec_ja_ver5_202601.pdf
PDF
monopo 2026 credentials Japanese version
PDF
【会社紹介資料】 株式会社カンゲンエージェント [ 2026/01 公開 ].pdf
PDF
株式会社DriveXの紹介資料です。会社・事業概要と人材の募集要件が記載されています。
PDF
【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf
PDF
【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf
PDF
【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf
PDF
【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf
PDF
【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf
PDF
【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf
PDF
【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf
PPTX
HOUSEI株式会社の主な事業セグメントは、国内IT事業と海外IT事業です。国内IT事業では、システム開発やAI関連サービスを提供し、海外IT事業では中国...
PDF
2026Culture Deck_Sustainable Lab|2026カルチャーデック_サステナブル・ラボ
パターン認識 04 混合正規分布 1. Rで学ぶデータサイエンス
5パターン認識
第5章 混合分布モデル
2011/07/02
TwitterID:sleipnir002
2. R一人勉強会のご紹介
Rで学ぶデータサイエンス 5パターン認識
(著)金森 敬文, 竹之内 高志, 村田 昇, 金 明哲
共立出版
今ならデモスクリプトがダウンロードできる!
http://www.kyoritsu-
pub.co.jp/service/service.html#019256
彼女いない暦の5年8ヶ月の不細工でモテな私が
第1章 判別能力の評価 Done
第2章 k-平均法
第3章 階層的クラスタリング
あのかわいい女の子を
たったの3ヶ月でGET!!
第4章 混合正規分布モデル
第5章 判別分析
第6章 ロジスティック回帰
第7章 密度推定 はっと息を飲むようなあの美人がこの方法で
第8章 k-近傍法 Rでパターン認識ができるように、
第9章 学習ベクトル量子化
第10章 決定木 その結果、驚愕の真実が!
第11章 サポートベクターマシン
第12章 正則化とパス追跡アルゴリズム
第13章 ミニマックス確率マシン
第14章 集団学習 さぁ、今すぐAmazonでクリック!!
第15章 2値判別から多値判別へ
3. 4. 第5章の目的
混合分布による教師なしクラスタリング
EMアルゴリズムによるモデル推定
• キーワード
– 混合分布
– EMアルゴリズム
– AIC、BIC
5. 6. 7. 混合正規分布とは(2)
M
p( x; ) m ( x; m , m )
m 1
• ちなみにπも確率 m ; m 1, m 0, m {1,..., M }
m
{1 m } パイは異なる
• θはパラメータ 正規分布を
重み付ける
m { m , m , m }
8. 混合分正規分布から
教師なしクラスタリングへ
1. 2つの要素正規分布から、混合正規分布が構成さ
れデータが発生する。
2. 混合正規分布モデルの下で、あるデータがもっとも
発生した要素がデータの属するクラスタである。
逆にデータか 要素からデー
ら要素を推定 タが生成され
する。 たと考える。
9. 混合正規分布による
教師なしクラスタリング
• ベイズの定理を使うと…
p( x, m; )
p(m | x; )
p ( x; )
ただのベイズの定理
m ( x; m , m )
M
m 1
( x; m , m )
m
⇒モデルがわかれば、教師なしクラスタリングがで
きる。
10. クラスタリングを行うために
• モデルが与えられれば(パラメータが与えら
れれば)、クラスタリングができる
• 次に考えるのはデータからモデルを推定する
こと。
既にあるデータ モデルθ クラスタリング
x11 x1 p arg m max p(m | x)
X
x x m
n1 np
新データ
x1
x
x
n
11. 12. じゃあ、どうやって推定する?
• しかし、最尤推定を行いたい。
• →パラメータxとモデルを表すラベルmの対、( xi , mi )
が明らかになっていれば計算できる
(証明は教科書で)
n
arg Max log p( xi , mi ; )
ˆ
n
arg Max log p( xi ; )
ˆ
i 1
i 1
ラベルを与える
n
arg Max log m ( xi , mi ; )
n
arg Max log m ( xi ; )
i 1
i 1
⇒どのように、 xi , mi )を与えるか?
(
13. EMアルゴリズム
• EMアルゴリズム・・・反復によって欠損データの最尤推定を
行う方法
• 混合分布の場合、所与のデータが属するラベルが欠損して
いると考える。
通常のデータ行列 EMアルゴリズムで扱うデータ行列
欠けたデータ
x11 x1 p x11 x1 p m1
X X
x x x x m
n1 np n1 np n
14. 15. EMアルゴリズムのイメージ
• 言葉で言ってもわからないので、可視化した
ものをみてみましょう。
入力: Eステップ:
データX Q( , (t ) )
x11 x1 p の計算
出力:
x x t=t++ パラメータ:θ
n1 np
Mステップ:
パラメータ初期値θ’ Q( )
の最大化
*アルゴリズムの詳細は下記リンクをチェック!
http://vrl.sys.wakayama-u.ac.jp/PRA/EM/MixtureEMj.html
16. 17. 18. Mclustによるクラスタリングの
大まかな流れ
パッケージ:MClust
結果の可視化:
モデル推定:Mclust
mclust2Dplot
引数1:データX 引数2:データX
所与のデータX 複数のモデルの中からBICの高い 引数2:Mclustのprameters
ものを選択してMclustオブジェク 引数3:可視化内容
トを返す 結果を可視化する
事後確率の計算:
分類:map
cdens
引数1:予測したい新データX’ 引数1:cdensの事後確率
予測したいデータx’ 引数2:Mclustのparameters もっとも事後確率の高いラベ
データの事後確率を計算する。 ルのデータを返す。
注:関数のデータの大まかなながれです。引数は他に色々あるので注意してください。
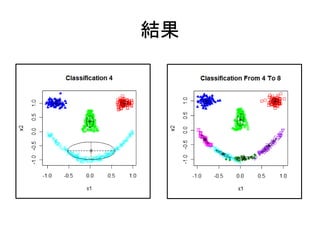
19. 20. 混合分布でクラスタリングする
library(mclust); library(mlbench) Package mclust
dat <- mlbench.smiley()
colnames(dat$x) <- c("x1","x2")
dev.new()
(gmm4 <- Mclust(dat$x,G=4))
混合正規分布モデルの
mclust2Dplot(dat$x,parameters=gmm4$parame 推定、要素数G=4
ters,z=gmm4$z,what="classification")
title("Classification 4") 判別結果をプロット
dev.new()
(gmmup8 <- Mclust(dat$x,G=4:8)) 要素モデルの数を4とす
mclust2Dplot(dat$x,parameters=gmmup8$para る
meters,z=gmmup8$z,what="classification")
title("Classification From 4 To 8") 要素モデルの数を4から
8とする
21. 22. 23. ModelNamesオプション
• Mclustパッケージではモデルとして以下のオ
プションの中から希望のものを指定できる。
#e.g.
(gmm5 <- Mclust(dat$x,G=5, modelNames="EEE"))
mclust2Dplot(dat$x,parameters=gmm5$parameters,z=gmm5$z,what="classification")
title("EEE")
注:全部で10種類指定できる。指定しないと、一番当てはまりのよいものを使用する。
24. 25. 26. 27. 混合数の推定
• 混合数の推定=モデルの妥当性の検証
– 交差検証法
• 第1回で説明済み
→you! Forループまわしてプログラム書いちゃいなよ。
– 情報量を用いる
• AIC:赤池情報量基準
– 特定のパラメータのあてはまりのよさ
• BIC:ベイズ情報量基準
– モデル全体でのあてはまりのよさ
– Mclustではモデルの選択にBICを用いている。
28. BIC
• 複数のモデルが等しい事前確率で選択され
ると仮定した上で、尤度の期待値
BIC 2nE log p( X ; ) p(l | D)dl
n
BIC ( l ) 2 log p( xi ; ) | l | log n
ˆ ˆ ˆ
i 1
モデルVVVの要素数7
がBICがもっとも高いの
でMclustで選ばれる。
gmm<-Mclust(dat$x)
plot.mclustBIC(gmm$BIC, legendArgs=list(x="bottomright", cex=0.7, ncol=2))

































































![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)









![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)














![【会社紹介資料】 株式会社カンゲンエージェント [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/202601-260109011218-57ff1508-thumbnail.jpg?width=640&height=640&fit=bounds)

![【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dx-260109085534-7362cbc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dx-260110091700-f9430e2d-thumbnail.jpg?width=640&height=640&fit=bounds)
![【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dx-260109084717-293d42bc-thumbnail.jpg?width=640&height=640&fit=bounds)
![【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dx-260111043954-4d99478e-thumbnail.jpg?width=640&height=640&fit=bounds)
![【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dx-260109091120-2e61a704-thumbnail.jpg?width=640&height=640&fit=bounds)
![【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dx-260109094457-99cdcb44-thumbnail.jpg?width=640&height=640&fit=bounds)
![【会社紹介資料】DXインキュベーション株式会社 [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dx-260109090506-c3f9affd-thumbnail.jpg?width=640&height=640&fit=bounds)

