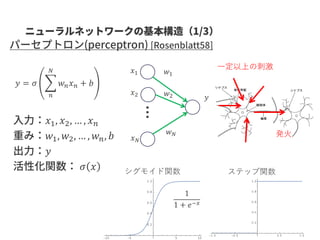
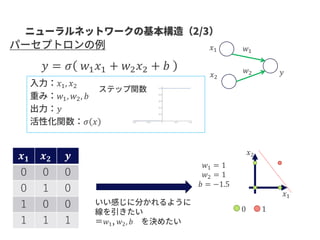
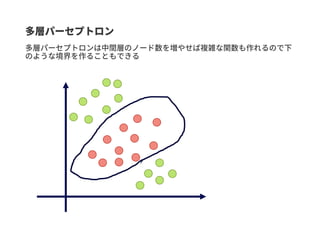
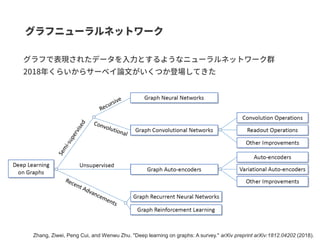
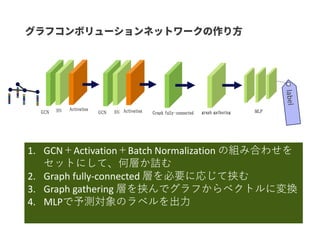
Graph-centric vs Node-centric
Class2
Class 1
Class 1
Class 1
Class 2
Class 1
Node-centric: ノードにラベルがついているGraph-centric: グラフにラベルがついている
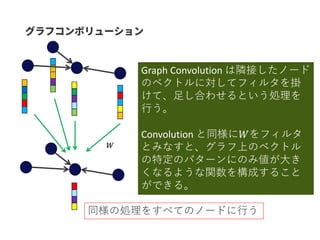
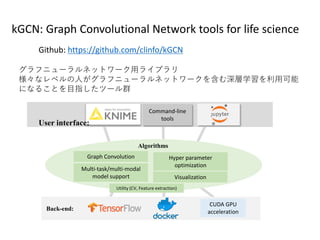
GCN はGraph-centric と Node-centricの両方に対応できる。
SNSのデータなどはNode-centricな方が自然な場合がある
51.
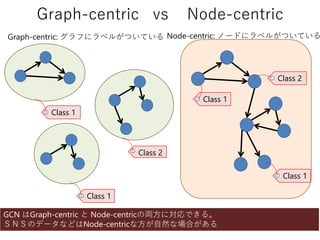
Graph-centric vs Node-centric
Graph-centricの例
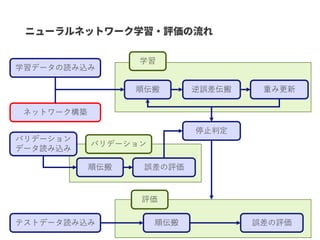
BNGCN
Activation
BNGCN Activation Graph fully-connected graph gathering MLP
O
OH
NH2OO NH
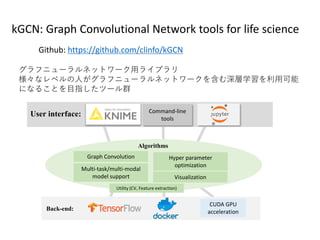
・水溶性予測
・毒性予測Node-centric の例
BNGCN
Activation
BNGCN Activation Graph fully-connected
Class 2
Class 1
SNSネットワーク
・ボット検出
・潜在顧客検出
52.
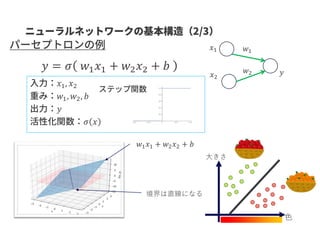
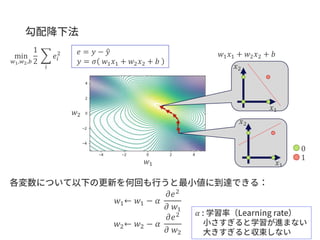
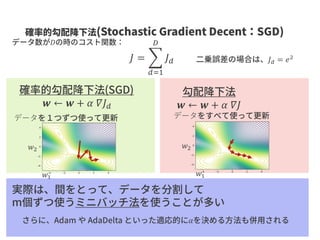
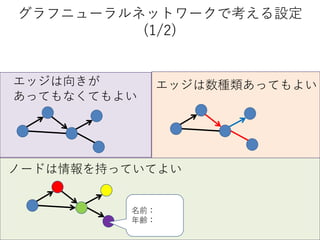
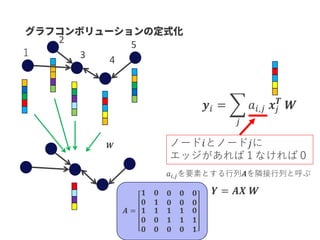
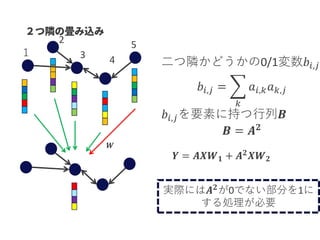
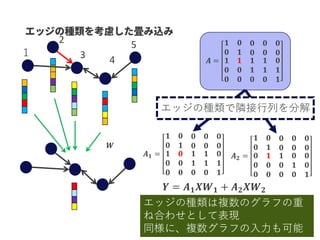
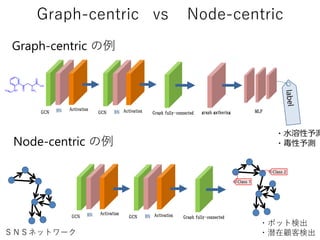
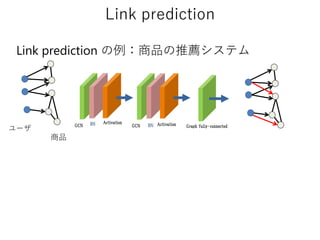
𝑓( , )
Linkprediction
A
C D
EB
GCNにより
得られるベクトル
入力グラフ
疑似負例 正例
𝑓( , )A CA B
<
スコア関数 成り立つようにスコア関数&GCNを学習
スコア関数の値が高いほどエッジのある可能性が高い
(エッジがない&スコアが高い→未知のエッジの可能性が高い)
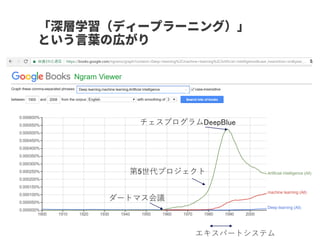
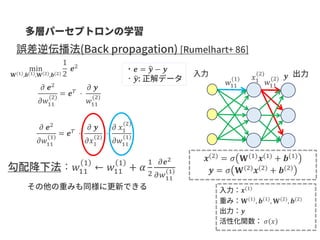
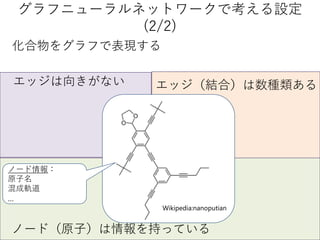
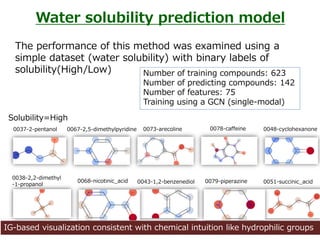
The performance ofthis method was examined using a
simple dataset (water solubility) with binary labels of
solubility(High/Low)
Water solubility prediction model
0037-2-pentanol
0038-2,2-dimethyl
-1-propanol 0043-1,2-benzenediol
0048-cyclohexanone
0051-succinic_acid
0067-2,5-dimethylpyridine
0068-nicotinic_acid
0073-arecoline 0078-caffeine
0079-piperazine
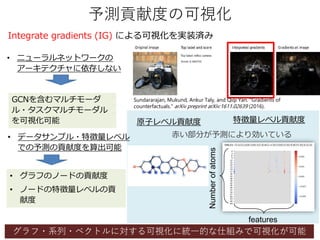
IG-based visualization consistent with chemical intuition like hydrophilic groups
Number of training compounds: 623
Number of predicting compounds: 142
Number of features: 75
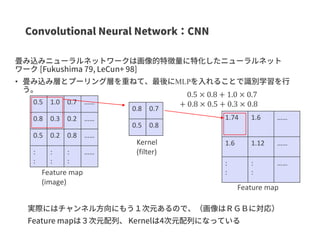
Training using a GCN (single-modal)
Solubility=High





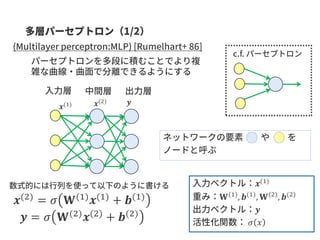


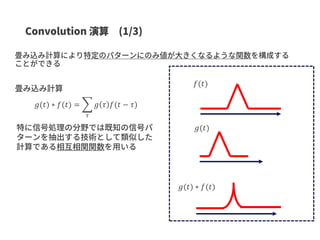
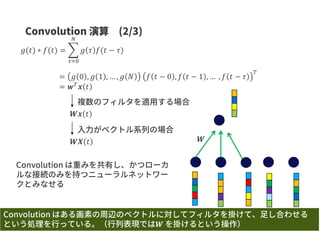
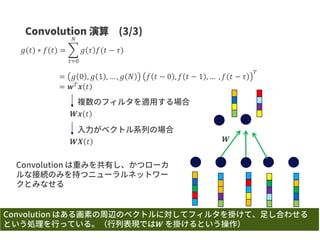





![𝑔(𝑡) ∗ 𝑓(𝑡) =
𝜏
𝑔 𝜏 𝑓(𝑡 − 𝜏)
𝑔(𝑡)
𝑓(𝑡)
𝑔(𝑡) ∗ 𝑓(𝑡)
𝐹 𝑔(𝑡) ∗ 𝑓(𝑡) = 𝐹 𝑔(𝑡)] 𝐹[𝑓(𝑡)
𝐹
𝐹 𝑓 𝑥 = න
−∞
∞
𝑓 𝑥 𝑒 𝑖𝜔𝑥 𝑑𝑥 = 〈𝑓 𝑥 , 𝑒 𝑖𝜔𝑥〉
Δℎ 𝜔(𝑥) = 𝜆 𝜔ℎ 𝜔(𝑥) ℎ 𝜔 𝑥 = 𝑒 𝑖𝜔𝑥
𝜆 𝜔 = −𝜔2
ℎ 𝑥](https://image.slidesharecdn.com/kgcnmathandcoding2-191006085247/85/slide-54-320.jpg)
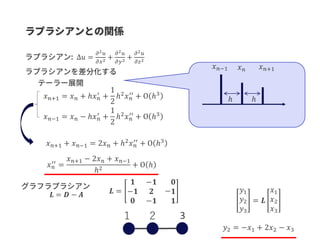
![𝑳 = 𝑫 − 𝑨
𝑨
𝑫
𝑳 = 𝑼𝚲𝐔 𝐓
ෝ𝒙 = 𝑼 𝑇 𝒙
𝒙 = 𝑼ෝ𝒙
𝑼 𝑑𝑖𝑎𝑔 𝒘 ෝ𝒙
= 𝑼𝑑𝑖𝑎𝑔 𝒘 𝑼 𝑇
𝒙
Δℎ 𝜔(𝑥) = 𝜆 𝜔ℎ 𝜔(𝑥)
𝐹 𝑓 𝑥 = 〈𝑓 𝑥 , ℎ 𝜔(𝑥)〉
𝐹 𝑔(𝑡) ∗ 𝑓(𝑡) = 𝐹 𝑔(𝑡)] 𝐹[𝑓(𝑡)𝑑𝑖𝑎𝑔 𝒘 : 𝒘を対角
要素に持つ行列
→ 𝑼𝑔 𝒘 𝚲 𝑼 𝑇 𝒙
𝑳 = 𝑫−1/2
𝑫 − 𝐀 𝑫−1/2](https://image.slidesharecdn.com/kgcnmathandcoding2-191006085247/85/slide-55-320.jpg)










![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)









![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Graph Convolutional Policy Network for Goal-Directed Molecular Graph G...](https://cdn.slidesharecdn.com/ss_thumbnails/graphconvolutionalpolicynetworkforgoal-directedmoleculargraphgeneration-181102004011-thumbnail.jpg?width=640&height=640&fit=bounds)















