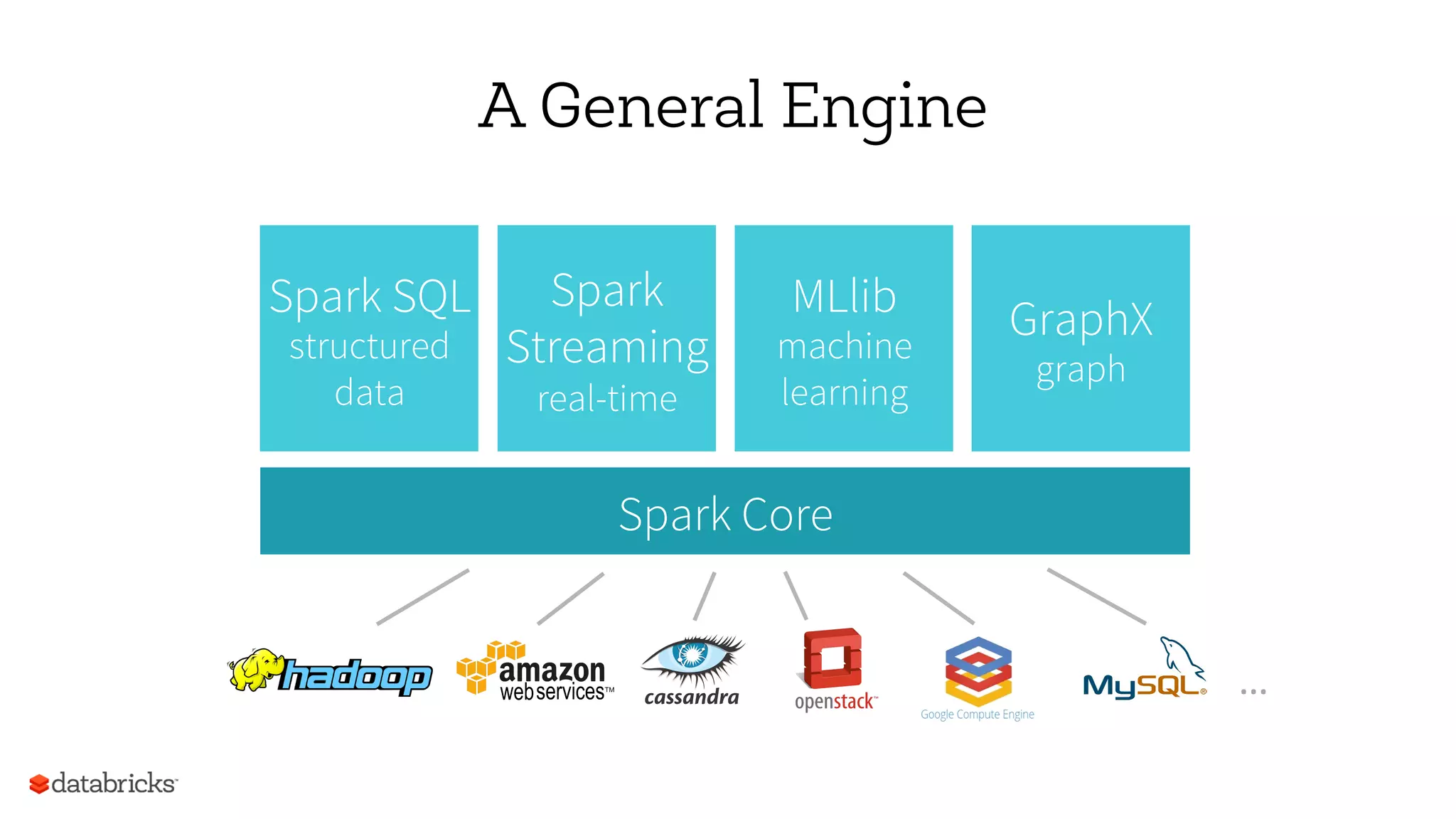
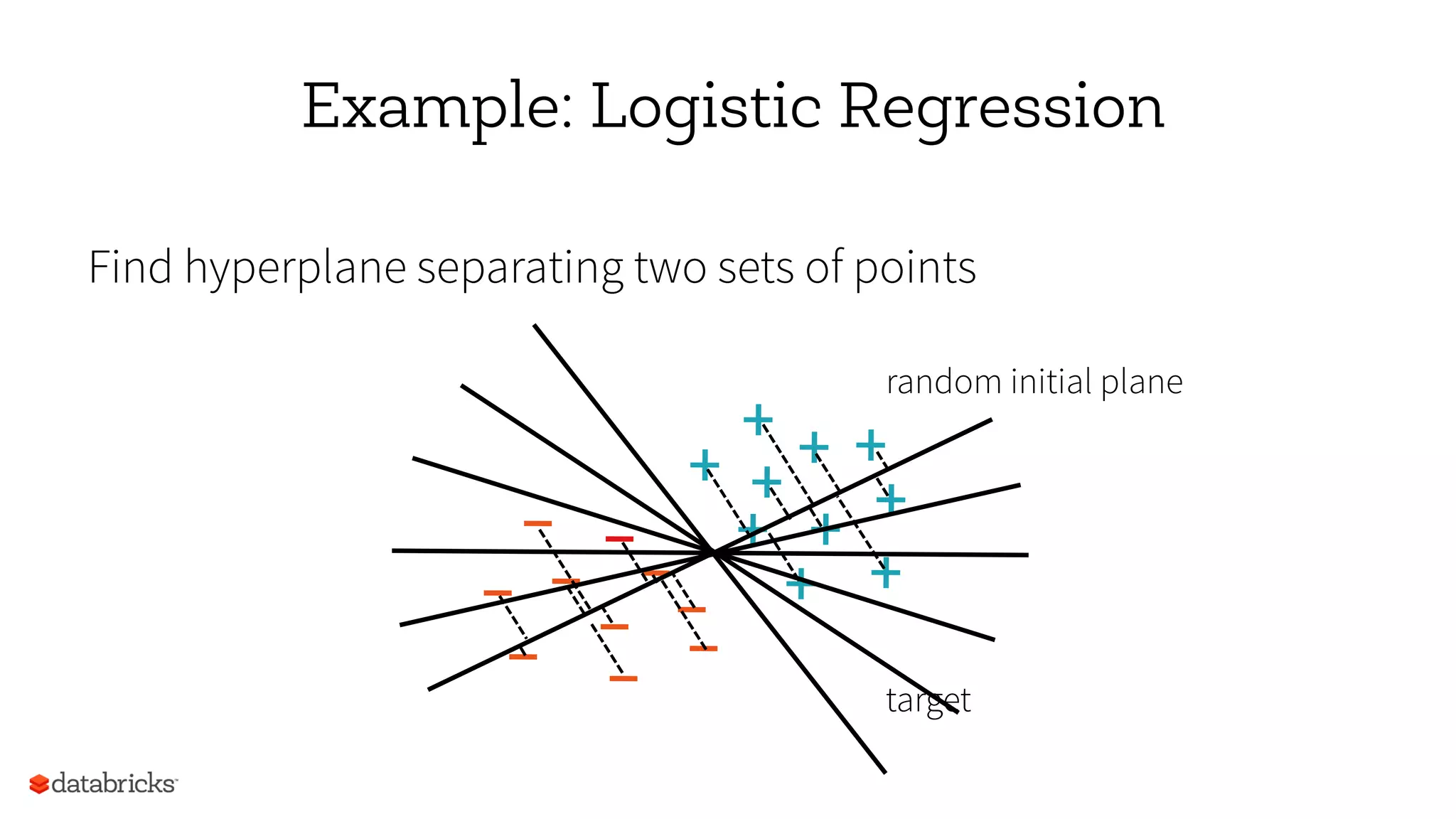
Download as PDF, PPTX





![Example: Log Mining
Load error messages from a log into memory, then interactively
search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(‘t’)[2])
messages.cache()
Block 1
Block 2
Block 3
Worker
Worker
Worker
Driver
messages.filter(lambda s: “foo” in s).count()
messages.filter(lambda s: “bar” in s).count()
. . .
tasks
results
Cache 1
Cache 2
Cache 3
Base RDDTransformed RDD
Action
Full-text search of Wikipedia in <1 sec
(vs 20 sec for on-disk data)](https://image.slidesharecdn.com/nextml-150428115554-conversion-gate01/75/End-to-end-Data-Pipeline-with-Apache-Spark-7-2048.jpg)

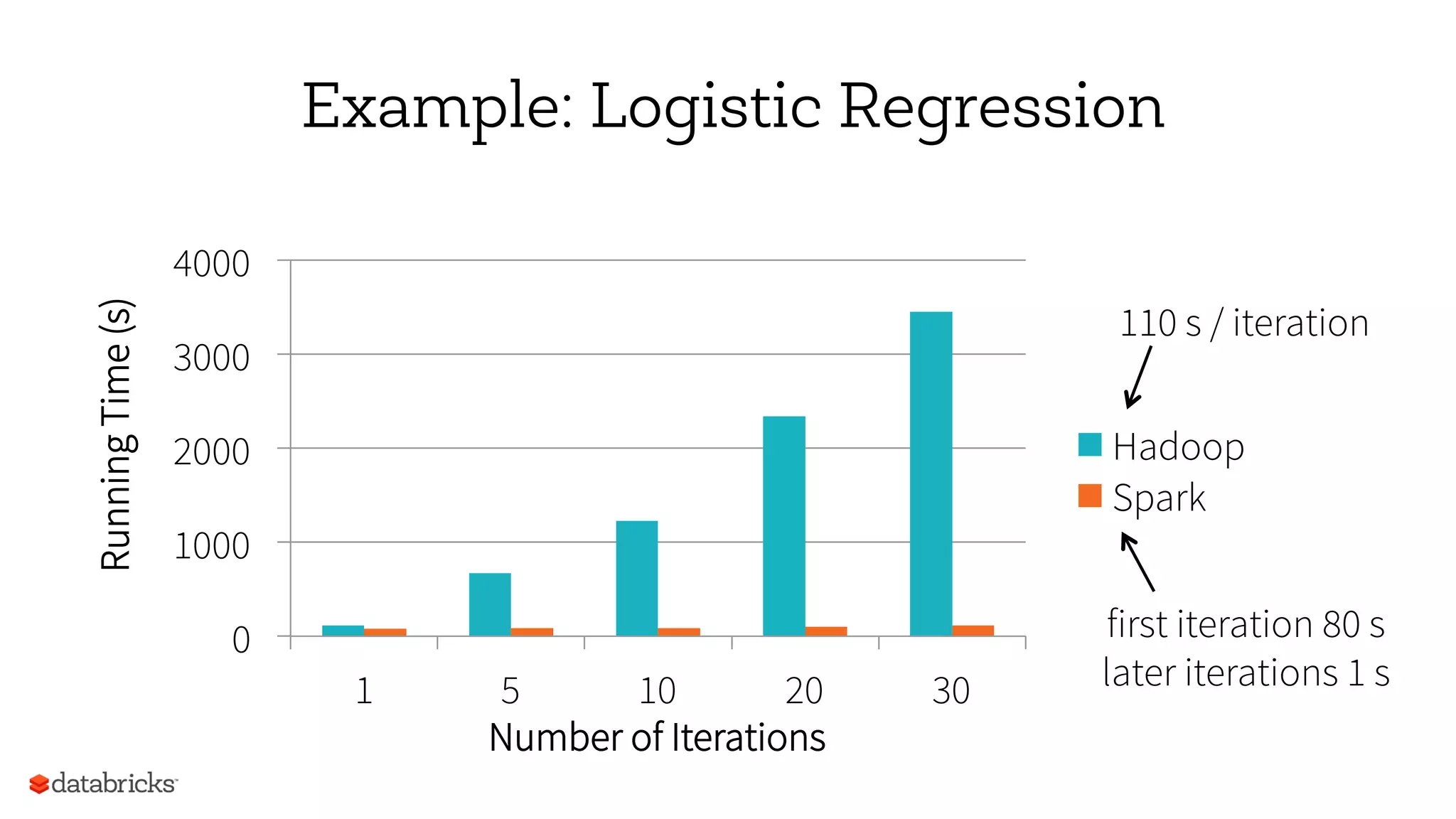







![22
DataFrames
Collections of structured
data similar to R, pandas
Automatically optimized
via Spark SQL
– Columnar storage
– Code-gen. execution
df = jsonFile(“tweets.json”)
df[df[“user”] == “matei”]
.groupBy(“date”)
.sum(“retweets”)
0
5
10
Python Scala DataFrame
RunningTime
Out now in Spark 1.3](https://image.slidesharecdn.com/nextml-150428115554-conversion-gate01/75/End-to-end-Data-Pipeline-with-Apache-Spark-22-2048.jpg)
![23
Machine Learning Pipelines
High-level API similar to
SciKit-Learn
Operates on DataFrames
Grid search and cross
validation to tune params
tokenizer = Tokenizer()
tf = HashingTF(numFeatures=1000)
lr = LogisticRegression()
pipe = Pipeline([tokenizer, tf, lr])
model = pipe.fit(df)
tokenizer TF LR
modelDataFrame
Out now in Spark 1.3](https://image.slidesharecdn.com/nextml-150428115554-conversion-gate01/75/End-to-end-Data-Pipeline-with-Apache-Spark-23-2048.jpg)
![24
Spark R Interface
Exposes DataFrames and
ML pipelines in R
Parallelize calls to R code
df = jsonFile(“tweets.json”)
summarize(
group_by(
df[df$user == “matei”,],
“date”),
sum(“retweets”))
Target: Spark 1.4 (June)](https://image.slidesharecdn.com/nextml-150428115554-conversion-gate01/75/End-to-end-Data-Pipeline-with-Apache-Spark-24-2048.jpg)


This document discusses Apache Spark, a fast and general cluster computing system. It summarizes Spark's capabilities for machine learning workflows, including feature preparation, model training, evaluation, and production use. It also outlines new high-level APIs for data science in Spark, including DataFrames, machine learning pipelines, and an R interface, with the goal of making Spark more similar to single-machine libraries like SciKit-Learn. These new APIs are designed to make Spark easier to use for machine learning and interactive data analysis.










































































































