Download as PDF, PPTX



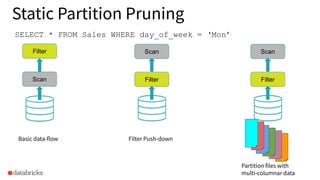
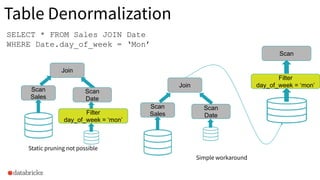
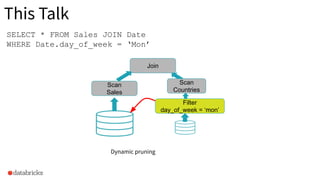
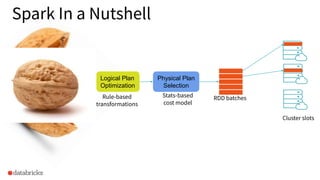


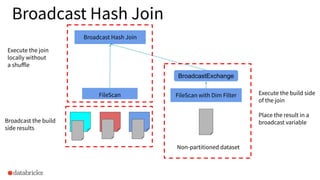
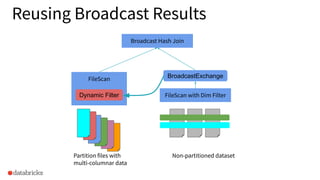

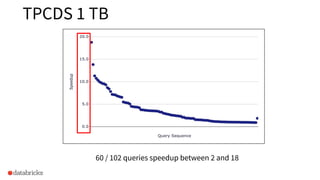
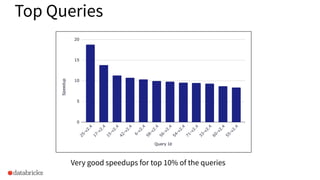
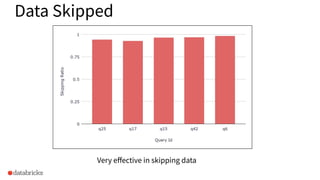
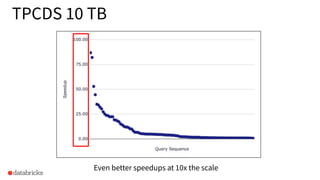
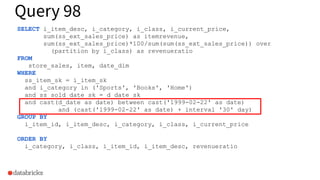
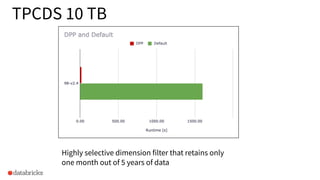



The document discusses the implementation of dynamic partition pruning in Apache Spark to enhance the performance of SQL analytics workloads. It outlines the benefits of this approach, leading to significant speedups in query execution, particularly with TPC-DS benchmarks like query 98. The innovation allows Spark to efficiently handle star-schema queries, reducing the need for complex ETL processes with denormalized tables.























































































