「全ての確率はコイン投げに通ず」 2015/12/5 Japan.R 発表資料 様々な確率分布をベルヌーイ分布(コイン投げ)との関係性で説明をしてみるというスライドです。 Pythonバージョンのコード: https://github.com/matsuken92/Qiita_Contents/blob/master/random_variables/random_variables.ipynb



















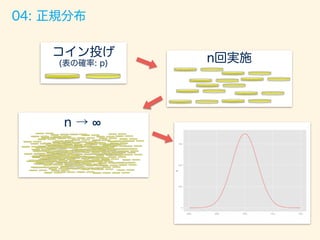
![02: 二項分布
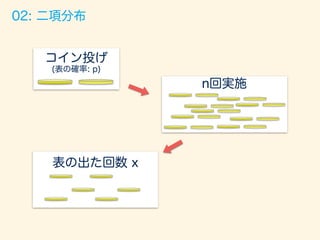
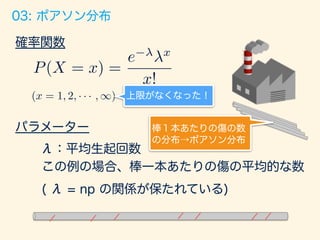
ベルヌーイ試行をn回実施し、何回成功したかの回数
を確率変数とした分布。
例:フリースロー 1セット30回実施。
1回あたりの成功率70%で計何回入ったか
確率関数
パラメーター
p:1 (表) が出る確率 [フリースローの成功確率]
P(X = x) = nCrpx
(1 p)n x
n:1セットあたりの回数
(x = 1, 2, · · · , n)](https://image.slidesharecdn.com/rev013-151205013701-lva1-app6892/85/Japan-R-24-320.jpg)






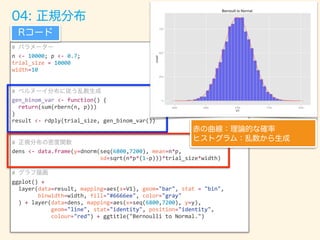






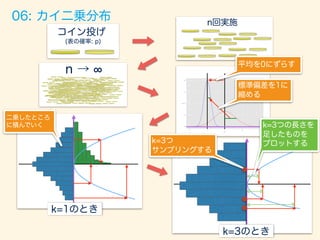


![05: カイ二乗分布
#
パラメーター
p
<-‐
0.7;
n
<-‐
1000;
trial_size
<-‐
100000;
width
<-‐
0.3;
df
<-‐
3
#
ベルヌーイ分布に従う乱数生成(3まわし)
gen_binom_var
<-‐
function()
{
return(sum(rbern(n,
p)))
}
gen_chisq_var
<-‐
function()
{
result
<-‐
rdply(trial_size,
gen_binom_var())
return(((result$V1
-‐
mean(result$V1))/sd(result$V1))**2)
}
#
自由度dfの分だけ生成する
result
<-‐
rlply(df,
gen_chisq_var(),.progress
=
"text")
res
<-‐
data.frame(x=result[[1]]
+
result[[2]]
+
result[[3]])
#
カイ二乗分布の密度関数(自由度=3)
xx
<-‐
seq(0,20,0.1)
dens
<-‐
data.frame(y=dchisq(x=xx,
df=df)*trial_size*width)
#
グラフ描画
ggplot()
+
layer(data=data,
mapping=aes(x=x),
geom="bar",
stat
=
"bin",
binwidth=width,
fill="#6666ee",
color="gray"
)
+
layer(data=dens,
mapping=aes(x=xx,
y=y),
geom="line",
stat="identity",
position="identity",
colour="blue"
)
+
ggtitle("Bernoulli
to
Chisquare")
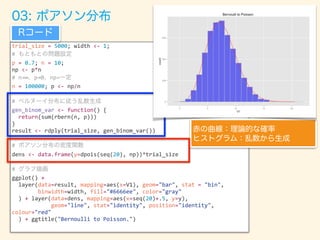
Rコード
赤の曲線:理論的な確率
ヒストグラム:乱数から生成](https://image.slidesharecdn.com/rev013-151205013701-lva1-app6892/85/Japan-R-48-320.jpg)


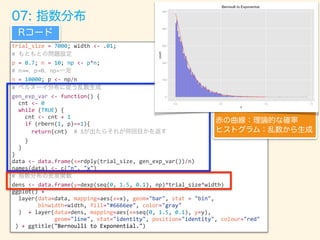



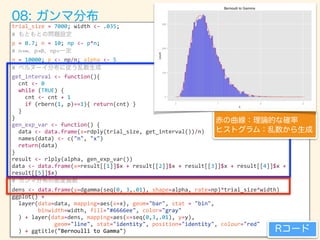

![trial_size
=
7000;
width
<-‐
.035;
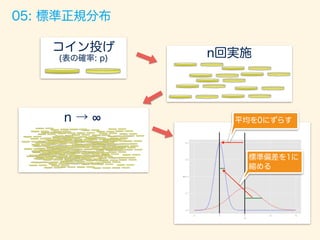
#
もともとの問題設定
p
=
0.7;
n
=
10;
np
<-‐
p*n;
#
n→∞、p→0、np=一定
n
=
10000;
p
<-‐
np/n;
alpha
<-‐
5
#
ベルヌーイ分布に従う乱数生成
get_interval
<-‐
function(){
cnt
<-‐
0
while
(TRUE)
{
cnt
<-‐
cnt
+
1
if
(rbern(1,
p)==1){
return(cnt)
}
}
}
gen_exp_var
<-‐
function()
{
data
<-‐
data.frame(x=rdply(trial_size,
get_interval())/n)
names(data)
<-‐
c("n",
"x")
return(data)
}
result
<-‐
rlply(alpha,
gen_exp_var())
data
<-‐
data.frame(x=result[[1]]$x
+
result[[2]]$x
+
result[[3]]$x
+
result[[4]]$x
+
result[[5]]$x)
#
ガンマ分布の密度関数
dens
<-‐
data.frame(y=dgamma(seq(0,
3,.01),
shape=alpha,
rate=np)*trial_size*width)
ggplot()
+
layer(data=data,
mapping=aes(x=x),
geom="bar",
stat
=
"bin",
binwidth=width,
fill="#6666ee",
color="gray"
)
+
layer(data=dens,
mapping=aes(x=seq(0,3,.01),
y=y),
geom="line",
stat="identity",
position="identity",
colour="red"
)
+
ggtitle("Bernoulli
to
Gamma") Rコード
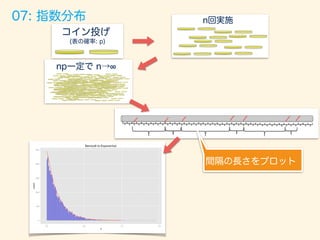
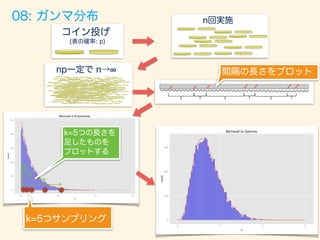
赤の曲線:理論的な確率
ヒストグラム:乱数から生成
08: ガンマ分布](https://image.slidesharecdn.com/rev013-151205013701-lva1-app6892/85/Japan-R-59-320.jpg)


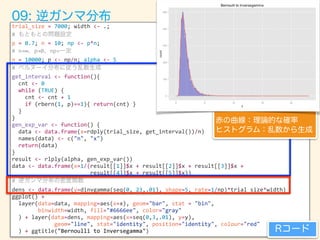

![trial_size
=
7000;
width
<-‐
.;
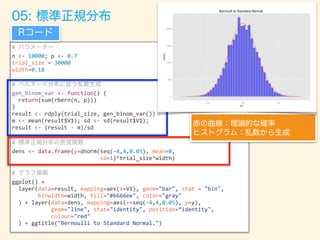
#
もともとの問題設定
p
=
0.7;
n
=
10;
np
<-‐
p*n;
#
n→∞、p→0、np=一定
n
=
10000;
p
<-‐
np/n;
alpha
<-‐
5
#
ベルヌーイ分布に従う乱数生成
get_interval
<-‐
function(){
cnt
<-‐
0
while
(TRUE)
{
cnt
<-‐
cnt
+
1
if
(rbern(1,
p)==1){
return(cnt)
}
}
}
gen_exp_var
<-‐
function()
{
data
<-‐
data.frame(x=rdply(trial_size,
get_interval())/n)
names(data)
<-‐
c("n",
"x")
return(data)
}
result
<-‐
rlply(alpha,
gen_exp_var())
data
<-‐
data.frame(x=1/(result[[1]]$x
+
result[[2]]$x
+
result[[3]]$x
+
result[[4]]$x
+
result[[5]]$x))
#
逆ガンマ分布の密度関数
dens
<-‐
data.frame(y=dinvgamma(seq(0,
23,.01),
shape=5,
rate=1/np)*trial_size*width)
ggplot()
+
layer(data=data,
mapping=aes(x=x),
geom="bar",
stat
=
"bin",
binwidth=width,
fill="#6666ee",
color="gray"
)
+
layer(data=dens,
mapping=aes(x=seq(0,3,.01),
y=y),
geom="line",
stat="identity",
position="identity",
colour="red"
)
+
ggtitle("Bernoulli
to
Inversegamma") Rコード
赤の曲線:理論的な確率
ヒストグラム:乱数から生成
09: 逆ガンマ分布](https://image.slidesharecdn.com/rev013-151205013701-lva1-app6892/85/Japan-R-64-320.jpg)

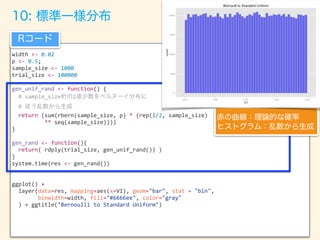




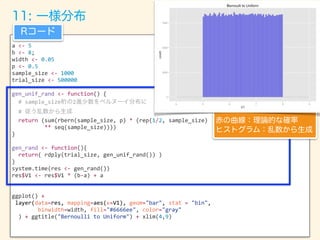





![width
<-‐
0.03;
p
<-‐
0.5
digits_length
<-‐
30;
set_size
<-‐
3
trial_size
<-‐
30000
gen_unif_rand
<-‐
function()
{
#
digits_length桁の2進少数をベルヌーイ分布
#
に従う乱数から生成
return
(sum(rbern(digits_length,
p)
*
(rep(1/2,
digits_length)
**
seq(digits_length))))
}
gen_rand
<-‐
function(){
return(
rdply(set_size,
gen_unif_rand())$V1
)
}
unif_dataset
<-‐
rlply(trial_size,
gen_rand,
.progress='text')
p
<-‐
ceiling(set_size
*
0.5);
q
<-‐
set_size
-‐
p
+
1
get_nth_data
<-‐
function(a){
return(a[order(a)][p])
}
disp_data
<-‐
data.frame(lapply(unif_dataset,
get_nth_data))
names(disp_data)
<-‐
seq(length(disp_data));
disp_data
<-‐
data.frame(t(disp_data))
names(disp_data)
<-‐
"V1"
x_range
<-‐
seq(0,
1,
0.001)
dens
<-‐
data.frame(y=dbeta(x_range,
p,
q)*trial_size*width)
ggplot()
+
layer(data=disp_data,
mapping=aes(x=V1),
geom="bar",
stat
=
"bin",
binwidth=width,
fill="#6666ee",
color="gray"
)
+
layer(data=dens,
mapping=aes(x=x_range,
y=y),
geom="line",
stat="identity",
position="identity",
colour="red"
)
+
ggtitle("Bernoulli
to
Beta")
Rコード
赤の曲線:理論的な確率
ヒストグラム:乱数から生成
12: ベータ分布](https://image.slidesharecdn.com/rev013-151205013701-lva1-app6892/85/Japan-R-79-320.jpg)









![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)






























