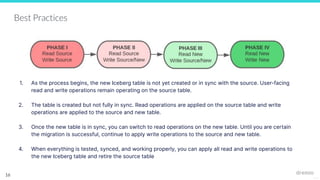
Download to read offline



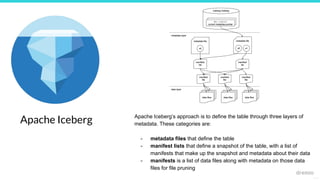
![25127
Metadata file - stores metadata about a
table at a certain point in time
{
"table-uuid" : "<uuid>",
"location" : "/path/to/table/dir",
"schema": {...},
"partition-spec": [ {<partition-details>}, ...],
"current-snapshot-id": <snapshot-id>,
"snapshots": [ {
"snapshot-id": <snapshot-id>
"manifest-list": "/path/to/manifest/list.avro"
}, ...],
...
}
Iceberg components: Metadata File
3
5
4
metadata layer
data layer](https://image.slidesharecdn.com/migratingtoapacheiceberg-221129193346-d99d7189/85/Data-Engineer-s-Lunch-83-Strategies-for-Migration-to-Apache-Iceberg-6-320.jpg)
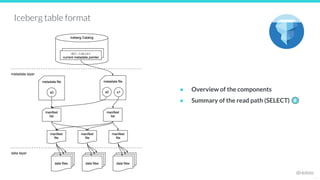
![25127
Iceberg components: Manifest List
Manifest list file - a list of manifest files
{
"manifest-path" : "/path/to/manifest/file.avro",
"added-snapshot-id": <snapshot-id>,
"partition-spec-id": <partition-spec-id>,
"partitions": [ {partition-info}, ...],
...
}
{
"manifest-path" : "/path/to/manifest/file2.avro",
"added-snapshot-id": <snapshot-id>,
"partition-spec-id": <partition-spec-id>,
"partitions": [ {partition-info}, ...],
...
}
6
metadata layer
data layer](https://image.slidesharecdn.com/migratingtoapacheiceberg-221129193346-d99d7189/85/Data-Engineer-s-Lunch-83-Strategies-for-Migration-to-Apache-Iceberg-7-320.jpg)
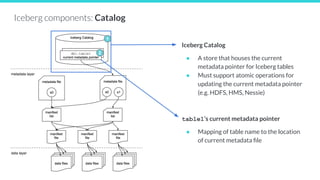
![25127
Manifest file - a list of data files, along with
details and stats about each data file
{
"data-file": {
"file-path": "/path/to/data/file.parquet",
"file-format": "PARQUET",
"partition":
{"<part-field>":{"<data-type>":<value>}},
"record-count": <num-records>,
"null-value-counts": [{
"column-index": "1", "value": 4
}, ...],
"lower-bounds": [{
"column-index": "1", "value": "aaa"
}, ...],
"upper-bounds": [{
"column-index": "1", "value": "eee"
}, ...],
}
...
}
{
...
}
Iceberg components: Manifest file
7
8
metadata layer
data layer](https://image.slidesharecdn.com/migratingtoapacheiceberg-221129193346-d99d7189/85/Data-Engineer-s-Lunch-83-Strategies-for-Migration-to-Apache-Iceberg-8-320.jpg)


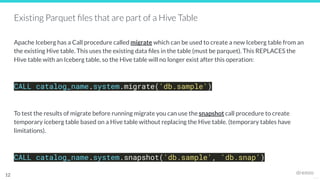
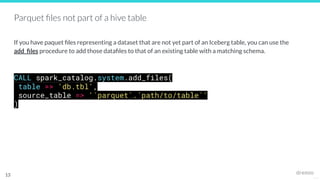
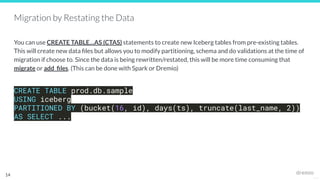
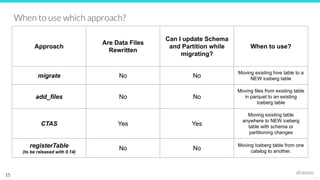


The document outlines the migration process to Apache Iceberg, detailing its table structure, metadata layers, and various migration procedures such as migrate, add_files, and create table as select (CTAS). It discusses the types of catalogs available for managing Iceberg tables, the use of existing Parquet files, and best practices for ensuring a successful migration. The document also highlights the differences between migration approaches and the associated capabilities, emphasizing the importance of maintaining data integrity throughout the process.





















































































