Download as PDF, PPTX







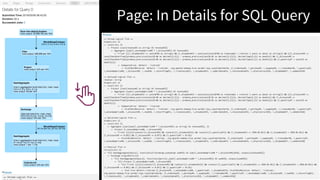
![Read Plans from
SQL Tab in either
Spark UI or Spark
History Server
11
Spark 3.0: Show the actual SQL statement? [SPARK-27045]](https://image.slidesharecdn.com/042006xiaoli-190510183745/85/Understanding-Query-Plans-and-Spark-UIs-11-320.jpg)


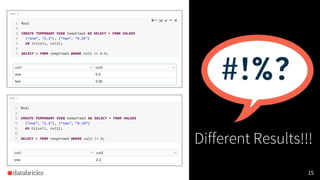

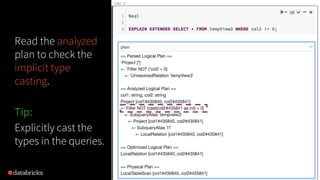

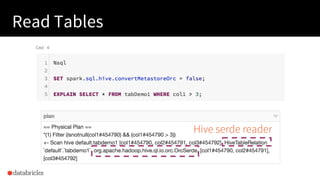
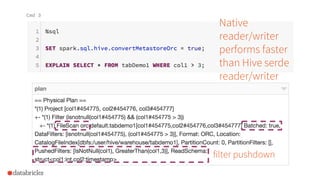
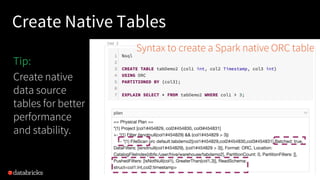
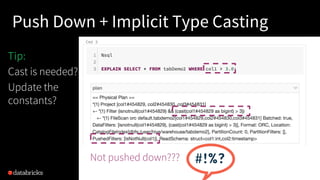
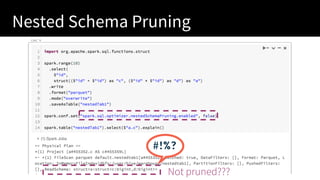




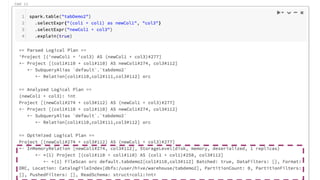


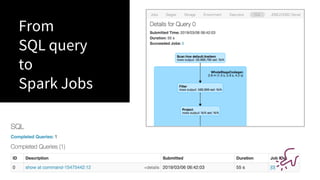

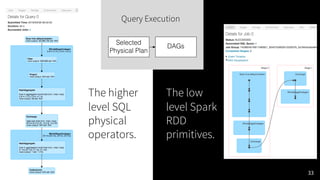
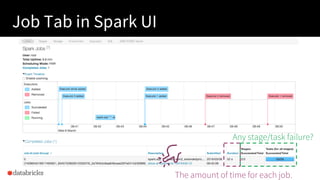
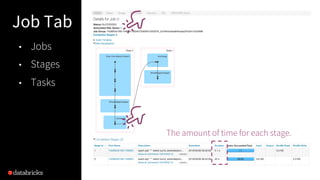
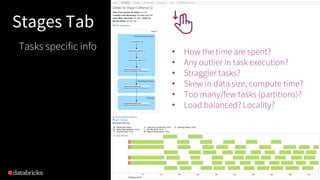
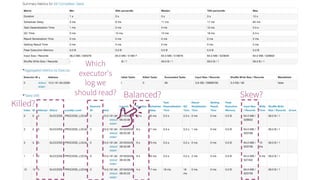
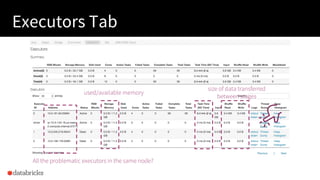
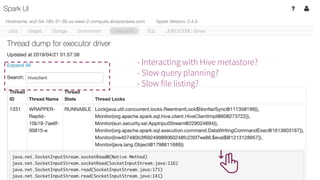


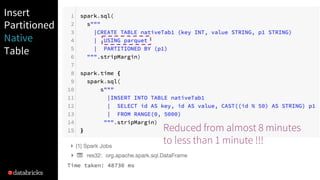
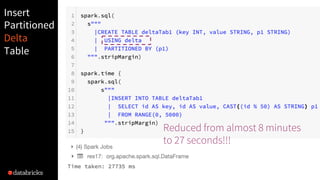








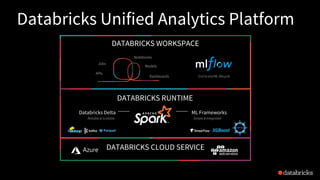
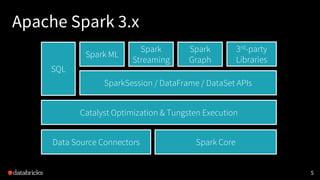
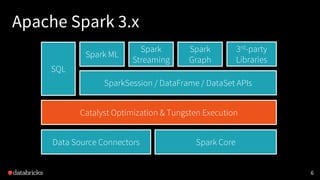
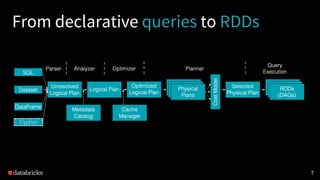
The document presented by Xiao Li at the Spark + AI Summit covers key aspects of understanding query plans and Spark UI, focusing on performance optimization and execution tracking. It discusses the differences between various query execution plans, tips for improving Spark queries, and the advantages of using Delta Lake with Apache Spark for better metadata handling and performance. The presentation concludes with resources for further learning and data on Delta Lake's processing statistics.























































































