Download as PDF, PPTX














![2. Prepare Dataset
1. From Parallelized Collections
2. From External DataSets
3. Passing Functions to Spark
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
JavaRDD<String> distFile = sc.textFile("data.txt"); OR
JavaRDD<String> distFile = sc.textFile("hdfs://data.txt");
class ParseLabeledPoint implements Function<String, LabeledPoint> {
public LabeledPoint call(String s) {...
for (int i = 0; i < len; i++) {
x[i] = Double.parseDouble(tokens[i]);
}
return new LabeledPoint(y, Vectors.dense(x));
}}
---
JavaRDD<LabeledPoint> data = distData.map(new ParseLabeledPoint()) ;](https://image.slidesharecdn.com/sparkoverview-140729190732-phpapp01/85/Spark-overview-25-320.jpg)



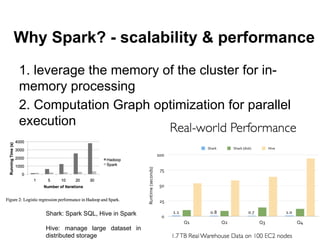












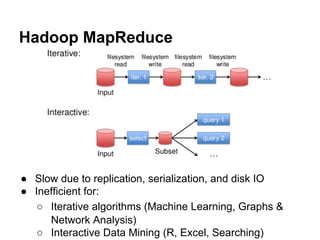
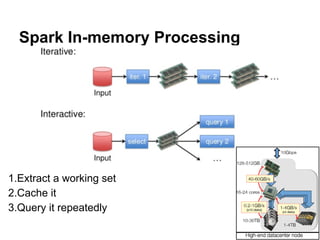
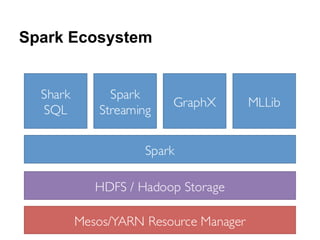
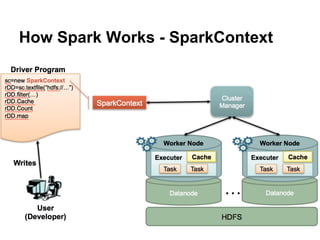
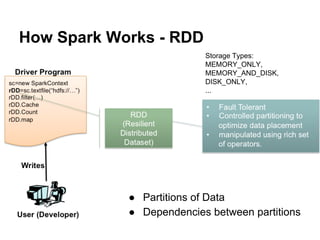
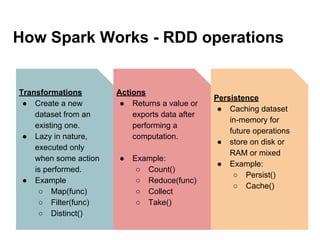
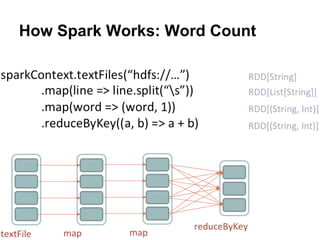
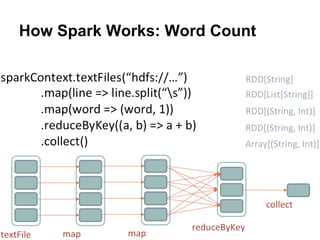
The document provides an overview of Apache Spark, detailing its features such as in-memory processing, parallel execution, and support for complex data analysis tasks compared to Hadoop's MapReduce. It outlines the Spark ecosystem, including RDDs (Resilient Distributed Datasets), transformations, actions, and examples of implementing a logistic regression model. Furthermore, it emphasizes Spark's scalability, performance, compatibility with Hadoop storage systems, and its various high-level APIs.






































![[Spark meetup] Spark Streaming Overview](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmeetupstratiostreaming-150121022614-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










