条件付き独立性
条件部の値を固定した時に独立である時、条件
付き独立であるという。
P( x, y| z
c1 )
P( x, y | z
P( x | z
c2 )
P ( x, y | z
P( x, y | z )
c1 ) P( y | z
P( x | z
c1 )
c2 ) P( y | z
..........
....
ck )
P( x | z
c2 )
ck ) P ( y | z
ck )
P( x | z ) P( y | z )
21
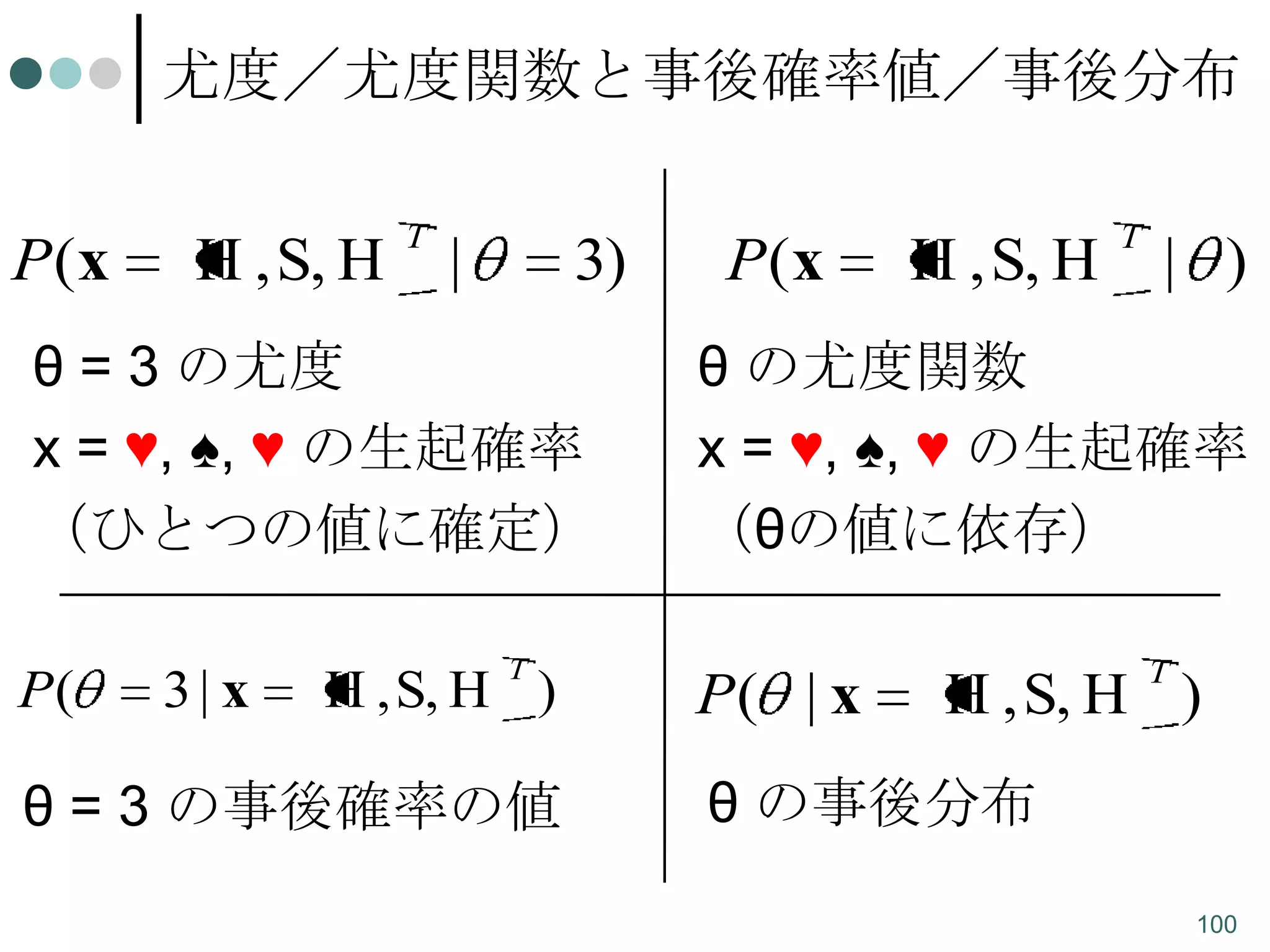
尤度/尤度関数と事後確率値/事後分布
P(x
H , S,H
T
|
3)
θ = 3 の尤度
x = ♥, ♠, ♥ の生起確率
(ひとつの値に確定)
P(
3| x
T
H , S, H )
θ = 3 の事後確率の値
P(x
H , S, H
T
| )
θ の尤度関数
x = ♥, ♠, ♥ の生起確率
(θの値に依存)
P( | x
T
H , S, H )
θ の事後分布
100


































































































![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)













