




























































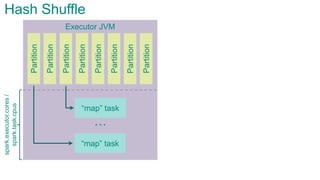

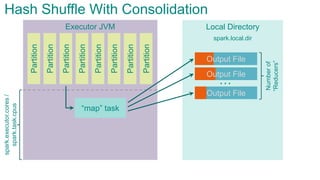

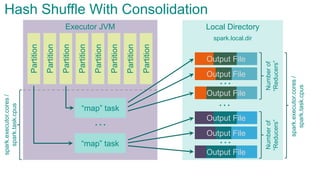

![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
Partition
Partition](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-90-320.jpg)
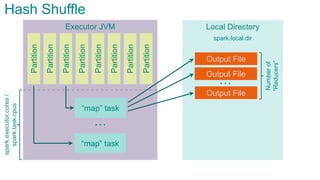
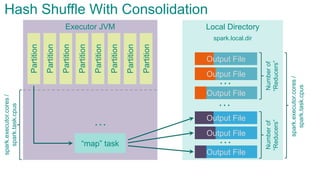
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
Partition
Partition
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-91-320.jpg)
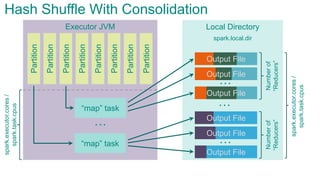
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
AppendOnlyMap
…
AppendOnlyMap
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-92-320.jpg)
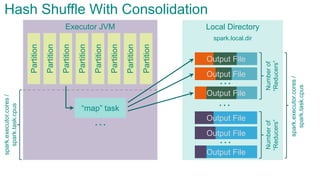
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
AppendOnlyMap
…
AppendOnlyMap
sort &
spill
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-93-320.jpg)
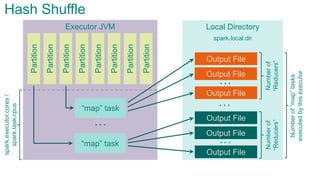
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
AppendOnlyMap
…
AppendOnlyMap
sort &
spill
Local
Directory
Output File
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-94-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
AppendOnlyMap
…
AppendOnlyMap
sort &
spill
sort &
spill
Local
Directory
Output File
index
Output File
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-95-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
AppendOnlyMap
…
AppendOnlyMap
sort &
spill
sort &
spill
sort &
spill
…
Local
Directory
…
Output File
index
Output File
index
Output File
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-96-320.jpg)
![MinHeap
Merge
MinHeap
Merge
Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
AppendOnlyMap
…
AppendOnlyMap
sort &
spill
sort &
spill
sort &
spill
…
Local
Directory
…
“reduce”task“reduce”task
…Output File
index
Output File
index
Output File
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-97-320.jpg)

![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
Partition
Partition](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-99-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
Partition
Partition
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-100-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
Serialized Data
LinkedList<MemoryBlock>
Array of data pointers and
Partition IDs, long[]
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-101-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
Serialized Data
LinkedList<MemoryBlock>
Array of data pointers and
Partition IDs, long[]
sort &
spill
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-102-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
Serialized Data
LinkedList<MemoryBlock>
Local Directory
Array of data pointers and
Partition IDs, long[]
sort &
spill
spark.local.dir
Output File
partition
partition
partition
partition
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-103-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
Serialized Data
LinkedList<MemoryBlock>
Local Directory
Array of data pointers and
Partition IDs, long[]
sort &
spill
sort &
spill
…
spark.local.dir
Output File
partition
partition
partition
partition
index
Output File
partition
partition
partition
partition
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-104-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
Serialized Data
LinkedList<MemoryBlock>
Local Directory
Array of data pointers and
Partition IDs, long[]
sort &
spill
sort &
spill
…
spark.local.dir
Output File
partition
partition
partition
partition
index
Output File
partition
partition
partition
partition
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-105-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
Serialized Data
LinkedList<MemoryBlock>
…
Local Directory
Array of data pointers and
Partition IDs, long[]
Serialized Data
LinkedList<MemoryBlock>
Array of data pointers and
Partition IDs, long[]
sort &
spill
sort &
spill
…
spark.local.dir
Output File
partition
partition
partition
partition
index
Output File
partition
partition
partition
partition
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-106-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
Serialized Data
LinkedList<MemoryBlock>
…
Local Directory
…
Array of data pointers and
Partition IDs, long[]
Serialized Data
LinkedList<MemoryBlock>
Array of data pointers and
Partition IDs, long[]
sort &
spill
sort &
spill
…
sort &
spill
spark.local.dir
Output File
partition
partition
partition
partition
index
Output File
partition
partition
partition
partition
index
Output File
partition
partition
partition
partition
index
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-107-320.jpg)
![Executor JVMPartition
Partition
Partition
Partition
Partition
Partition
Partition
Partition
“map”
task
“map”
task
…
Tungsten Sort Shuffle
spark.storage.[safetyFraction * memoryFraction]
spark.shuffle.
[safetyFraction * memoryFraction]
Partition
Partition
Serialized Data
LinkedList<MemoryBlock>
…
Local Directory
…
Array of data pointers and
Partition IDs, long[]
Serialized Data
LinkedList<MemoryBlock>
Array of data pointers and
Partition IDs, long[]
sort &
spill
sort &
spill
…
sort &
spill
spark.local.dir
Output File
partition
partition
partition
partition
index
Output File
partition
partition
partition
partition
index
Output File
partition
partition
partition
partition
index
Output File
partition
partition
partition
partition
index
merge
spark.executor.cores/spark.task.cpus](https://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/85/Apache-Spark-Architecture-108-320.jpg)

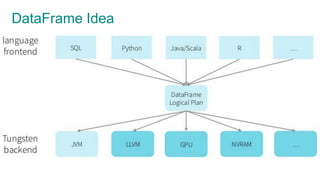





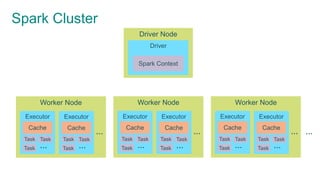
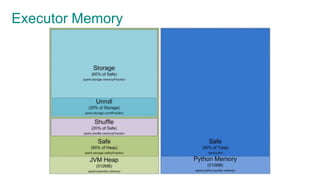
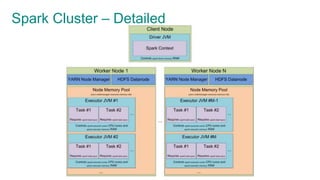
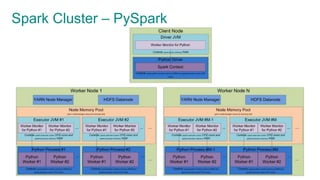
The document provides an overview of Apache Spark, focusing on its architectural features, motivations for use over Hadoop, and key concepts like Resilient Distributed Datasets (RDDs) and Directed Acyclic Graphs (DAGs). It emphasizes Spark's advantages, such as lazy computation, in-memory data caching, and efficient data processing metrics compared to traditional MapReduce. Additionally, the document discusses the structure of Spark clusters, drivers, executors, and applications, highlighting how these components work together to handle large-scale data operations.









































































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)

