Download as PDF, PPTX








![Datasets and DataFrames
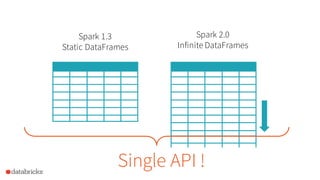
In 2015, we added DataFrames & Datasets as structured data APIs
• DataFrames are collections of rows with a schema
• Datasets add static types,e.g. Dataset[Person]
• Both run on Tungsten
Spark 2.0 will merge these APIs: DataFrame = Dataset[Row]](https://image.slidesharecdn.com/apache-spark-2-160519032118/85/Apache-Spark-2-0-Faster-Easier-and-Smarter-12-320.jpg)





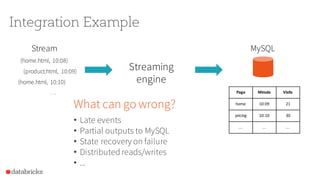




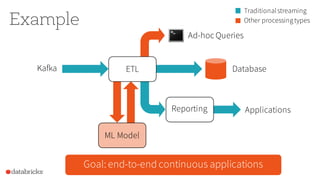



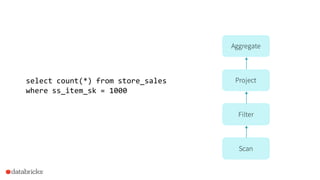



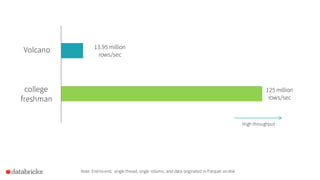


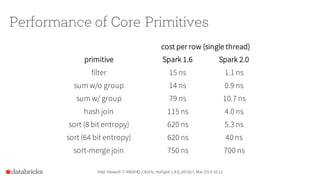
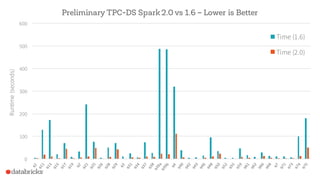






Apache Spark 2.0 enhances performance and usability with key features such as Project Tungsten for speed improvements of 5-20x, a unified API integrating datasets, dataframes, and SQL, and structured streaming for real-time analytics. The update focuses on maintaining backward compatibility while introducing richer semantics and optimizations. Users can explore Spark 2.0 through the Databricks Community Edition, with extensive improvements set to address around 2000 issues.






































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
