Download as PDF, PPTX





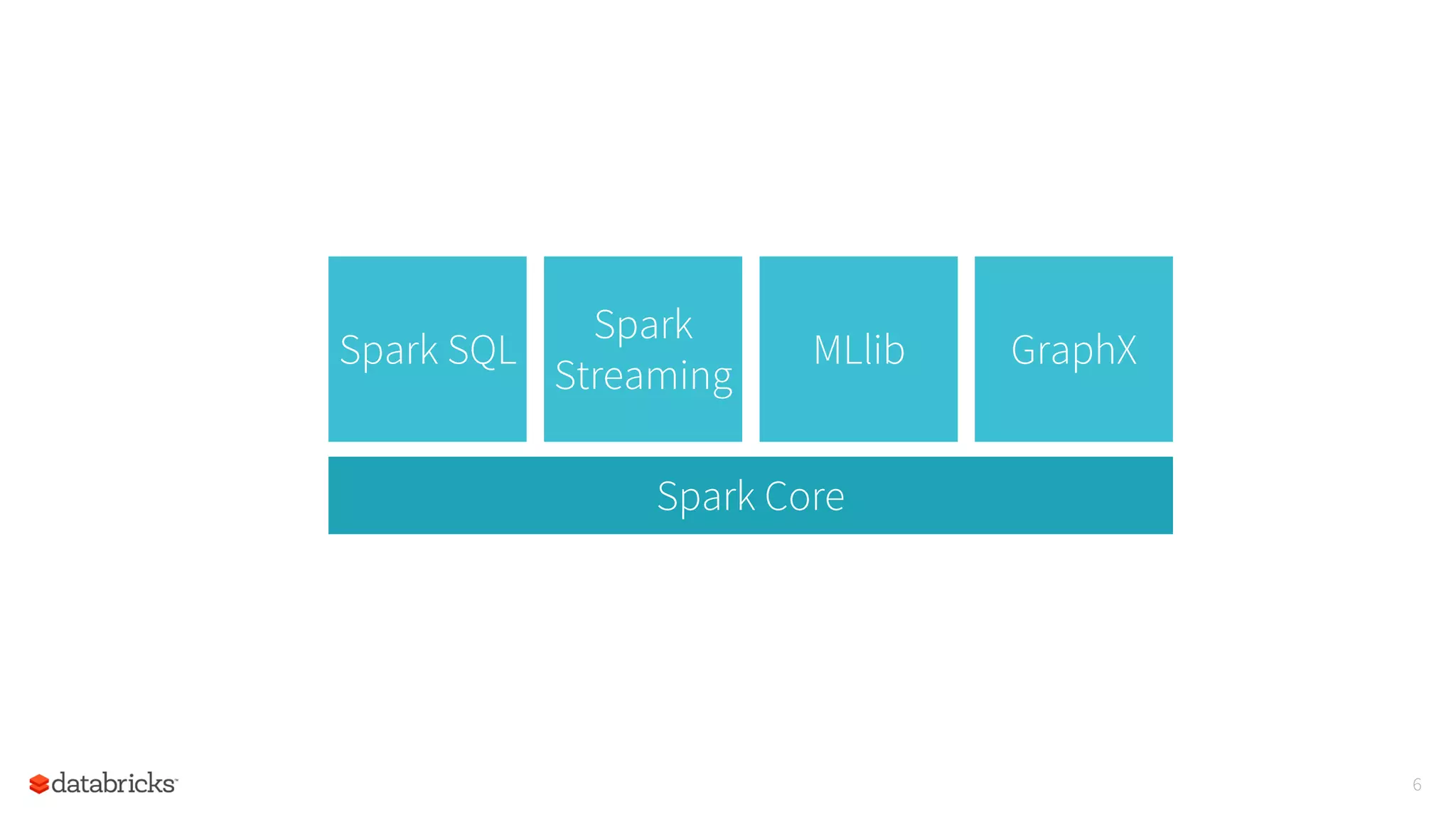
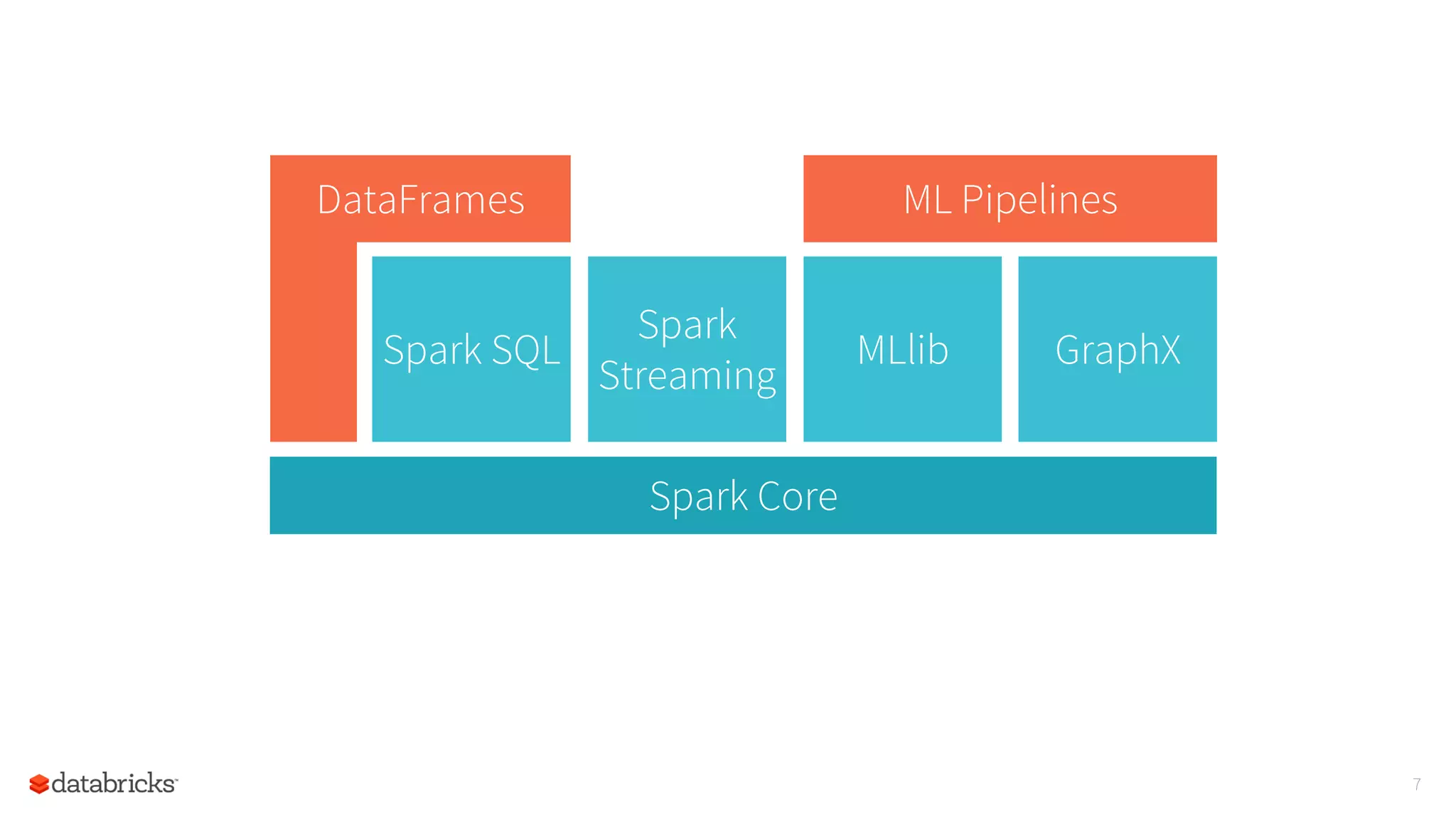
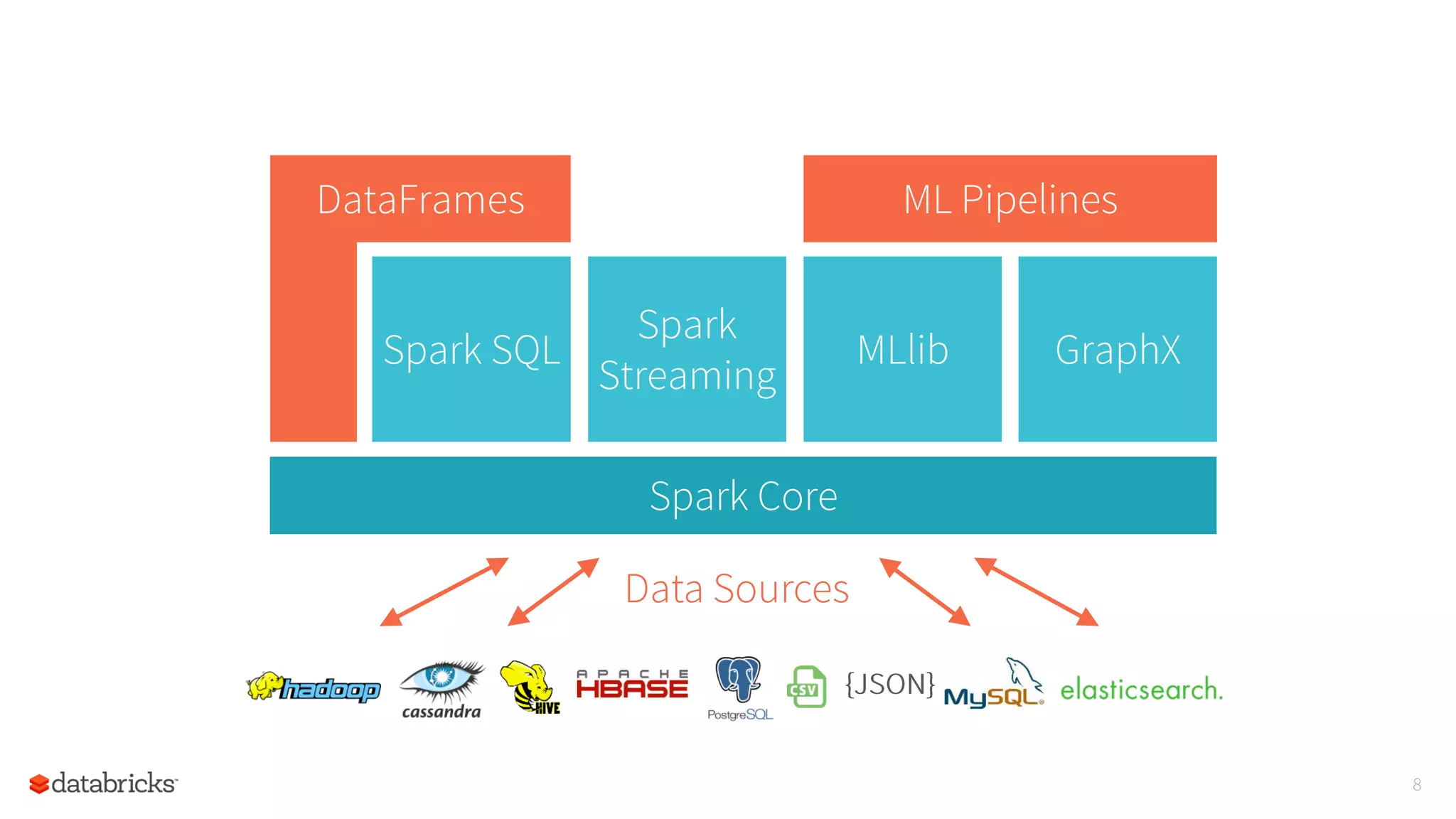
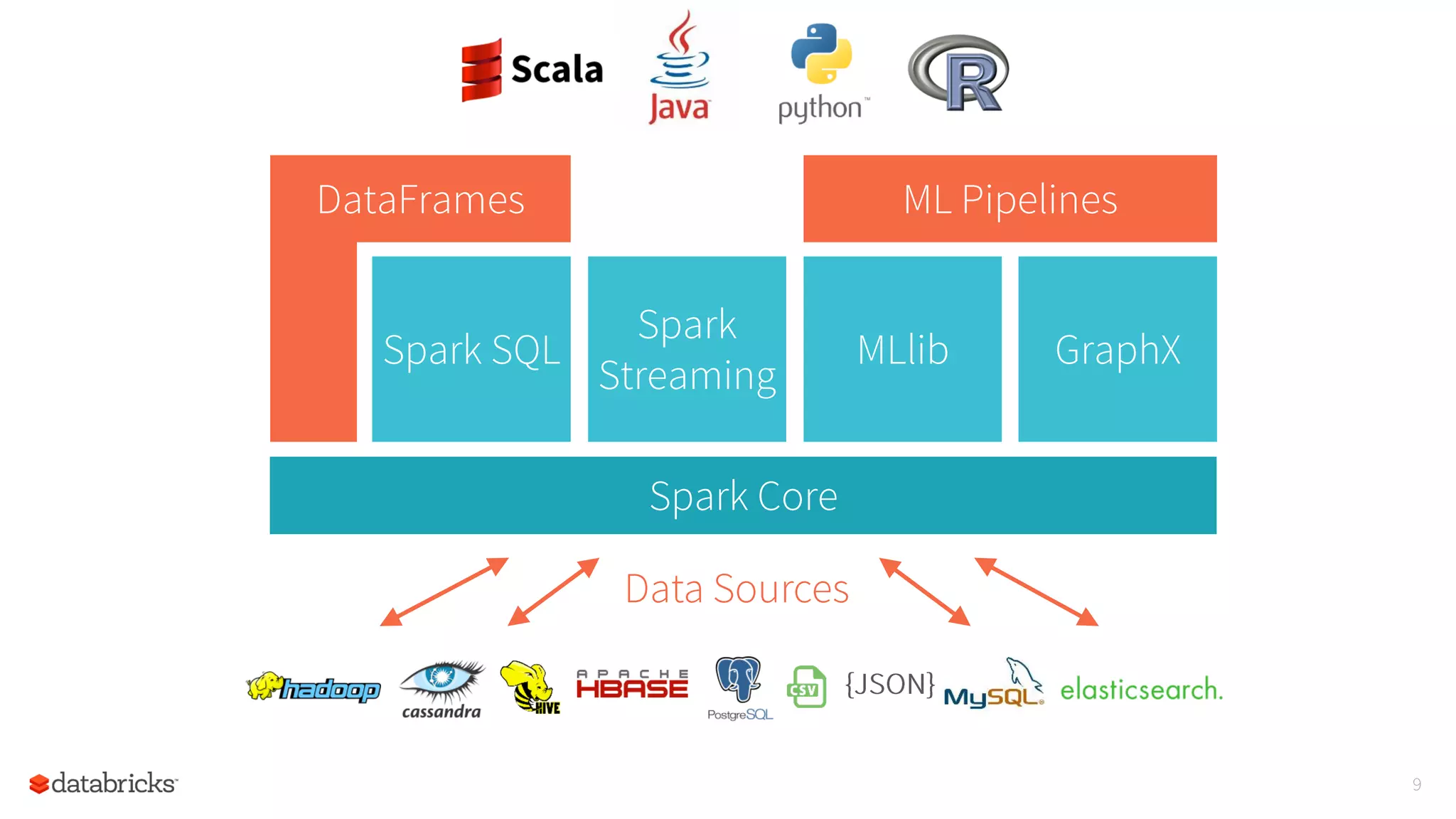


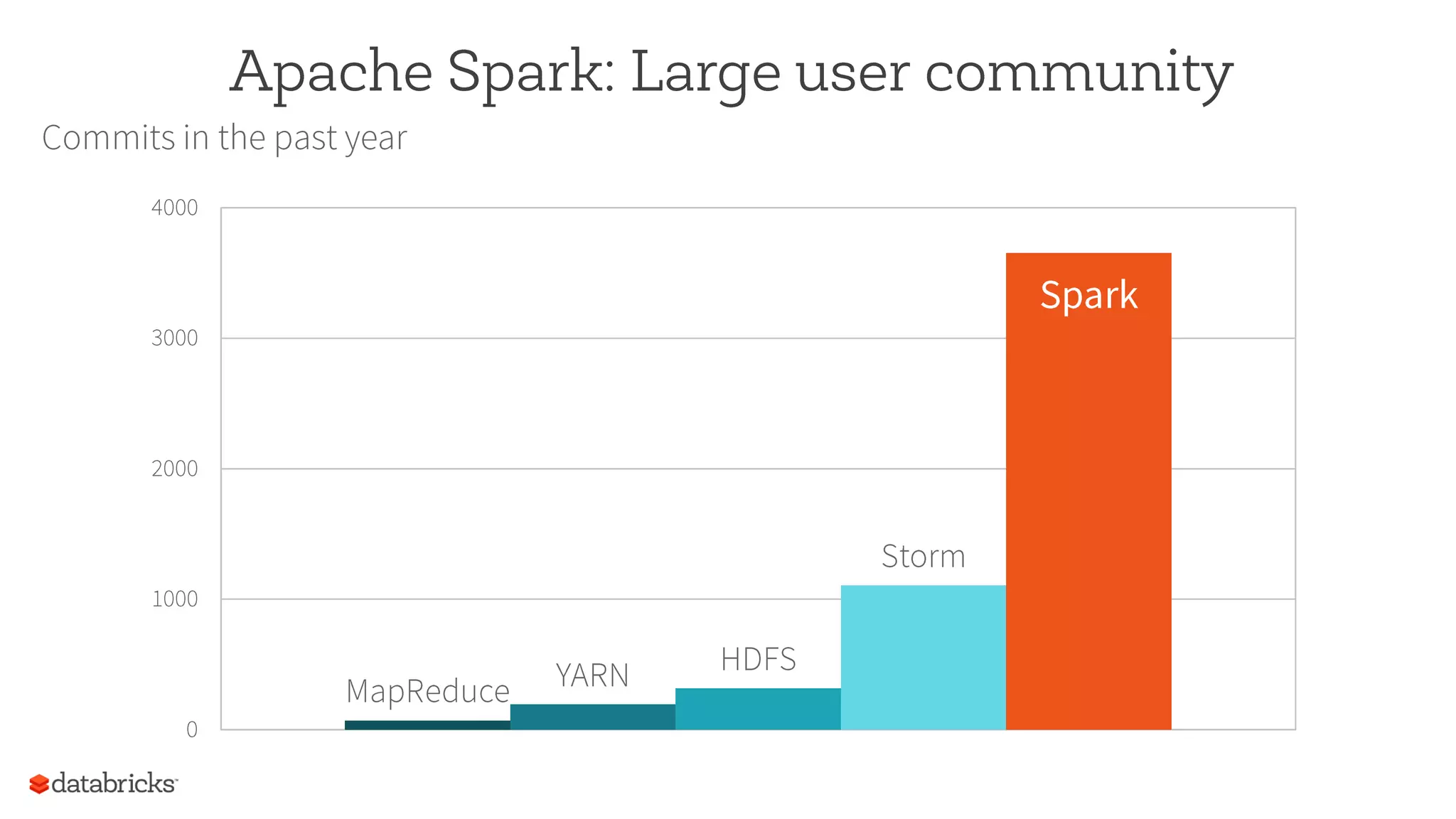
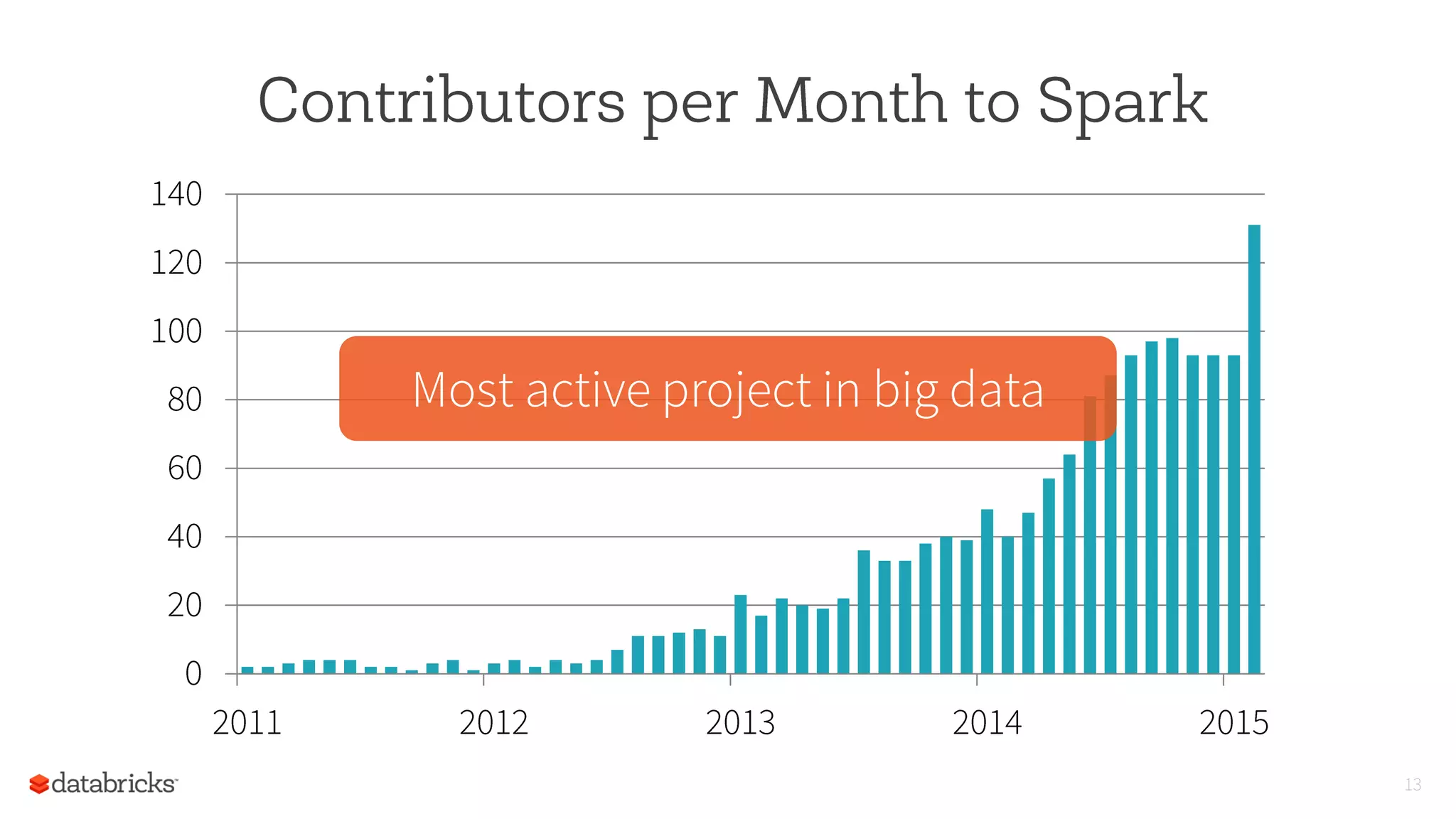






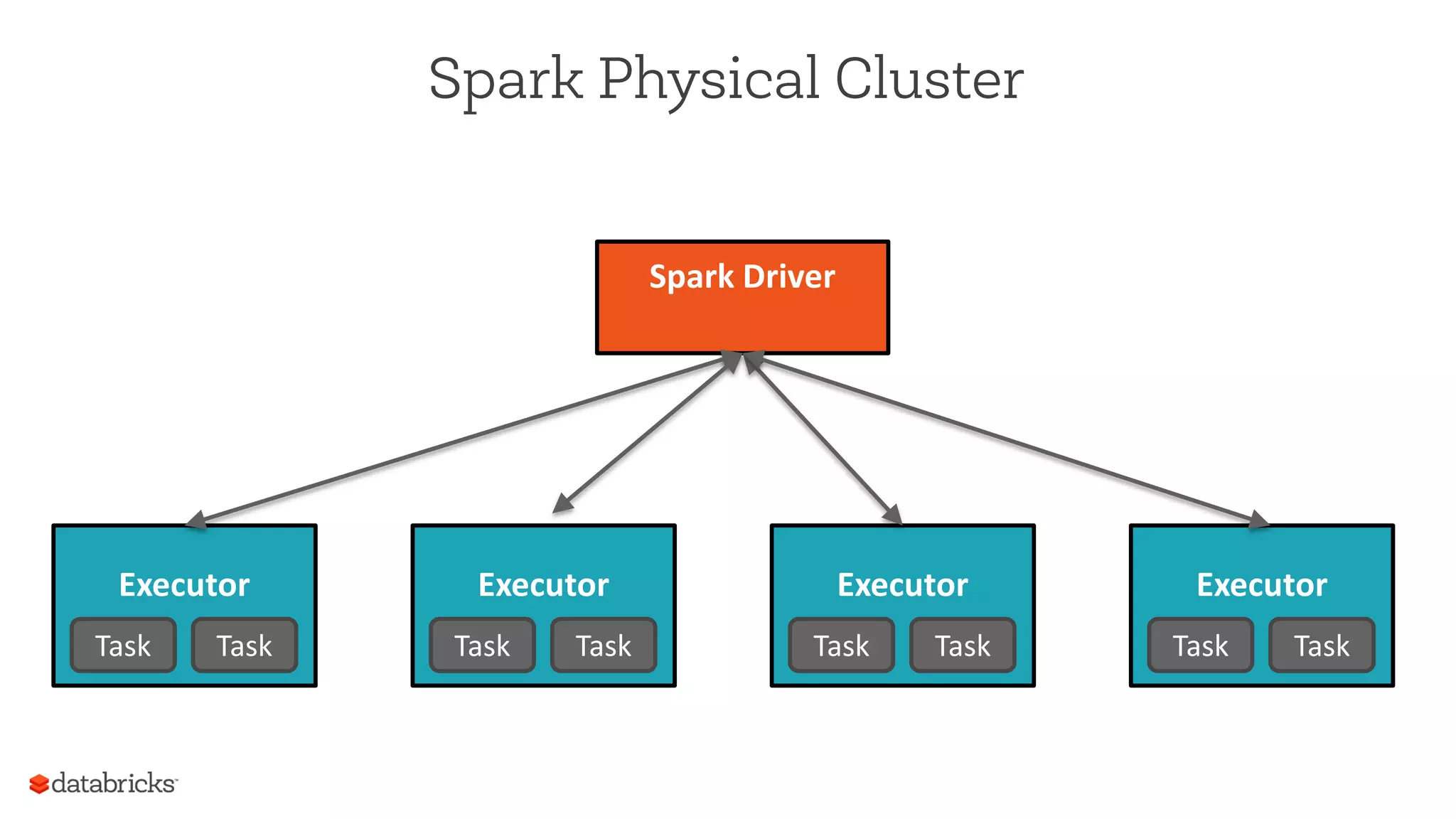
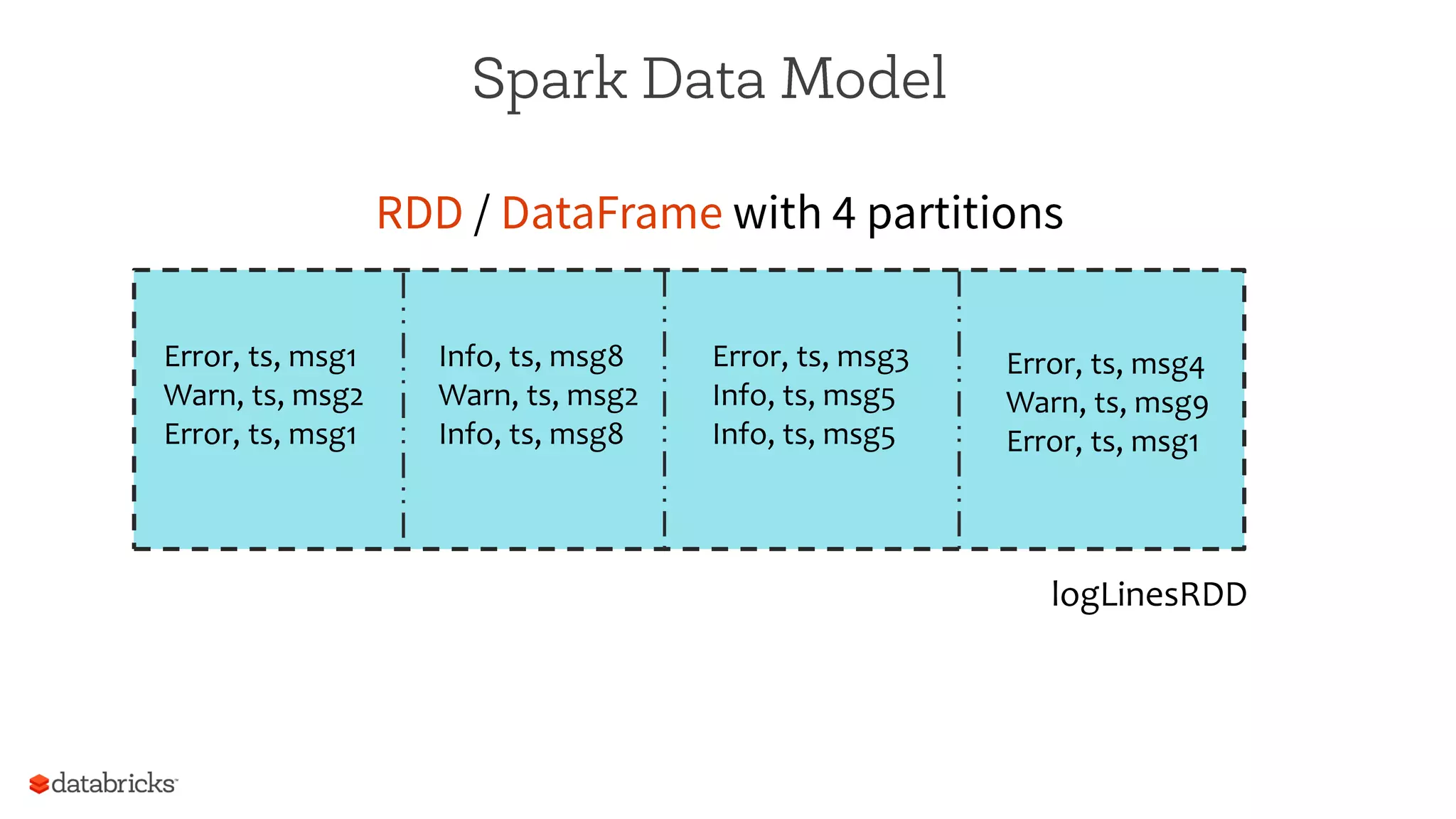
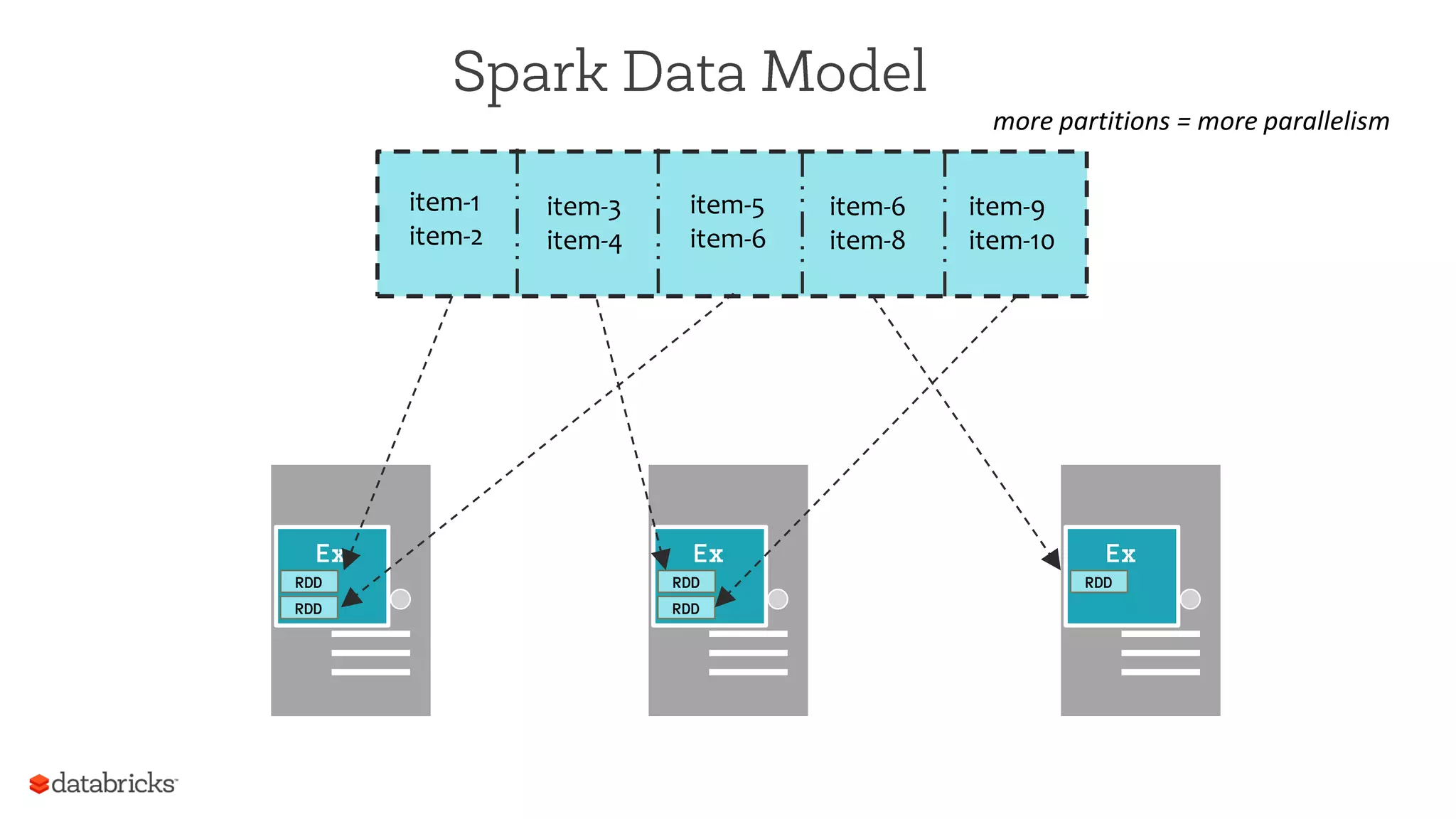









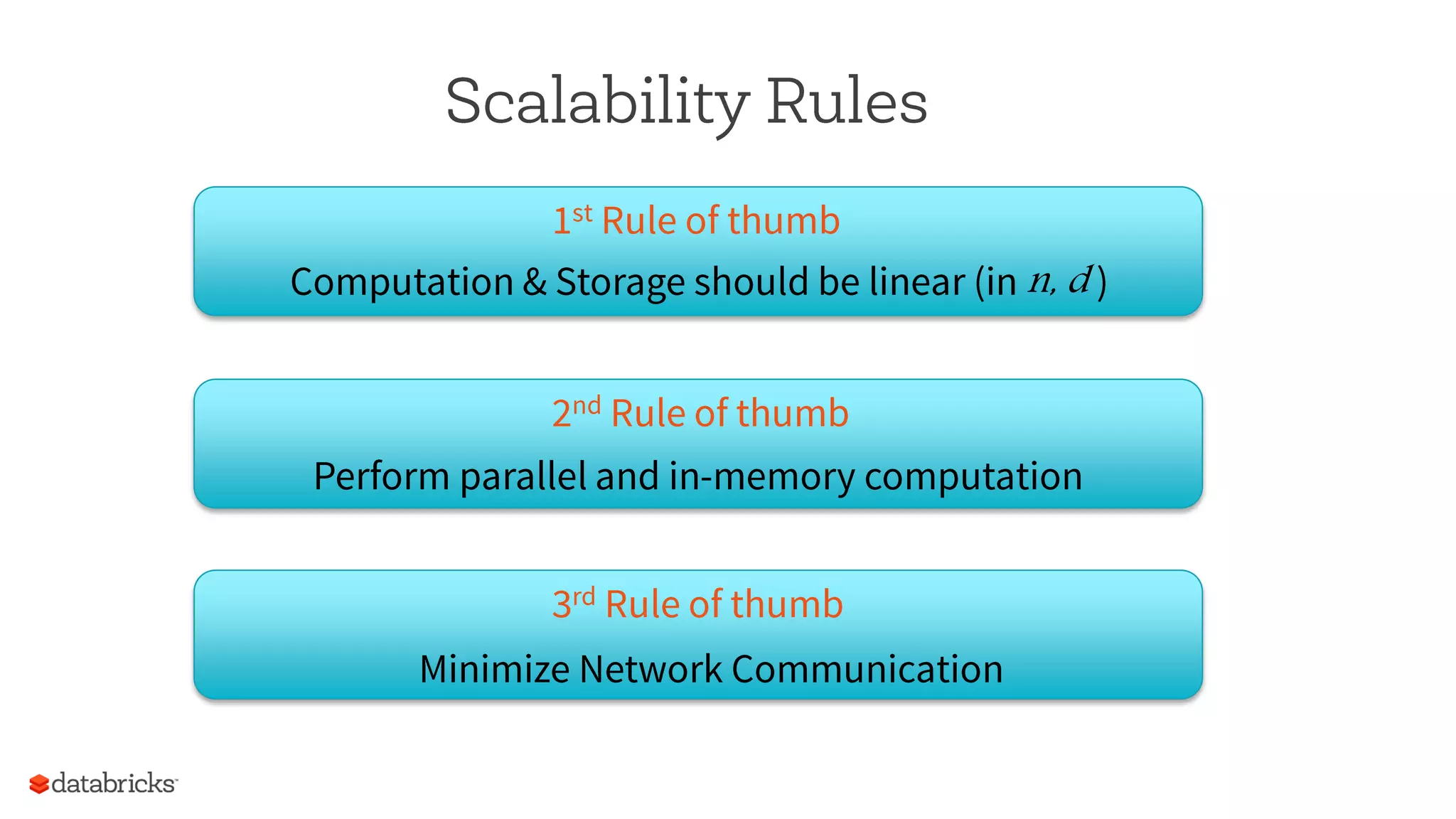


The document summarizes a meetup on Apache Spark hosted by Data Science London. It introduces the speakers - Sameer Farooqui, Doug Bateman, and Jon Bates - and their backgrounds in data science and Spark training. The agenda includes talks on a power plant predictive modeling demo using Spark and different approaches to parallelizing machine learning algorithms in Spark like model, divide and conquer, and data parallelism. It also provides overviews of Spark's machine learning library MLlib and common algorithms. The goal is for attendees to learn about Spark's unified engine and how to apply different machine learning techniques at scale.










































































































