Downloaded 17 times









![SparkContext: entry to the world
● Can be used to create RDDs from many input sources
○ Native collections, local & remote FS
○ Any Hadoop Data Source
● Also create counters & accumulators
● Automatically created in the shells (called sc)
● Specify master & app name when creating
○ Master can be local[*], spark:// , yarn, etc.
○ app name should be human readable and make sense
● etc.
Petfu
l](https://image.slidesharecdn.com/gettingstartedwithapachesparkinpythononml-pyladiestoronto2016-160920200544/85/Getting-started-with-Apache-Spark-in-Python-PyLadies-Toronto-2016-11-320.jpg)












![Data prep / cleaning continued
# Combines a list of double input features into a vector
assembler = VectorAssembler(inputCols=["age", "education-num"],
outputCol="feautres")
# String indexer converts a set of strings into doubles
indexer =
StringIndexer(inputCol="category")
.setOutputCol("category-index")
# Can be used to combine pipeline components together
pipeline = Pipeline().setStages([assembler, indexer])
Huang
Yun
Chung](https://image.slidesharecdn.com/gettingstartedwithapachesparkinpythononml-pyladiestoronto2016-160920200544/85/Getting-started-with-Apache-Spark-in-Python-PyLadies-Toronto-2016-30-320.jpg)

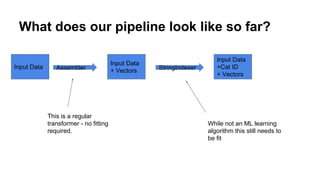
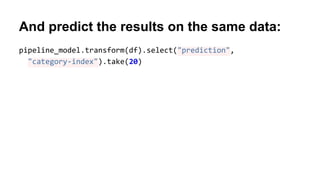
![Let's train a model on our prepared data:
# Specify model
dt = DecisionTreeClassifier(labelCol = "category-index",
featuresCol="features")
# Fit it
dt_model = dt.fit(prepared)
# Or as part of the pipeline
pipeline_and_model = Pipeline().setStages([assembler, indexer,
dt])
pipeline_model = pipeline_and_model.fit(df)](https://image.slidesharecdn.com/gettingstartedwithapachesparkinpythononml-pyladiestoronto2016-160920200544/85/Getting-started-with-Apache-Spark-in-Python-PyLadies-Toronto-2016-33-320.jpg)






This document is an introduction to Apache Spark with a focus on using PySpark for distributed computing, aimed at attendees of a 2016 PyLadies workshop. It covers the basics of Spark, including its architecture, RDDs, transformations, and actions, as well as performance considerations and how to use PySpark for machine learning tasks. It also shares resources, such as notebooks and references for further learning, alongside a promotional mention of an upcoming book on Spark performance.
















































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)

