Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
WK
Uploaded by
Wataru Kishimoto
1,725 views
Bishop prml 9.3_wk77_100408-1504
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 31 times
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PDF
PRML復々習レーン#14 ver.2
by
Takuya Fukagai
PDF
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
PDF
Prml 10 1
by
正志 坪坂
PDF
prml_titech_9.0-9.2
by
Taikai Takeda
PDF
PRML chap.10 latter half
by
Narihira Takuya
PDF
Oshasta em
by
Naotaka Yamada
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PRML復々習レーン#14 ver.2
by
Takuya Fukagai
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
Prml 10 1
by
正志 坪坂
prml_titech_9.0-9.2
by
Taikai Takeda
PRML chap.10 latter half
by
Narihira Takuya
Oshasta em
by
Naotaka Yamada
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
What's hot
PDF
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
PPTX
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PDF
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PDF
PRML 6.4-6.5
by
正志 坪坂
PDF
Fisher線形判別分析とFisher Weight Maps
by
Takao Yamanaka
PDF
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning)
by
Toshiyuki Shimono
PDF
はじめてのパターン認識輪読会 10章後半
by
koba cky
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
13.2 隠れマルコフモデル
by
show you
PDF
PRML復々習レーン#3 前回までのあらすじ
by
sleepy_yoshi
PDF
ベイズ統計入門
by
Miyoshi Yuya
PPTX
Gmm勉強会
by
Hayato Ohya
PDF
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PDF
PRML復々習レーン#2 2.3.6 - 2.3.7
by
sleepy_yoshi
PDF
PRML復々習レーン#3 3.1.3-3.1.5
by
sleepy_yoshi
PDF
PRML 8.4-8.4.3
by
KunihiroTakeoka
PDF
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PDF
PRML輪読#6
by
matsuolab
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PRML 6.4-6.5
by
正志 坪坂
Fisher線形判別分析とFisher Weight Maps
by
Takao Yamanaka
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning)
by
Toshiyuki Shimono
はじめてのパターン認識輪読会 10章後半
by
koba cky
PRML第6章「カーネル法」
by
Keisuke Sugawara
13.2 隠れマルコフモデル
by
show you
PRML復々習レーン#3 前回までのあらすじ
by
sleepy_yoshi
ベイズ統計入門
by
Miyoshi Yuya
Gmm勉強会
by
Hayato Ohya
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PRML復々習レーン#2 2.3.6 - 2.3.7
by
sleepy_yoshi
PRML復々習レーン#3 3.1.3-3.1.5
by
sleepy_yoshi
PRML 8.4-8.4.3
by
KunihiroTakeoka
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PRML輪読#6
by
matsuolab
Similar to Bishop prml 9.3_wk77_100408-1504
PDF
PRML輪読#9
by
matsuolab
PDF
PRML 9章
by
ぱんいち すみもと
PDF
パターン認識 04 混合正規分布
by
sleipnir002
PDF
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PDF
PRML2.1 2.2
by
Takuto Kimura
PDF
PRML 2.3.9-2.4.1
by
marugari
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PPTX
PRML読み会第一章
by
Takushi Miki
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PPTX
Prml 最尤推定からベイズ曲線フィッティング
by
takutori
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
Prml 1.2,4 5,1.3|輪講資料1120
by
Hayato K
PDF
PRML セミナー
by
sakaguchi050403
PDF
Prml sec6
by
Keisuke OTAKI
PDF
情報幾何勉強会 EMアルゴリズム
by
Shinagawa Seitaro
PDF
Draftall
by
Toshiyuki Shimono
PRML輪読#9
by
matsuolab
PRML 9章
by
ぱんいち すみもと
パターン認識 04 混合正規分布
by
sleipnir002
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PRML2.1 2.2
by
Takuto Kimura
PRML 2.3.9-2.4.1
by
marugari
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PRML読み会第一章
by
Takushi Miki
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
Prml 最尤推定からベイズ曲線フィッティング
by
takutori
PRML10-draft1002
by
Toshiyuki Shimono
Prml 1.2,4 5,1.3|輪講資料1120
by
Hayato K
PRML セミナー
by
sakaguchi050403
Prml sec6
by
Keisuke OTAKI
情報幾何勉強会 EMアルゴリズム
by
Shinagawa Seitaro
Draftall
by
Toshiyuki Shimono
Bishop prml 9.3_wk77_100408-1504
1.
C.M.ビショップ
「パターン認識と機械学習 (PRML)」 読書会 § 9.3 EM アルゴリズムのもう一つの解釈 PRML § 9.3 p. 1
2.
§ 9.3 EM
アルゴリズムのもう一つの解釈 • § 9.3 の構成 - 周辺化して得られる不完全データの尤度関数は陽に解けず、 観測データからは完全データの尤度関数の値が得られない - EM アルゴリズムが、完全データの尤度関数の 潜在変数の事後分布に関する期待値を計算し、 その期待値を最大化する過程であると解釈する • 詳細な理由の説明は § 9.4 で行われる • 以下具体的な分布に適用してそのことを確認する - § 9.3.1 混合ガウス分布再訪 - § 9.3.2 K-means との関連 - § 9.3.3 混合ベルヌーイ分布 - § 9.3.4 ベイズ線形回帰に関する EM アルゴリズム PRML § 9.3 p. 2
3.
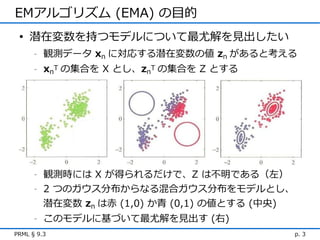
EMアルゴリズム (EMA) の目的
• 潜在変数を持つモデルについて最尤解を見出したい - 観測データ xn に対応する潜在変数の値 zn があると考える - xnT の集合を X とし、znT の集合を Z とする - 観測時には X が得られるだけで、Z は不明である(左) - 2 つのガウス分布からなる混合ガウス分布をモデルとし、 潜在変数 zn は赤 (1,0) か青 (0,1) の値とする (中央) - このモデルに基づいて最尤解を見出す (右) PRML § 9.3 p. 3
4.
潜在変数のある対数尤度関数の性質 • 最大化したい対数尤度関数は次の式で与えられる
ln p(X|θ) = ln {Σz p(X,Z|θ)} - Z が連続変数ならば、和を積分に置き換えればよい • 同時分布 p(X,Z|θ) が指数型分布族に属していても、 周辺分布 p(X|θ) は Z に関する和のために、 普通は指数型分布族にならない - ln (exp f1(z1) × exp f2(z2)) = f1(z1) + f2(z2) - ln (exp f1(z1) + exp f2(z2)) → 複雑な形 PRML § 9.3 p. 4
5.
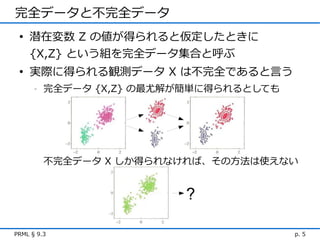
完全データと不完全データ • 潜在変数
Z の値が得られると仮定したときに {X,Z} という組を完全データ集合と呼ぶ • 実際に得られる観測データ X は不完全であると言う - 完全データ {X,Z} の最尤解が簡単に得られるとしても 不完全データ X しか得られなければ、その方法は使えない ? PRML § 9.3 p. 5
6.
完全データ対数尤度関数の期待値を最大化する • 潜在変数
Z についての知識は、 潜在変数の事後分布 p(Z|X,Θ) によるものだけである • ln p(X|θ) は周辺化のため最尤解が複雑な形となり、 ln p(X,Z|θ) はデータが不完全なので求まらない • EMA では、完全データ対数尤度関数 ln p(X,Z|θ) の 潜在変数の事後分布に関する期待値 Q を最大化する - Eステップ: Q(θ,θold) = Σz p(Z|X,θold) ln p(X,Z|θ) • 対数は完全データの同時分布(指数族)に直接作用できる - Mステップ: θnew = argmax(θ) Q(θ,θold) PRML § 9.3 p. 6
7.
一般の EM アルゴリズム
1. パラメータの初期値 θold を選ぶ 2. E ステップ: p(Z|X,θold) を計算する 3. M ステップ: 次式で与えられる θnew を計算する θnew = argmax(θ) Q(θ,θold) ただし Q(θ,θold) = Σz p(Z|X,θold) ln p(X,Z|θ) 4. 対数尤度関数またはパラメータ値の いずれかについて、収束条件を満たすかどうか調べる 満たされていなければ、 θold ← θnew を実行し、ステップ2に戻る PRML § 9.3 p. 7
8.
EM アルゴリズムによる MAP
解の推定 • MAP (最大事後確率推定 maximum-a-posterior) 解 - パラメータの事前分布 p(θ) が定義されたモデルで、 データ集合 X を観測した下での事後分布 p(θ|X) を最大化 - ベイズの定理から p(θ|X) ∝ p(X|θ) p(θ) なので、 最大化する尤度関数は ln p(θ|X) = ln p(X|θ) + ln p(θ) + const と表せる - ln p(X|θ) の最大化は Q の最大化に等しいので、 M ステップにおいて Q + ln p(θ) を最大化すればよい - Q は p(θ) に依存しないので、 E ステップにおいては元の Q の値を計算すればよい • 事前分布 p(θ) の適切な設定により、 図 9.7 の特異性を取り除くことができる PRML § 9.3 p. 8
9.
データ集合中の欠損値を非観測変数とみなす場合 • 観測値の分布は、すべての変数に関する同時分布を
求めて、欠損値について周辺化することで得られる - 対応する尤度関数を最大化するのに EMA を使える - データの値がランダム欠損している場合に有効である • 観測値が失われる原因が非観測データの値によらない • 現実には非観測データの値に依存することが多い - 図 12.11 は、主成分分析の文脈での適用例である • 右のプロットは変数値の 30% をランダム欠損させ EMA 法であつかったもの • 欠損値のない方の 左のプロットと 非常によく似ている PRML § 9.3 p. 9
10.
§ 9.3.1 混合ガウス分布再訪
• 潜在変数による EM アルゴリズムの見方を 混合ガウスモデルの場合に適用して考察する - 潜在変数 zn は 1-of-K 符号化法による離散変数 • K 通りの値をとり、 要素のうち 1 つだけが 1 で、残りは 0 のベクトル • K=3 であれば (1,0,0) (0,1,0) (0,0,1) の 3 通りの値 • znk は zn の k 番目の要素を表す • N 個の観測データの同時分布 p(X,Z|μ,Σ,π) = ΠnN ΠkK πkz N(xn|μk,Σk)z nk nk • 完全データ対数尤度関数は次の形となる ln p(X,Z|μ,Σ,π) = ΣnN ΣkK znk {ln πk + ln N(xn|μk,Σk)} - 対数は指数型分布族であるガウス分布に直接作用している PRML § 9.3 p. 10
11.
混合ガウス分布の事後分布 • ラグランジュ未定乗数法により混合係数
πk が求まる πk = (1/N) ΣnN znk ex) z1~z3=(1, 0)T, z4~z10=(0, 1)T → π=(0.3, 0.7)T - 対応する要素に割り当てられたデータ点数の割合となる - (9.21) 式において両辺に πk をかけて k について総和 0 = ΣnN 1 + ΣkK πk λ = N + λ → λ=-N πkN = ΣnN γ(znk) = Nk → πk = N k / N • 完全データ対数尤度関数の最大化は陽な形で解ける - 完全データは得られないので尤度関数の値は計算できない - 事後分布をベイスの定理を利用して求める p(Z|X,μ,Σ,π) ∝ p(X|Z,μ,Σ)p(Z|π) p(Z|X,μ,Σ,π) ∝ ΠnN ΠkK [πk N(xn|μk,Σk)]z nk - 右辺は n について積の形 → {zn} は独立 PRML § 9.3 p. 11
12.
混合ガウス分布の完全データ尤度関数の期待値 • 事後分布に関する指示変数
znk の期待値を求める - k 番目のガウス分布の、データ点 xn に対する負担率と同じ • 完全データ尤度関数(再掲) ln p(X,Z|μ,Σ,π) = ΣnN ΣkK znk {ln πk + ln N(xn|μk,Σk)} • 完全データ尤度関数の事後分布についての期待値 Ez[ln p(X,Z|μ,Σ,π)] = ΣnN ΣkK E[znk] {ln πk + ln N(xn|μk,Σk)} = ΣnN ΣkK γ(znk) {ln πk + ln N(xn|μk,Σk)} PRML § 9.3 p. 12
13.
混合ガウス分布に関する EMA の再確認
• μold, Σold, πold から負担率 γ(znk) を計算する • 負担率 γ(znk) を固定した上での期待値 Ez = ΣnN ΣkK γ(znk) {ln πk + ln N(xn|μk,Σk)} ただし、 = - (1/2) ΣnN ΣkK γ(znk) (xn - μk)TΣ-1(xn - μk) + const を、μk, Σk, πk について最大化し、更新則の陽な解を導く • Nk = ΣnN γ(znk), μknew = (1 / Nk) ΣnN γ(znk) xn ∂Ez / ∂μk = - ΣnN γ(znk) Σ-1(μk – xn) = 0 Σ を掛けて整理 ΣnN γ(znk) μk = Nk μk = ΣnN γ(znk) xn • Σknew = (1 / Nk) ΣnN γ(znk) (xn - μk)(xn – μk)T ∂Ez / ∂Σk = 0 から、式 (2.112) と演習 2.34 解答を参照 • πknew = Nk / N γ(znk) 固定で ΣnN γ(znk) (1 / πk) + λ = 0, λ = -N PRML § 9.3 p. 13
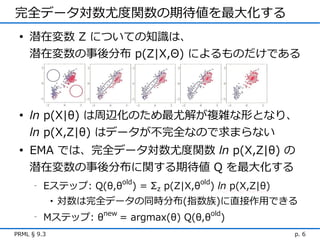
14.
§ 9.3.2 K-means
との関連 • K-means 法と混合ガウス分布の EMA を比較すると 強い類似性が明らかになる • 各々のデータ点が - K-means 法ではただ一つのクラスタに割り当てられる (左) - EMA では事後確率に基づきソフトに割り当てられる (右) • 混合ガウス分布に関する EMA のある極限として K-means 法を導けることを説明する PRML § 9.3 p. 14
15.
EMA から K-means
を導く • 各ガウス要素の共分散行列が εI で与えられるとする - ε は全てのガウス分布が共有する、固定した定数とする • 事後確率、すなわちデータ点 xn に関する k 番目の混合要素の負担率 γ(znk) は以下の式となる - ||xnー μj||2 が最小になる j を j* とおき、ε → 0 の極限をとる - 分母において j* に対応する項が、最も遅く 0 に近づく - 分子においても k = j* となる(分子と分母の式が一致する形になる) γ(znj*) のみが 1 に収束し、他の γ(znk) は 0 に収束する - このことは、πk がどれも非零である限り、πk の値に依存せず成立する - 負担率 γ(znk) が 1 か 0 というハードな割り当てとなる PRML § 9.3 p. 15
16.
ε → 0
における完全データ対数尤度の期待値 • ε → 0 における完全データ対数尤度の期待値 Ez = - (1/2) ΣnN ΣkK γ(znk) ||xn - μk||2 + const rnk = (k == argmin(j)||xn - μj||) ? 1 : 0, ∴ γ(znk)→rnk Ez = - (1/2) ΣnN ΣkK rnk ||xn - μk||2 + const • この期待値の最大化は、K-means における歪み尺度 J = ΣnN ΣkK rnk ||xnー μk||2 の最小化に等しい • K-means ではクラスタの分散を推定せず、 平均のみを推定していることに注意する - (参考) 一般の共分散行列をもつハード割り当て版の 混合ガウスモデルに関する EMA は 楕円 K-means アルゴリズムと呼ばれる PRML § 9.3 p. 16
17.
§ 9.3.3 混合ベルヌーイ分布
• 混合モデルの別の例として、 ベルヌーイ分布で表される 2 値の変数の混合を扱う - 別の文脈での EM アルゴリズムの説明となる - 潜在クラス分析としても知られる - 離散変数に関する隠れ Markov モデルの基礎になる • 0 もしくは 1 の値をとる D 個の変数 xi (i = 1,...,D) が それぞれ期待値 μi のベルヌーイ分布に従うとする p(x|μ) = ΠiD μix (1 – μi)(1 – x ) i i ただし x = (x1,...,xD)T, μ = (μ1,...,μD)T • p(xi = 1|μi) = μi , p(xi = 0|μi) = 1 – μi - μ が与えられているとき各変数 xi は独立 - 期待値 E[x] = μ 共分散行列 cov[x] = diag {μi (1 - μi)} PRML § 9.3 p. 17
18.
ベルヌーイ分布の有限混合分布 • ベルヌーイ分布の有限個の混合分布をモデルとする
- p(x|μ,π) = ΣkK πk p(x|μk) (πk は k 番目の混合要素の混合率) p(x|μk) = ΠiD μkix (1 – μki)(1 - x ) i i - μ = {μ1,...,μK}, π = {π1,...,πK} を EMA で推定する • 後述の例では添字 i が画素のインデックスに相当する 600 牧の画像データ n 番目の画像 xn の i 番目の画素が xni K = 3 個のベルヌーイ分布の混合をモデルとして EMA を実行 10 回反復して得られた k 番目のベルヌーイ分布の i 番目の画素に対応する パラメータ μki PRML § 9.3 p. 18
19.
混合ベルヌーイ分布の期待値と共分散行列 (1) •
期待値と共分散行列は次式で与えられる - 期待値 E[x] = ΣkK πk μk - 共分散 cov[x] = ΣkK πk ( Σk + μkμkT ) - E[x]E[x]T ただし Σk = diag { μki (1 - μki) } - 求める過程は次頁に記述 • 共分散行列 cov[x] はもはや対角行列ではなく、 変数間に相関があることがわかる PRML § ৯.৩ p. ১৯
20.
混合ベルヌーイ分布の期待値と共分散行列 (2) •
k 番目の単一のベルヌーイ分布の性質再掲 - 期待値 Ek[x] = μk - 共分散 Σk = Ek[xxT] – Ek[x]Ek[x]T = Ek[xxT] – μkμkT = diag {μki (1 – μki)} - Ek[xxT] = Σk + μkμkT であることを後で利用する • 混合ベルヌーイ分布の定義から - 期待値 E[x] = ΣkK πk Ek[x] = ΣkK πk μk - 共分散 cov[x] = E[xxT] – E[x]E[x]T = ΣkK πk Ek[xxT] – E[x]E[x]T = ΣkK πk ( Σk + μkμkT ) – E[x]E[x]T PRML § ৯.৩ p. ২০
21.
混合ベルヌーイ分布に関する EMA の準備
• 観測データ集合 X = {x1,...,xN} の対数尤度関数 ln p(x|μ,π) = ΣnN ln { ΣkK πk p(xn|μk) } - 対数の中に総和が現れているので、最尤解は陽に解けない • 混合ベルヌーイ分布に潜在変数 z を導入する - K 通りの値をとる 1-of-K 符号化法による離散変数 z={zk} (k=1,...,K) - 複数の xn があるとき、それぞれに zn={znk} (n=1,...,N) が付随する - 潜在変数 z の値が与えられた下で、x の条件付き確率分布は p(x|z,μ) = ΠkK p(x|μk)z k - 潜在変数 z についての事前分布は、混合ガウスモデルと同様に p(z|π) = ΠkK πkz k ( p(zk=1) = πk の別の表現。ΣkK πk = 1) • 潜在変数 z について周辺化すると元の分布と一致する p(x|μ,π) = Σz p(x|z,μ)p(z|π) = Σz ΠkK {πk p(x|μk)}z k = ΣjK ΠkK {πk {ΠiD μkix (1 – μki)(1 - x )}}I , ただし{Ikj}=(k==j)?1:0 i i kj = ΣjK πj ΠiD μjix (1 – μji)(1 - x ) = ΣjK {πj p(x|μj)} = p(x|μ,π) i i PRML § ৯.৩ p. ২১
22.
混合ベルヌーイ分布の尤度関数と期待値 • 完全データ対数尤度関数を書き下す
p(X,Z|μ,π) = ΠnN p(xn,zn|μn,π) = ΠnN p(xn|zn,μn)p(zn|π) = Π nN { ΠkK { ΠiD μkix (1 – μki)(1 - x )}z ・ΠkK πkz ni ni nk nk } = ΠnN ΠkK { πk ΠiD μkix (1 – μki)(1 - x )}z ni ni nk ∴ ln p(X,Z|μ,π) = ΣnN ΣkK znk {lnπk + ΣiD [xni lnμki + (1-xni) ln(1-μki)]} • 事後分布に沿った完全データ対数尤度関数の期待値 EZ[ln p(X,Z|μ,π)] = ΣnN ΣkK E[znk] {lnπk + ΣiD [xni lnμki + (1-xni) ln(1-μki)]} = ΣnN ΣkK γ(znk) {lnπk + ΣiD [xni lnμki + (1-xni) ln(1-μki)]} - γ(znk) = E[znk] は k 番目の混合要素の事後確率、 すなわち負担率である(次項に式を書く) PRML § ৯.৩ p. ২২
23.
混合ベルヌーイ分布の EMA の
E ステップ • 負担率 γ(znk) をベイズの定理から計算し、 E ステップにおいてこの値を求める • 尤度関数の期待値の式において n に関する総和を見る EZ[ln p(X,Z|μ,π)] = ΣkK ln πk ΣnN γ(znk) + ΣkK ΣiD { ln μki - ln (1 – μki) } ΣnN γ(znk) xni + ΣkK ΣiD ln (1 – μki) ΣnN γ(znk) - 負担率 γ(znk) は次の 2 項に集約された形でのみ現れる Nk = ΣnN γ(znk) xk = (1 / Nk) ΣnN γ(znk) xn - Nk は k 番目の混合要素に割当られるデータ点の実効的な数 PRML § ৯.৩ p. ২৩
24.
混合ベルヌーイ分布の EMA の
M ステップ (1) • M ステップにおいては、完全データ対数尤度関数の 期待値 EZ をパラメータ μk と π について最大化する - EZ = ΣnN ΣkK γ(znk) {ln πk + ΣiD [xni ln μki + (1-xni) ln (1-μki)]} を μk に関する微分を 0 として整理する - ∂EZ[ln p(X,Z|μ,π)] / ∂μki = 0 ΣnN γ(znk) { xni / μki – (1 - xni) / (1 - μki) } = 0 { ΣnN γ(znk) xni – ΣnN γ(znk) μki } / μki (1 - μki) = 0 ∴ μki = Σn γ(znk) xni / Σn γ(znk) μk = xk • パラメータ μk については、k 番目の混合要素からの 負担率 γ(znk) を重み係数とした、 データ点 xn の重みつき平均に設定すればよい PRML § 9.3 p. 24
25.
混合ベルヌーイ分布の EMA の
M ステップ (2) • 混合ガウスの場合と同様の手順で πk を求める - πk に関する最大化には Σk πk = 1 を制約として ラグランジュ未定定数法を使う π k = Nk / N - Nk = ΣnN γ(znk) は k 番目の混合要素が負担するデータの実効的な数であり、 k 番目の要素の混合係数 πk が Nk に比例することは、 直感的に理解できる • 混合ガウス分布の場合と違い、混合ベルヌーイ分布は 尤度関数が発散する特異性は存在しない - 0 ≦ p(xn|μk) ≦ 1 であるため尤度関数は上に有界であり、 EMA は極大点に到達するまで尤度を増大し続けるので、 病的な初期値を設定しない限り、尤度が 0 になることはない PRML § 9.3 p. 25
26.
混合ベルヌーイモデルの手書き数字への適用 • しきい値
0.5 で 2 値画像化した数字画像 600 枚 • K 個のベルヌーイ分布の混合モデルで EMA を実行 - 左側は K = 3 個の混合として 10 回反復した後の μki の値 画素数 D として D 次元で 3 つのクラスタに分離 • - 右側は K = 1 すなわち単一のベルヌーイ分布による最尤解 • 各画素の値の単純な平均に等しく、意味のない推定 - 初期値は、混合係数 πk を 1 / K とし、パラメータ μki は 区間 (0.25, 0.75) の一様分布で発生させた後正規化する PRML § 9.3 p. 26
27.
§ 9.3.4 ベイズ線形回帰に関する
EM アルゴリズム • EMA の 3 番目の応用例として、 ベイズ線形回帰に関するエビデンス近似を再訪する - エビデンス関数 p(t|α,β) の α と β に関する最大化が目的 - § 3.5.2 超パラメータ α と β の再計算法 • エビデンスを計算し、得られた表現式の微分を 0 にする • エビデンス関数 p(t|α,β) = ∫ p(t|w,β) p(w|α) dw = (β/2π)N/2 (α/2π)M/2 ∫ exp { - E(w) } dw ただし E(w) = (β/2)|| t – Φw ||2 + (α/2) wTw - パラメータベクトル w は周辺化で消去されているので、 潜在変数とみなせる • EMA によってこの周辺尤度関数を最大化すればよい PRML § 9.3 p. 27
28.
エビデンス関数の期待完全データ対数尤度 • w
の事後分布に沿う完全データ対数尤度の期待値 - E ステップでは α と β の現在の値にもとづいて w の事後分布と、その期待完全データ対数尤度を求める - M ステップではこの量を α と β について最大化する • 完全データ対数尤度は次式で与えられる - ln p(t,w|α,β) = ln p(t|w,β) + ln p(w|α) - (3.7)~(3.12) により ln p(t|w,β) = (N/2) ln (β/2π) – (β/2) Σn { tn – wTΦ(xn) }2 - (3.52)~(3.56 で q=2 とおく) により ln p(w|α) = (M/2) ln (α/2π) – (α/2) wTw • したがって完全データ対数尤度の期待値は - E [ln p(t,w|α,β)] = (M/2) ln (α/2π) – (α/2) E [wTw] + (N/2) ln (β/2π) – (β/2) Σn E [ (tn – wTΦ)2 ] PRML § 9.3 p. 28
29.
M ステップの更新式を求める •
E [ln p(t,w|α,β)] = (M/2) ln (α/2π) – (α/2) E [wTw] + (N/2) ln (β/2π) – (β/2) Σn E [ (tn – wTΦ)2 ] • ∂E [ln p(t,w|α,β)] / ∂α = (M/2α) – (1/2) E [wTw] = 0 α = M / E [wTw] = M / { E [w]TE [w] + Tr(SN) } α = M / { mNTmN + Tr(SN) } - エビデンス近似では α = γ / mNTmN , (γ = M - αTr(SN)) • ∂E [ln p(t,w|α,β)] / ∂β = (N/2β) – (1/2) Σn E [ (tn – wTΦ)2 ] = 0 β = N / { Σn E [ (tn – wTΦ)2 ] } = N / { Σn { tn – E [w]TΦ }2 } β = N / { Σn { tn – mNTΦ }2 } - エビデンス近似では β = (N - γ) / { Σn { tn – mNTΦ }2 } PRML § 9.3 p. 29
30.
RVM への EM
アルゴリズムの適用 • RVM に EM アルゴリズムを適用する 潜在変数の事後分布に沿った完全データ尤度関数の期待値 - • 周辺尤度関数 p(t|α,β) = ∫ p(t|w,β) p(w|α) dw = (β/2π)N/2 (1/2π)M/2 ΠiM αi ∫ exp { - E(w) } dw = (β/2π)N/2 ΠiM αi { exp{ - E(t) } |Σ|1/2 } E(t) = (1/2) (βtTt – mTΣ-1m) , Σ = diag(α) + βΦTΦ • 周辺尤度関数の対数値について αi , β での偏微分を 0 とする ln p(t|α,β) = (1/2) { N ln β + ΣiN ln αi – 2E(t) - ln |Σ| - N ln (2π) } = (1/2) { N ln β + ΣiN ln αi – βtTt + mTΣ-1m - ln |Σ| - N ln (2π) } • ∂ ln p(t|α,β) / ∂αi = (1/2αi) – (1/2) Tr {Σ-1(∂Σ/∂αi)} – (1/2)mi2 = 0 αinew = 1 / (mi2 + Σii) • ∂ ln p(t|α,β) / ∂β = (1/2) (N/β - ||t – Φm||2 - Tr [ΣΦTΦ]) = 0 (βnew)-1 = (1 / N) ( ||t – Φm||2 + β-1 Σi γi ) PRML § 9.3 p. 30
31.
TODO メモ •
なぜ期待値 Q を最大化するのか (§ 9.4 の予習) • 混合ガウス分布の有向グラフ表現と有向分離 • § 9.3.4 の説明や演習の解答 • § 9.3.3 - § 9.3.4 のグラフィカルモデルによる説明 • それぞれの実装とテスト結果 PRML § 9.3 p. 31
Download







![混合ガウス分布の事後分布
• ラグランジュ未定乗数法により混合係数 πk が求まる
πk = (1/N) ΣnN znk
ex) z1~z3=(1, 0)T, z4~z10=(0, 1)T → π=(0.3, 0.7)T
- 対応する要素に割り当てられたデータ点数の割合となる
- (9.21) 式において両辺に πk をかけて k について総和
0 = ΣnN 1 + ΣkK πk λ = N + λ → λ=-N
πkN = ΣnN γ(znk) = Nk → πk = N k / N
• 完全データ対数尤度関数の最大化は陽な形で解ける
- 完全データは得られないので尤度関数の値は計算できない
- 事後分布をベイスの定理を利用して求める
p(Z|X,μ,Σ,π) ∝ p(X|Z,μ,Σ)p(Z|π)
p(Z|X,μ,Σ,π) ∝ ΠnN ΠkK [πk N(xn|μk,Σk)]z nk
- 右辺は n について積の形 → {zn} は独立
PRML § 9.3 p. 11](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-11-320.jpg)
![混合ガウス分布の完全データ尤度関数の期待値
• 事後分布に関する指示変数 znk の期待値を求める
- k 番目のガウス分布の、データ点 xn に対する負担率と同じ
• 完全データ尤度関数(再掲)
ln p(X,Z|μ,Σ,π)
= ΣnN ΣkK znk {ln πk + ln N(xn|μk,Σk)}
• 完全データ尤度関数の事後分布についての期待値
Ez[ln p(X,Z|μ,Σ,π)]
= ΣnN ΣkK E[znk] {ln πk + ln N(xn|μk,Σk)}
= ΣnN ΣkK γ(znk) {ln πk + ln N(xn|μk,Σk)}
PRML § 9.3 p. 12](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-12-320.jpg)



![§ 9.3.3 混合ベルヌーイ分布
• 混合モデルの別の例として、
ベルヌーイ分布で表される 2 値の変数の混合を扱う
- 別の文脈での EM アルゴリズムの説明となる
- 潜在クラス分析としても知られる
- 離散変数に関する隠れ Markov モデルの基礎になる
• 0 もしくは 1 の値をとる D 個の変数 xi (i = 1,...,D) が
それぞれ期待値 μi のベルヌーイ分布に従うとする
p(x|μ) = ΠiD μix (1 – μi)(1 – x )
i i
ただし x = (x1,...,xD)T, μ = (μ1,...,μD)T
• p(xi = 1|μi) = μi , p(xi = 0|μi) = 1 – μi
- μ が与えられているとき各変数 xi は独立
- 期待値 E[x] = μ 共分散行列 cov[x] = diag {μi (1 - μi)}
PRML § 9.3 p. 17](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-17-320.jpg)

![混合ベルヌーイ分布の期待値と共分散行列 (1)
• 期待値と共分散行列は次式で与えられる
- 期待値
E[x] = ΣkK πk μk
- 共分散
cov[x] = ΣkK πk ( Σk + μkμkT ) - E[x]E[x]T
ただし Σk = diag { μki (1 - μki) }
- 求める過程は次頁に記述
• 共分散行列 cov[x] はもはや対角行列ではなく、
変数間に相関があることがわかる
PRML § ৯.৩ p. ১৯](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-19-320.jpg)
![混合ベルヌーイ分布の期待値と共分散行列 (2)
• k 番目の単一のベルヌーイ分布の性質再掲
- 期待値 Ek[x] = μk
- 共分散 Σk = Ek[xxT] – Ek[x]Ek[x]T
= Ek[xxT] – μkμkT
= diag {μki (1 – μki)}
- Ek[xxT] = Σk + μkμkT であることを後で利用する
• 混合ベルヌーイ分布の定義から
- 期待値 E[x] = ΣkK πk Ek[x]
= ΣkK πk μk
- 共分散 cov[x] = E[xxT] – E[x]E[x]T
= ΣkK πk Ek[xxT] – E[x]E[x]T
= ΣkK πk ( Σk + μkμkT ) – E[x]E[x]T
PRML § ৯.৩ p. ২০](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-20-320.jpg)

![混合ベルヌーイ分布の尤度関数と期待値
• 完全データ対数尤度関数を書き下す
p(X,Z|μ,π) = ΠnN p(xn,zn|μn,π) = ΠnN p(xn|zn,μn)p(zn|π)
= Π nN { ΠkK { ΠiD μkix (1 – μki)(1 - x )}z ・ΠkK πkz
ni ni nk nk
}
= ΠnN ΠkK { πk ΠiD μkix (1 – μki)(1 - x )}z
ni ni nk
∴ ln p(X,Z|μ,π)
= ΣnN ΣkK znk {lnπk + ΣiD [xni lnμki + (1-xni) ln(1-μki)]}
• 事後分布に沿った完全データ対数尤度関数の期待値
EZ[ln p(X,Z|μ,π)]
= ΣnN ΣkK E[znk] {lnπk + ΣiD [xni lnμki + (1-xni) ln(1-μki)]}
= ΣnN ΣkK γ(znk) {lnπk + ΣiD [xni lnμki + (1-xni) ln(1-μki)]}
- γ(znk) = E[znk] は k 番目の混合要素の事後確率、
すなわち負担率である(次項に式を書く)
PRML § ৯.৩ p. ২২](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-22-320.jpg)
![混合ベルヌーイ分布の EMA の E ステップ
• 負担率 γ(znk) をベイズの定理から計算し、
E ステップにおいてこの値を求める
• 尤度関数の期待値の式において n に関する総和を見る
EZ[ln p(X,Z|μ,π)] = ΣkK ln πk ΣnN γ(znk)
+ ΣkK ΣiD { ln μki - ln (1 – μki) } ΣnN γ(znk) xni
+ ΣkK ΣiD ln (1 – μki) ΣnN γ(znk)
- 負担率 γ(znk) は次の 2 項に集約された形でのみ現れる
Nk = ΣnN γ(znk)
xk = (1 / Nk) ΣnN γ(znk) xn
- Nk は k 番目の混合要素に割当られるデータ点の実効的な数
PRML § ৯.৩ p. ২৩](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-23-320.jpg)
![混合ベルヌーイ分布の EMA の M ステップ (1)
• M ステップにおいては、完全データ対数尤度関数の
期待値 EZ をパラメータ μk と π について最大化する
- EZ = ΣnN ΣkK γ(znk) {ln πk + ΣiD [xni ln μki + (1-xni) ln (1-μki)]}
を μk に関する微分を 0 として整理する
- ∂EZ[ln p(X,Z|μ,π)] / ∂μki = 0
ΣnN γ(znk) { xni / μki – (1 - xni) / (1 - μki) } = 0
{ ΣnN γ(znk) xni – ΣnN γ(znk) μki } / μki (1 - μki) = 0
∴ μki = Σn γ(znk) xni / Σn γ(znk)
μk = xk
• パラメータ μk については、k 番目の混合要素からの
負担率 γ(znk) を重み係数とした、
データ点 xn の重みつき平均に設定すればよい
PRML § 9.3 p. 24](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-24-320.jpg)



![エビデンス関数の期待完全データ対数尤度
• w の事後分布に沿う完全データ対数尤度の期待値
- E ステップでは α と β の現在の値にもとづいて
w の事後分布と、その期待完全データ対数尤度を求める
- M ステップではこの量を α と β について最大化する
• 完全データ対数尤度は次式で与えられる
- ln p(t,w|α,β) = ln p(t|w,β) + ln p(w|α)
- (3.7)~(3.12) により
ln p(t|w,β) = (N/2) ln (β/2π) – (β/2) Σn { tn – wTΦ(xn) }2
- (3.52)~(3.56 で q=2 とおく) により
ln p(w|α) = (M/2) ln (α/2π) – (α/2) wTw
• したがって完全データ対数尤度の期待値は
- E [ln p(t,w|α,β)] = (M/2) ln (α/2π) – (α/2) E [wTw]
+ (N/2) ln (β/2π) – (β/2) Σn E [ (tn – wTΦ)2 ]
PRML § 9.3 p. 28](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-28-320.jpg)
![M ステップの更新式を求める
• E [ln p(t,w|α,β)] = (M/2) ln (α/2π) – (α/2) E [wTw]
+ (N/2) ln (β/2π) – (β/2) Σn E [ (tn – wTΦ)2 ]
• ∂E [ln p(t,w|α,β)] / ∂α = (M/2α) – (1/2) E [wTw] = 0
α = M / E [wTw] = M / { E [w]TE [w] + Tr(SN) }
α = M / { mNTmN + Tr(SN) }
- エビデンス近似では α = γ / mNTmN , (γ = M - αTr(SN))
• ∂E [ln p(t,w|α,β)] / ∂β =
(N/2β) – (1/2) Σn E [ (tn – wTΦ)2 ] = 0
β = N / { Σn E [ (tn – wTΦ)2 ] }
= N / { Σn { tn – E [w]TΦ }2 }
β = N / { Σn { tn – mNTΦ }2 }
- エビデンス近似では β = (N - γ) / { Σn { tn – mNTΦ }2 }
PRML § 9.3 p. 29](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-29-320.jpg)
![RVM への EM アルゴリズムの適用
• RVM に EM アルゴリズムを適用する
潜在変数の事後分布に沿った完全データ尤度関数の期待値
-
• 周辺尤度関数
p(t|α,β) = ∫ p(t|w,β) p(w|α) dw
= (β/2π)N/2 (1/2π)M/2 ΠiM αi ∫ exp { - E(w) } dw
= (β/2π)N/2 ΠiM αi { exp{ - E(t) } |Σ|1/2 }
E(t) = (1/2) (βtTt – mTΣ-1m) , Σ = diag(α) + βΦTΦ
• 周辺尤度関数の対数値について αi , β での偏微分を 0 とする
ln p(t|α,β) = (1/2) { N ln β + ΣiN ln αi – 2E(t) - ln |Σ| - N ln (2π) }
= (1/2) { N ln β + ΣiN ln αi – βtTt + mTΣ-1m - ln |Σ| - N ln (2π) }
• ∂ ln p(t|α,β) / ∂αi = (1/2αi) – (1/2) Tr {Σ-1(∂Σ/∂αi)} – (1/2)mi2 = 0
αinew = 1 / (mi2 + Σii)
• ∂ ln p(t|α,β) / ∂β = (1/2) (N/β - ||t – Φm||2 - Tr [ΣΦTΦ]) = 0
(βnew)-1 = (1 / N) ( ||t – Φm||2 + β-1 Σi γi )
PRML § 9.3 p. 30](https://image.slidesharecdn.com/bishopprml9-3wk77100408-1504-110612181620-phpapp02/85/Bishop-prml-9-3_wk77_100408-1504-30-320.jpg)







































![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)








