









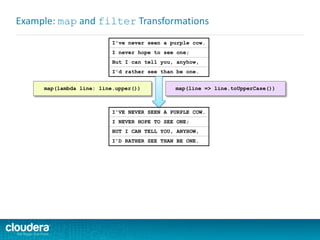
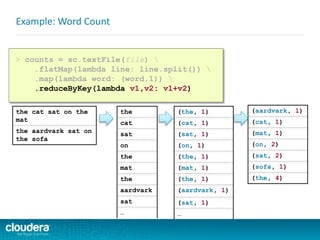
![Example of Required Scala Skill Level
Do you understand the following code? Could you write something
similar?
object Maps {
val colors = Map("red" -> 0xFF0000,
"turquoise" -> 0x00FFFF,
"black" -> 0x000000,
"orange" -> 0xFF8040,
"brown" -> 0x804000)
def main(args: Array[String]) {
for (name <- args) println(
colors.get(name) match {
case Some(code) =>
name + " has code: " + code
case None =>
"Unknown color: " + name
}
)
}
}](https://image.slidesharecdn.com/sparkdevwebinarslidesfinal-140723160210-phpapp02/85/Introduction-to-Apache-Spark-Developer-Training-10-320.jpg)
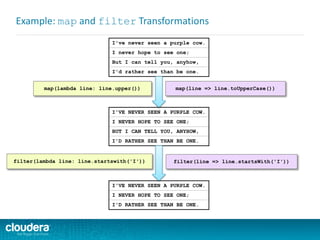
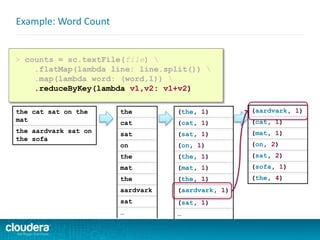
![Example of Required Python Skill Level
Do you understand the following code? Could you write something
similar?
import sys
def parsePurchases(s):
return s.split(',')
if __name__ == "__main__":
if len(sys.argv) < 2:
print "Usage: SumPrices <products>"
exit(-1)
prices = {'apple': 0.40, 'banana': 0.50, 'orange': 0.10}
total = sum(prices[fruit]
for fruit in parsePurchases(sys.argv[1]))
print 'Total: $%.2f' % total](https://image.slidesharecdn.com/sparkdevwebinarslidesfinal-140723160210-phpapp02/85/Introduction-to-Apache-Spark-Developer-Training-11-320.jpg)
















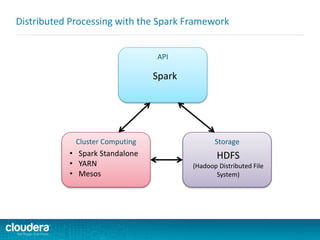






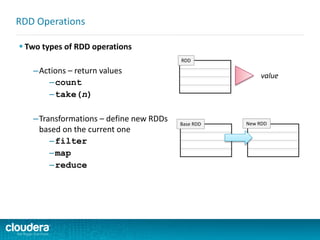










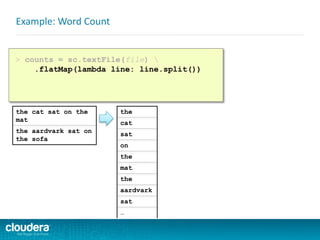
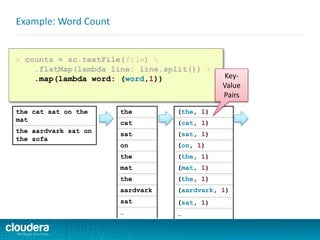
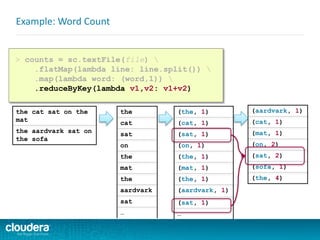



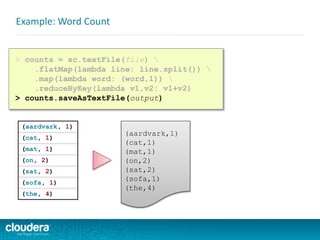

![ Spark takes the concepts of
MapReduce to the next level
–Higher level API = faster, easier
development
Spark v. Hadoop MapReduce
public class WordCount {
public static void main(String[] args) throws Exception {
Job job = new Job();
job.setJarByClass(WordCount.class);
job.setJobName("Word Count");
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(WordMapper.class);
job.setReducerClass(SumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
boolean success = job.waitForCompletion(true);
System.exit(success ? 0 : 1);
}
}
public class WordMapper extends Mapper<LongWritable, Text, Text,
IntWritable> {
public void map(LongWritable key, Text value,
Context context) throws IOException, InterruptedException {
String line = value.toString();
for (String word : line.split("W+")) {
if (word.length() > 0)
context.write(new Text(word), new IntWritable(1));
}
}
}
}
public class SumReducer extends Reducer<Text, IntWritable, Text,
IntWritable> {
public void reduce(Text key, Iterable<IntWritable>
values, Context context) throws IOException, InterruptedException {
int wordCount = 0;
for (IntWritable value : values) {
wordCount += value.get();
}
context.write(key, new IntWritable(wordCount));
}
}
> counts = sc.textFile(file)
.flatMap(lambda line: line.split())
.map(lambda word: (word,1))
.reduceByKey(lambda v1,v2: v1+v2)
> counts.saveAsTextFile(output)](https://image.slidesharecdn.com/sparkdevwebinarslidesfinal-140723160210-phpapp02/85/Introduction-to-Apache-Spark-Developer-Training-64-320.jpg)





The document outlines a training program for developers focused on Apache Spark, covering its components, APIs, and distributed data processing concepts. No prior knowledge of Spark, Hadoop, or distributed programming is needed, but basic Linux familiarity and intermediate programming skills in Scala or Python are required. The course includes practical applications and culminates in certified training to equip participants with the necessary skills for big data analysis.























































































