Download as PDF, PPTX


























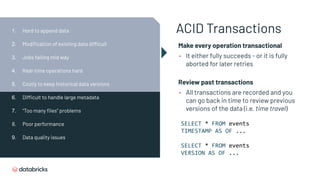








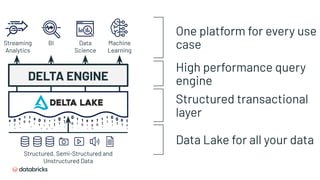

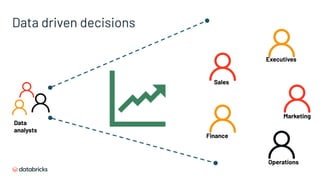








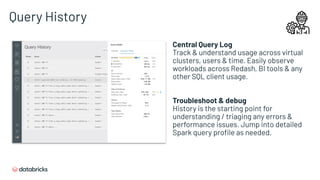
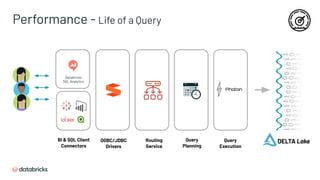
![SQL Endpoints
SQL Optimized Compute
SQL Endpoints give a quick way to setup
SQL / BI optimized compute. You pick a
tshirt size. Databricks will ensure
configuration that provides the highest
price/performance.
Concurrency Scaling Built-in
[Private Preview]
Virtual clusters can load balance queries
across multiple clusters behind the scenes,
providing unlimited concurrency.](https://image.slidesharecdn.com/lakehousewebinar-201214205320/85/Introduction-SQL-Analytics-on-Lakehouse-Architecture-47-320.jpg)



This document provides an introduction and overview of SQL Analytics on Lakehouse Architecture. It discusses the instructor Doug Bateman's background and experience. The course goals are outlined as describing key features of a data Lakehouse, explaining how Delta Lake enables a Lakehouse architecture, and defining features of the Databricks SQL Analytics user interface. The course agenda is then presented, covering topics on Lakehouse Architecture, Delta Lake, and a Databricks SQL Analytics demo. Background is also provided on Lakehouse architecture, how it combines the benefits of data warehouses and data lakes, and its key features.












![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)










































































