Downloaded 19 times


![Our journey to Apache Spark
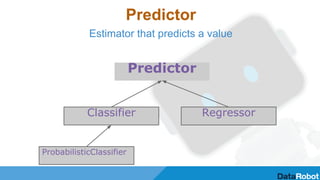
RDD vs DataFrame
RDD[Row[(Double, String, Vector)]]
Dataframe
(DoubleType,
nullable=true)
+ Attributes
(in spark-1.4)
Dataframe
(StringType,
nullable=true)
+ Attributes
(in spark-1.4)
Dataframe
(VectorType,
nullable=true)
+ Attributes
(in spark-1.4)
Attributes:
NumericAttribute
NominalAttribute (Ordinal)
BinaryAttribute](https://image.slidesharecdn.com/6-150528144859-lva1-app6891/85/AI-BigData-Lab-Automation-and-optimisation-of-machine-learning-pipelines-on-top-of-Apache-Spark-4-320.jpg)



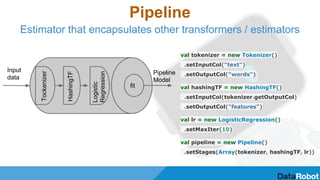
![Pipeline config
pipeline: {
"1": {
input: ["NUM"],
class: "org.apache.spark.ml.feature.MeanImputor"
},
"2": {
input: ["CAT"],
class: "org.apache.spark.ml.feature.OneHotEncoder"
},
"3":{
input: ["1", "2"],
class: "org.apache.spark.ml.feature.VectorAssembler"
},
"4": {
input: "3",
class : "org.apache.spark.ml.classification.LogisticRegression",
params: {
optimizer: “LBFGS”,
regParam: [0.5, 0.1, 0.01, 0.001]
}
}
}](https://image.slidesharecdn.com/6-150528144859-lva1-app6891/85/AI-BigData-Lab-Automation-and-optimisation-of-machine-learning-pipelines-on-top-of-Apache-Spark-9-320.jpg)

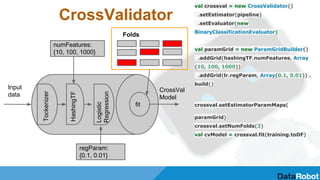
![Estimator
abstract class Estimator[M <: Model[M]] extends PipelineStage with Params {
/**
* Fits a single model to the input data with optional parameters.
*
* @param dataset input dataset
* @param paramPairs Optional list of param pairs.
* These values override any specified in this Estimator's
embedded ParamMap.
* @return fitted model
*/
@varargs
def fit(dataset: DataFrame, paramPairs: ParamPair[_]*): M = {
val map = ParamMap(paramPairs: _*)
fit(dataset, map)
}
}
Example:
val oneHotEncoderModel = (new OneHotEncoder).
setInputCol("vector_col").
fit(trainingData)
oneHotEncoderModel.transform(trainingData)
oneHotEncoderModel.transform(testData)
Estimator => Transformer](https://image.slidesharecdn.com/6-150528144859-lva1-app6891/85/AI-BigData-Lab-Automation-and-optimisation-of-machine-learning-pipelines-on-top-of-Apache-Spark-12-320.jpg)


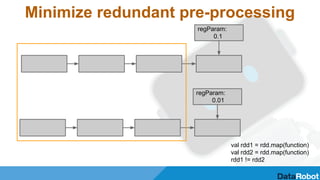



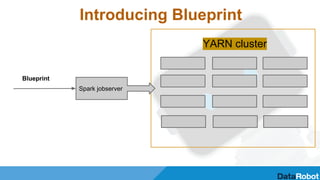
The document discusses optimizing machine learning pipelines in Apache Spark. It introduces Blueprint, which provides a configurable pipeline API to string together transformers, estimators, predictors, and evaluators. This allows reusable machine learning components to be assembled into complete pipelines. The document also discusses opportunities to optimize pipelines, such as minimizing redundant preprocessing, enabling parallel grid search, and using more efficient hyperparameter optimization techniques.























































































