Recommended
PDF
PDF
PDF
PDF
読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
感覚運動随伴性、予測符号化、そして自由エネルギー原理 (Sensory-Motor Contingency, Predictive Coding and ...
PDF
PPTX
PDF
PPTX
PDF
PPTX
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布
PDF
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
PDF
Neural networks for Graph Data NeurIPS2018読み会@PFN
PDF
Prml4.4 ラプラス近似~ベイズロジスティック回帰
PPTX
PDF
PDF
(DL hacks輪読) Deep Kernel Learning
PDF
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由
PPTX
PPTX
PDF
PDF
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
More Related Content
PDF
PDF
PDF
PDF
読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法
PDF
PDF
PDF
PDF
What's hot
PDF
PDF
PDF
PDF
感覚運動随伴性、予測符号化、そして自由エネルギー原理 (Sensory-Motor Contingency, Predictive Coding and ...
PDF
PPTX
PDF
PPTX
PDF
PPTX
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布
PDF
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
PDF
Neural networks for Graph Data NeurIPS2018読み会@PFN
PDF
Prml4.4 ラプラス近似~ベイズロジスティック回帰
PPTX
PDF
PDF
(DL hacks輪読) Deep Kernel Learning
PDF
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由
PPTX
PPTX
PDF
Similar to Prml 10 1
PDF
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
PDF
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
PDF
PDF
PPTX
PDF
PPT
PDF
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning)
PDF
PDF
PDF
PDF
Bishop prml 9.3_wk77_100408-1504
PDF
PDF
PRML_titech 2.3.1 - 2.3.7
PDF
PDF
PDF
PPTX
PPT
C:\D Drive\Prml\プレゼン\パターン認識と機械学習2 4章 D0703
More from 正志 坪坂
PDF
PDF
PDF
PPTX
KDD 2016勉強会 Deep crossing
PDF
PDF
WSDM 2016勉強会 Geographic Segmentation via latent factor model
PDF
PDF
PDF
PDF
PDF
PDF
PDF
Tokyowebmining ctr-predict
PDF
PDF
PDF
Contexual bandit @TokyoWebMining
PDF
Introduction to contexual bandit
PDF
PDF
Big Data Bootstrap (ICML読み会)
PDF
Prml 10 1 1. 2. 2010/3/7 PRML読書会 第12回 2
第10章 近似推論法
• 観測データが与えられたときの潜在変数の事後分布
(|)を求める
• 完全にベイズ的なモデルでは未知パラメータにも事前分布が与えられ、
潜在変数ベクトルの中に含まれている
• EMアルゴリズムでは完全データの対数尤度の期待値を隠れ
変数の事後分布に沿ってとった
• しかし、事後分布を求めることや期待値を計算することが不可能な事が
多い
• Ex: 次元が高すぎて空間全体を直接扱えない、期待値が解析的に計算
できない…
• 近似法を用いて事後分布を求める
3. 2010/3/7 PRML読書会 第12回 3
二つの近似法
• 近似法は近似が確率的か決定的かで分けられる
確率的手法 決定的手法
代表的な手法 MCMC(11章) 変分ベイズ、EP(10章)
長所 無限の時間があれば厳密 大規模な問題にも適応できる
な結果を計算できる 確定的に解が求まる
短所 学習結果が収束するまで 近似した結果しか得られない
の時間が膨大
• 確率的な手法の場合でもCollapsed Gibbs Samplerなどがあり、必
ずしも変分ベイズの方が高速とは限らない
• Griffiths, T. and Steyvers, M. (2004). Finding scientific topics. In
Proceedings of the National Academy of Sciences, 101, 5228-5235
• Yao, L., Mimno, D., and McCallum, A. Efficient Methods for Topic
Model Inference on Streaming Document Collections. In SIGKDD,
2009, 937-946
4. 2010/3/7 PRML読書会 第12回 4
• NLPでよく用いられるLDAというモデルでは変分ベイズ法より
Collapsed Gibbs Samplerの方が高い性能を示す
• A. Asuncion, M. Welling, P. Smyth and Y.W. Teh: On Smoothing
and Inference for Topic Models, In UAI 2009
5. 2010/3/7 PRML読書会 第12回 5
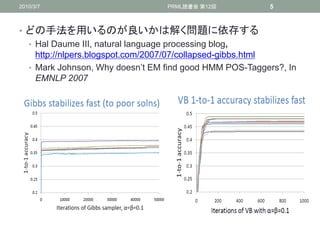
• どの手法を用いるのが良いかは解く問題に依存する
• Hal Daume III, natural language processing blog,
http://nlpers.blogspot.com/2007/07/collapsed-gibbs.html
• Mark Johnson, Why doesn’t EM find good HMM POS-Taggers?, In
EMNLP 2007
6. 2010/3/7 PRML読書会 第12回 6
典型的な決定的近似法
• ラプラス近似
• 4.4節で紹介
• 分布のモードを使って局所的にガウス分布で近似
• 変分ベイズ法(Variational Inference)
• 本章の10.1から10.6で述べる
• 変分近似を用いた手法
• EP法
• 本章の10.7で述べる
• 変分ベイズとは違った変分近似を用いる
7. 2010/3/7 PRML読書会 第12回 7
本日の発表
次回以降
(変分ベイズ)
次回以降
(EP)
8. 2010/3/7 PRML読書会 第12回 8
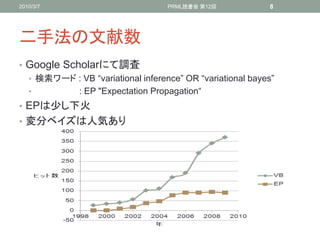
二手法の文献数
• Google Scholarにて調査
• 検索ワード : VB “variational inference” OR “variational bayes”
• : EP "Expectation Propagation“
• EPは尐し下火
• 変分ベイズは人気あり
9. 2010/3/7 PRML読書会 第12回 9
10.1 変分推論
• 汎関数:関数を入力として受け取り、出力として値を返す関数
• 汎関数の例:
• エントロピー
• 変分法とは全ての可能な入力関数の中から汎関数の値を最
大化/最小化する関数を解として得る手法である
• Ex: 球が位置Aから位置Bまでに最短時間で転がり落ちるための曲線の
形状をみつける
• 18世紀のオイラー、ラグランジュらに起源を持つ、数学や物理では古典
的な手法
10. 2010/3/7 PRML読書会 第12回 10
変分推論
• 全てのパラメータが事前分布を与えられた完全なベイズモデ
ルを考える
• パラメータ+潜在変数すべてをと書く
• 観測変数全てをと書く
• 確率モデルから(, )が定まっているとする
• 目的:事後分布(|)およびモデルエビデンス()の近似を
求める
11. 2010/3/7 PRML読書会 第12回 11
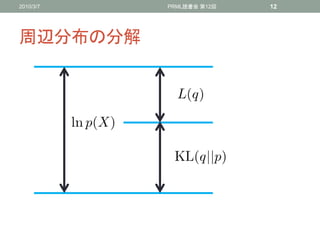
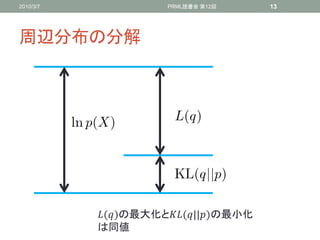
周辺分布の分解
• 周辺分布()は
• EM法と違ってパラメータベクトルが出てこない
• 下限()を分布()に関して最大化する
• KLダイバージェンスが0になるときに下限()が最大となり、
= (|)となり真の事後分布となる
• (|)を求めることは不可能であるとする
12. 13. 2010/3/7 PRML読書会 第12回 13
周辺分布の分解
()の最大化と(||)の最小化
は同値
14. 2010/3/7 PRML読書会 第12回 14
周辺分布の分解
• モデル上真の事後分布を求めることは不可能
• 制限したクラスの()を考え、この中でKLダイバージェンスを
最小にするものを探す
• クラスは計算可能かつ柔軟で真の事後分布をよりよく近似できることが
求められる
• 十分に柔軟な分布を使っても過学習は起きない!
• クラスの制限の方法としてはパラメータ集合によって決まる
パラメトリックな分布(|)を用いる
• このとき()はの関数となるので非線形最適化の手法によってパラ
メータの値を求めることができる
• より柔軟な分布の分解による手法を10.1.1で扱う
15. 2010/3/7 PRML読書会 第12回 15
10.1.1 分布の分解
• 潜在変数をいくつかの排反なグループに分割して、
( = 1, … , )と書く
• 分布がこれらのグループに関して分解されると仮定する
(10.5)
• 分解した各 の分布については何の仮定も設けない
• 以降記法の簡単のため ( )を と略記する
• この分解は物理学における平均場近似(mean field
approximation)という近似法に対応している
16. 2010/3/7 PRML読書会 第12回 16
変分下限の最適化
• 変分下限()を各因子 に関して順に最適化を行なう。
(10.6)
ここでconstは規格化定数
17. 2010/3/7 PRML読書会 第12回 17
変分下限の最適化
• (10.6)式は分布 と(, )の負のKLダイバージェンスとなっ
ている
• すなわち、(10.6)式を最大にする分布 は = (, )となる
• したがって最適解は
• また両辺の指数をとって正規化すると
• 実際は必要に応じて正規化定数を計算したほうが簡単なこと
が多い
18. 2010/3/7 PRML読書会 第12回 18
変分下限の最適化
∗
• 導出された最適解 は他の因子 に依存しており、完全な解
析解にはなっていない
• したがって因子の一つ一つを他の因子を固定して(10.9)に従
い更新していく
• この更新を行なうことによって収束することは保証されている
(Boyd and Vandenberghe, 2004)
19. 2010/3/7 PRML読書会 第12回 19
別の更新式を見たことのある方へ
• を潜在変数とパラメータに分けて考える
• このとき同時分布は , , = (, |)となる
• ここで事後分布を , = ()で近似する
• このとき、分布の更新式は
• ∝ exp log(, |)
• ∝ ()exp ,log , -
となる。(この更新式をVB-EMアルゴリズムとも呼ぶ)
cf. Hagai Attias, A Variational Bayesian Framework for Graphical Models, NIPS 12, 2000
持橋大地, 自然言語処理のための変分ベイズ法, http://chasen.org/~daiti-m/paper/vb-
nlp-tutorial.pdf, ATR SLC internal seminar, 2005
20. 2010/3/7 PRML読書会 第12回 20
更新式の導出
• の方のみの導出を示す
• (10.9)を使うと
ln ∗ = ln + ln , +
= ln + ln , +
より
∝ ()exp ,log , -
21. 2010/3/7 PRML読書会 第12回 21
別の解法
• 10.4章で示されるが、モデルが共役事前分布を持っている場
合は変分事後分布の関数型は既知となる
• これらの分布の一般的な式を用いて変分下限をパラメータの
関数として求められる
• 各パラメータに関して下限を最大化しても求める再推定式が
得られる
• LDA(Blei 2003)はこの方法をとっている
22. 2010/3/7 PRML読書会 第12回 22
Collapsed Variational Bayes (Teh 2006)
• 言語モデルでよく用いられるLDA(Blei 2003)に対する推論方
法として提案された
• , = ()の代わりに , = |, ()を
用いる
• このままでは計算できないので、Taylor展開など工夫した近似を行なう
• Dirichlet Process Mixture Modelsなどのより高度なモデルで
も用いることができる(Kurihara 2007 UJCAI, Teh 2007
NIPS, 佐藤 2007 IPSJ)
23. 2010/3/7 PRML読書会 第12回 23
10.1.2 分解による近似のもつ性質
• 相関のある2変数 = (1 , 2 )についてのガウス分布
= (|, Λ−1 )を考える
1 Λ11 Λ12
= , Λ =
2 Λ21 Λ22
• この分布を = 1 (2 )で近似する
∗
• 一般的な結果(10.9)を 使って、最適な因子1 (1 )を求める
∗
ln 1 1 = 2 ln + const
1
= 2 − 2 1 − 1 2 Λ11 − 1 − 1 Λ12 2 − 2 + const
1 2
= 1 Λ11 + 1 1 Λ11 − 1 Λ12 2 − 2 + const (10.11)
2
24. 2010/3/7 PRML読書会 第12回 24
分解による近似の持つ性質
• (10.11)は1 の二次関数より ∗ (1 )はガウス分布となる
• ∗ (1 )の形をガウス分布と特には仮定してなかった
• 全ての可能な分布の中から最適なものとしてこれが得られた
• 平方完成を行なうと
1 1 = 1 1 , Λ−1
∗
11
−1
1 = 1 − Λ11 Λ12 ( 2 − 2 )
• また対称性から ∗ (2 )に関しても
2 2 = 2 2 , Λ−1
∗
22
−1
2 = 2 − Λ22 Λ 21 ( 1 − 1 )
• これらの解には相互依存関係があるが、連立方程式を解くこ
とにより閉形式の解が求まる
25. 2010/3/7 PRML読書会 第12回 25
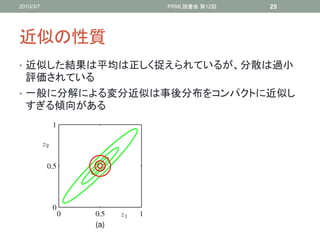
近似の性質
• 近似した結果は平均は正しく捉えられているが、分散は過小
評価されている
• 一般に分解による変分近似は事後分布をコンパクトに近似し
すぎる傾向がある
26. 2010/3/7 PRML読書会 第12回 26
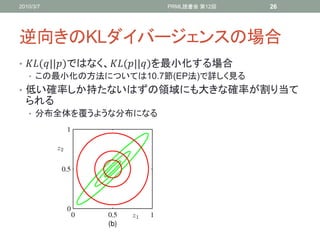
逆向きのKLダイバージェンスの場合
• (||)ではなく、(||)を最小化する場合
• この最小化の方法については10.7節(EP法)で詳しく見る
• 低い確率しか持たないはずの領域にも大きな確率が割り当て
られる
• 分布全体を覆うような分布になる
27. 2010/3/7 PRML読書会 第12回 27
逆向きのKLダイバージェンス
• に関する項だけを抜き出すと
• 最適なはラグランジュ乗数法を用いると
28. 2010/3/7 PRML読書会 第12回 28
KLダイバージェンスの最小化
• がほとんど0でがそうでないばあい、大きな正の寄与となる
• したがって、が小さい領域を避けるようになり、分布を過小評価する傾
向がある
• 逆向きのKLダイバージェンスを考えた場合は、が0でなくが
ほとんど0となると大きな正の寄与となる
• したがって、分布を全て覆うような近似となる傾向がある
29. 2010/3/7 PRML読書会 第12回 29
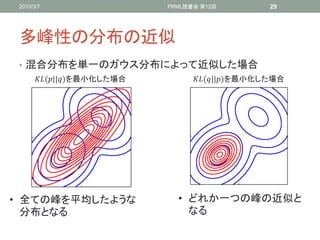
多峰性の分布の近似
• 混合分布を単一のガウス分布によって近似した場合
(||)を最小化した場合 (||)を最小化した場合
• 全ての峰を平均したような • どれか一つの峰の近似と
分布となる なる
30. 2010/3/7 PRML読書会 第12回 30
ダイバージェンス
• 実は(| , (||)は両方ともダイバージェンスという
値の特殊系となっている
• ダイバージェンス
4 1+ 1−
(| = 1− () 2 () 2
1 − 2
• (| は → 1の極限に対応し, (| は → −1の極限に
対応する
• = 0のときの式はヘリンガー距離に比例する
• ヘリンガー距離は式(10.20)で与えられる
31. 2010/3/7 PRML読書会 第12回 31
ダイバージェンス
• 固定された分布()に関して (| をある分布()に関し
て最小化することを考える(*任意の分布に対しては = の
ときに最小値0をとる)
• ≤ −1のときゼロ志向(zero forcing)となる
• = 0ならば = 0に近づく
• ()が()の大きい峰を探して近似するようになる
• ()の領域を過小評価するようになる
• ≥ 1のときゼロ回避(zero-avoiding)となる
• > 0ならば > 0となることが多くなる
• ()は()の領域をカバーするように広がる
• ()の領域を過大評価するようになる
32. 2010/3/7 PRML読書会 第12回 32
10.1.3 例: 一変数ガウス分布
• ガウス分布から発生した観測値のデータ = *1 , … , +が
与えられたとする
• 尤度関数 :
/2 2
, = exp − −
2 2
• このときパラメータの事後分布 , (|)を求めたい
• パラメータに関しても共役事前分布を導入する
= 0 , 0 −1
() = Gam(0 , 0 )
33. 2010/3/7 PRML読書会 第12回 33
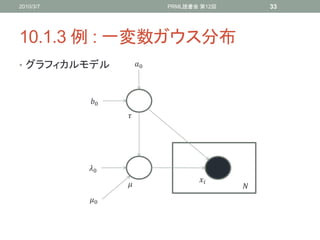
10.1.3 例 : 一変数ガウス分布
• グラフィカルモデル 0
0
0
0
34. 2010/3/7 PRML読書会 第12回 34
変分近似
• この問題に関しては、厳密な事後分布が求まる(演習 2.44)
• ここでは説明のために変分近似を考える
• 事後分布を分解した変分近似で近似する
, = ()
• 分解された各分布に関しては何の仮定も設けない!
35. 2010/3/7 PRML読書会 第12回 35
()の最適解
• (10.9)に同時分布を代入すると
∗
ln = ,ln , + ln - +const
2 2
= − 0 − 0 + − + const
2
となる。ここで , , = , ()を使った。
• 上の式はに関して二次式となるので はガウス分布になる。
• 平方完成して平均と分散を計算すると
= (| , −1 )
0 0 +
= , = 0 + ,-
0 +
36. 2010/3/7 PRML読書会 第12回 36
()の最適解
• ()のときと同様に
∗
ln = ln , + ln + ln + const
+ 1
= 0 − 1 ln − 0 + ln
2
− − 2 + 0 − 0 2 + const
2
• この式は ln − + の形となっており、ガンマ分布に従う
• 式を整理すると
= Gam(| , )
+ 1
= 0 +
2
1 2 2
= 0 + − + 0 − 0
2
37. 2010/3/7 PRML読書会 第12回 37
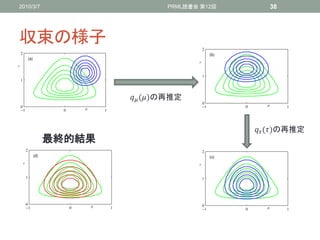
最適解について
• 今分解した分布について何の仮定もしていなかったのにも関
わらず、ガウス分布やガンマ分布がでてきた
• これは偶然ではなく、分布が指数型分布族+事前分布が共役事前分布
ならば自然に導かれる(Section 10.4.1)
• , ()はお互いのモーメントに依存しているため、以下
のようにして解く
1. の初期値を推定
2. ()を,-を用いて再計算
3. , , 2 -を計算
4. ()を再計算
5. 収束するまで2-4を繰り返す
38. 2010/3/7 PRML読書会 第12回 38
収束の様子
()の再推定
()の再推定
最終的結果
39. 2010/3/7 PRML読書会 第12回 39
解析解について
• 今の問題に関しては連立方程式を解くことによって解析的に
解くことができる
• 簡単のために無情報事前分布0 = 0 = 0 = 0 = 0を用い
る
1
= , 2 = 2 +
1
= 2 − 2
1 2
= −
40. 2010/3/7 PRML読書会 第12回 40
10.1.4 モデル比較
• 隠れ変数の推論の他に事前確率()を持つ複数のモデル
の比較をしたい場合もある
• 例えばLDAではトピック数
• (|)を近似する
• 異なるモデルは異なる内部構造を持つため、単純に事後分布
を(, ) = ()()と近似はできない。
• , = ()とモデルに依存した形で分解する必
要がある
41. 2010/3/7 PRML読書会 第12回 41
モデル比較
• , = ()の形の変分事後分布に関して
,
ln = − ln
(, , )
= ln
となる
• ここでを()に関して最大化すると
∝ ()exp )
(
となる
,
= (|)ln
42. 2010/3/7 PRML読書会 第12回 42
関連資料
• D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent Dirichlet
Allocation. JMLR, 2003
• 樺島祥介, 上田修功. 統計科学のフロンティア 11 計算統計I-
確率計算の新しい手法 第III部, 岩波書店, 2003
• Y. W. Teh, D. Newman and M. Welling. A Collapsed
Variational Bayesian Inference Algorithm for Latent
Dirichlet Allocation. NIPS, 2006
























































![[DL輪読会]GANとエネルギーベースモデル](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar20200828-210519065921-thumbnail.jpg?width=640&height=640&fit=bounds)












































