異 常 ラベ ル 付 き デ ー タ に お け る ネ イ マ ン ・ ピ ア ソ ン 決 定 則
N e y m a n - P e a r s o n D e c i s i o n R u l e i n S u p e r v i s e d A n o m a l y D e t e c t i o n
<問題設定>
M次元のベクトル𝒙が,異常かどうかのラベル𝑦 と共に
N個の訓練データ𝒟として観測されていたとする.
𝒟 = 𝒙 1
, 𝑦 1
, 𝒙 2
, 𝑦 2
, … … , 𝒙 𝑛
, 𝑦 𝑛
この時,新たに観測された𝒙’が異常かどうかを判別したい
<考え方>
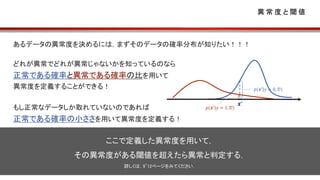
訓練データ𝒟より,異常時と正常時それぞれの確率分布を得る.
𝑝(𝒙′
|𝑦 = 0, 𝒟)よりも𝑝(𝒙′
|𝑦 = 1, 𝒟)の方が優勢であれば異常
と判定するので異常度𝑎 𝒙′
を以下のように定義する
𝑎 𝒙′ = ln
𝑝(𝒙′|𝑦 = 1, 𝒟)
𝑝(𝒙′|𝑦 = 0, 𝒟)
*ちなみにこの異常度の定義は,ある一定の正答率においてヒット率を最大にする
ネイマン・ピアソン決定則
𝑎 𝒙′
= ln
𝑝(𝒙′|𝑦=1,𝒟)
𝑝(𝒙′|𝑦=0,𝒟)
が所定の閾値を超えたら𝑦 = 1
𝒙’
𝑝(𝒙′
|𝑦 = 0, 𝒟)
𝑝(𝒙′
|𝑦 = 1, 𝒟)
イメージ
10.
異 常 ラベ ル な し デ ー タ に お け る ネ イ マ ン ・ ピ ア ソ ン 決 定 則
N e y m a n - P e a r s o n D e c i s i o n R u l e i n U n s u p e r v i s e d A n o m a l y D e t e c t i o n
<問題設定>
M次元のベクトル𝒙が, N個の訓練データ𝒟として観測されているとする.
このうち異常標本数は圧倒的少数であると信じられる必要がある.
𝒟 = 𝒙 1
, 𝒙 2
, … … , 𝒙 𝑛
この時,新たに観測された𝒙’が異常かどうかを判別したい
<考え方>
訓練データ𝒟より,正常時の確率分布を得る.
• 正常時に出現確率が低いものは異常度が高い,高いものは異常度が低いこと
また,情報理論の観点から
• 異常度が高いと得られる情報量は高い,低いと得られる情報量は低い
情報量は確率分布の負の対数と結びつけて考えられる
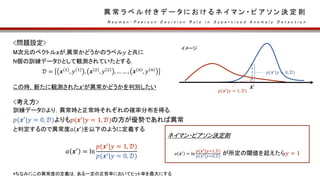
これより,異常度𝑎 𝒙′ を以下のように定義できる
𝑎 𝒙′
= −ln 𝑝(𝒙′
|𝒟)
ネイマン・ピアソン決定則
𝑎 𝒙′
= −ln 𝑝(𝒙′
|𝒟)が所定の閾値を超えたら𝑦 = 1
𝒙’
𝑝(𝒙′
|𝒟)
分 岐 点精 度 と F 値
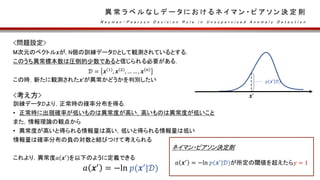
正答率とヒット率は,閾値の設定によって大きく左右される
右図のように閾値に対して正答率𝑟0とヒット率𝑟1をグラフにした際,
2つの交点を性能分岐点という.
この閾値においては,(正答率𝑟0)=(ヒット率𝑟1)が成り立つ
実用上は,性能分岐点を求める代わりに𝑟0と𝑟1の調和平均𝑓を
閾値や,何らかのパラメータに対し幾つか計算する.
その中で最大の𝑓を与える点を分岐点精度とする.
その点における𝑓をF値と呼ぶ
B r e a k - e v e n A c c u r a c y a n d F - s c o r e
正答率
ヒット率
分岐点精度
分岐点閾値
𝑓 =
2𝑟0 𝑟1
𝑟0 + 𝑟1
性能分岐点
13.
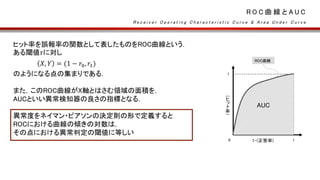
ヒット率を誤報率の関数として表したものをROC曲線という.
ある閾値𝜏に対し
𝑋, 𝑌 =(1 − 𝑟0, 𝑟1)
のようになる点の集まりである.
また,このROC曲線がX軸とはさむ領域の面積を,
AUCといい異常検知器の良さの指標となる.
異常度をネイマン・ピアソンの決定則の形で定義すると
ROCにおける曲線の傾きの対数は,
その点における異常判定の閾値に等しい
R O C 曲 線 と A U C
R e c e i v e r O p e r a t i n g C h a r a c t e r i s t i c C u r v e & A r e a U n d e r C u r v e
1
1
0 1-(正答率)
(
ヒ
ッ
ト
率
)
AUC
ROC曲線
多 変 量正 規 分 布
ホテリングの𝑇2
法では,
データが,異常標本を含まないか圧倒的少数であるという前提のもと,(今までと同じ)
各標本が独立に次のような正規分布に従うと仮定する
𝒩 𝒙 𝝁, Σ =
Σ −
1
2
2 𝜋
𝑀
2
exp
−1
2
𝒙 − 𝝁 ⊺ Σ −1 𝒙 − 𝝁
また, 𝝁, Σをデータ𝒟から求めるために,以下の𝒟の対数尤度ℒ 𝝁, Σ 𝒟 を用いて
最尤推定を行う.
ℒ 𝝁, Σ 𝒟 = ln
𝑛=1
𝑁
𝒩 𝒙(n) 𝝁, Σ =
𝑛=1
𝑁
ln 𝒩 𝒙(n) 𝝁, Σ
M u l t i v a r i a t e n o r m a l d i s t r i b u t i o n
Σ:共分散行列
𝝁:平均
16.
( 参 考) 最 尤 推 定
対数尤度の式
ℒ 𝝁 , Σ 𝒟 = ln
𝑛=1
𝑁
𝒩 𝒙 ( n )
𝝁 , Σ =
𝑛=1
𝑁
ln 𝒩 𝒙 ( n )
𝝁 , Σ
多変量正規分布の式を代入すると
ℒ 𝝁 , Σ 𝒟 =
−𝑀𝑁
2
ln 2π −
𝑁
2
ln Σ −
1
2
𝑛=1
𝑁
𝒙 ( n )
− 𝝁
⊺
Σ − 1
𝒙 ( n )
− 𝝁
この対数尤度の式を𝝁 , Σ を動かすことによって最大化する. 𝝁 で微分して0とする.
𝜕ℒ 𝝁 , Σ 𝒟
𝜕𝝁
=
1
2
𝑛=1
𝑁
Σ − 1
𝒙 ( n )
− 𝝁
すると,
𝝁 =
1
𝑁
𝑛−1
𝑁
𝒙(n)
Σ ≡
1
𝑁
𝑛=1
𝑁
𝒙 ( n )
− 𝝁 𝒙 ( n )
− 𝝁
⊺
M a x i m u m L i k e l i h o o d E s t i m a t i o n
17.
マ ハ ラノ ビ ス 距 離
前項で求めた,最尤推定量を代入することで,確率密度関数が得られる.
𝑝 𝒙 𝒟 = 𝒩 𝒙 𝝁, Σ
そこで,異常度をここから定義すると
𝑎 𝒙′ = (𝒙′ − 𝝁)⊺Σ −1(𝒙′ − 𝝁)
この式は,観測データが平均からどれだけずれているかを表したものである.
これをマハラノビス距離という.
共分散行列の逆行列Σ −1をかけることによって,
ばらつきが大きい方向の変動は大目にみているわけです
M a h a l a n o b i s D i s t a n c e
18.
ホ テ リン グ の 𝑇 2
法
𝑀次元正規分布𝒩 ( 𝝁, Σ)からの𝑁個の独立標本 𝒙 1
, 𝒙 2
, … … , 𝒙 𝑛
に基づき, 𝝁
とΣを定義する.
新たに𝒩 ( 𝝁, Σ)から独立標本 𝒙′
を新たに観測した時に,以下が成立する
1. 𝒙′
− 𝝁は平均0,共分散
𝑁+1
𝑁
Σの𝑀次元正規分布に従う.
2. Σは𝒙′
− 𝝁と統計的に独立である
3. 𝑇2 ≡
𝑁−𝑀
𝑁+1 𝑀
𝑎 𝒙′
により定義される統計量𝑇2は,自由度 𝑀, 𝑁 − 𝑀 のF分
布に従う.
4. 𝑁 >> 𝑀のとき,𝑎 𝒙′ は近似的に自由度𝑀,スケール因子1の𝜒2分布に従
う
H o t e l l i n g ’ s T ^ 2
←最尤推定
←𝑎 𝒙′
=
(𝒙′
− 𝝁 )⊺
Σ −1
(𝒙′
− 𝝁 )
多 項 分布 に お け る 単 純 ベ イ ズ 分 類
迷惑メールを振り分けるのに使われているのが,多項分布を用いた異常検知
これは単語や売れたものごとの「出現頻度」に着目する.
ある要素𝑖の出現確率を𝜃𝑖とし, 𝑖=1
𝑀
𝜃𝑖 = 1となるという前提のもと,この確率分布は
Mult 𝑥 𝜽 =
(𝑥1 + 𝑥2 + ⋯ + 𝑥 𝑀)
𝑥1! 𝑥2! … 𝑥 𝑀!
𝜃1
𝑥1
… 𝜃 𝑀
𝑥 𝑀
まずは,ここから𝑦ごとに𝑥の分布を求める.
𝑦 = 0と1に対応して,Mult 𝑥 𝜽 𝟎
とMult 𝑥 𝜽 𝟏
を仮定し,パラメータに対しそれぞれ最尤推定を行う.
ℒ 𝜽0
, 𝜽1
|𝒟 =
𝑛∈𝒟1 𝑖=1
𝑀
𝑥𝑖
(𝑛)
ln 𝜽𝑖
1
+
𝑛∈𝒟0 𝑖=1
𝑀
𝑥𝑖
(𝑛)
ln 𝜽𝑖
0
+ (定数)
N a i v e B a y e s C l a s s i f i c a t i o n w i t h M u l t i n o m i a l D i s t r i b u t i o n
























![集中不等式のすすめ [集中不等式本読み会#1]](https://cdn.slidesharecdn.com/ss_thumbnails/concentrationintro-150128034517-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)











































