Download as PDF, PPTX












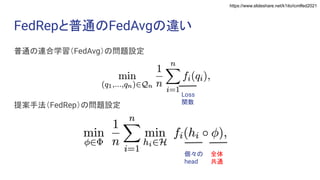


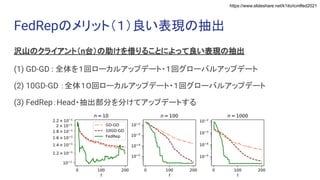
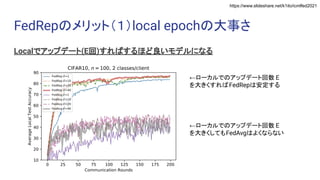
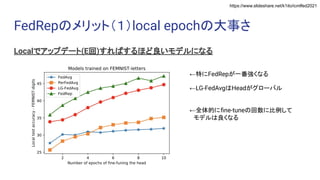







Exploiting Shared Representations for Personalized Federated Learning (ICML 2021) https://arxiv.org/abs/2102.07078 キーワード:連合学習・表現学習 Heterogeneity for the Win: One-Shot Federated Clustering (ICML 2021) https://arxiv.org/abs/2103.00697 キーワード:教師なし・one-shot・連合学習



![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)





















