Downloaded 457 times






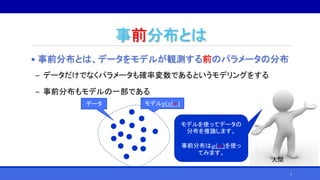











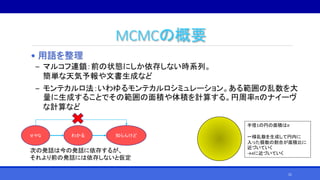
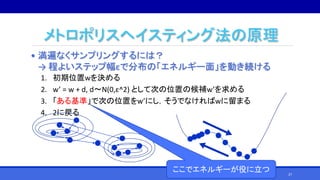
![MCMCの概要
• マルコフ連鎖モンテカルロ法(Markov Chain Monte-Carlo method,
MCMC)とは?
• 求める確率分布を均衡分布として持つマルコフ連鎖を作成することをも
とに、確率分布のサンプリングを行うアルゴリズムの総称[Wikipedia,
2018/2/6閲覧]
????
20](https://image.slidesharecdn.com/mcstutorial1st-releasever-190806052151/85/slide-20-320.jpg)








































![経験損失と汎化損失
• 経験損失と汎化損失は異なり,経験損失に注目すると過学習する
• 汎化損失はどのような振る舞いをするのだろうか?
• 経験損失と汎化損失はどの程度異なるのだろうか?
次の数理科学の問題に帰着例(漸近論):
1. 𝑛 → ∞のとき確率変数𝐺 𝑛の漸近挙動を求めよ.
2.確率変数𝐺 𝑛と𝑇𝑛の差𝑉𝑛′もまた確率変数である.
𝑉𝑛′の漸近挙動を求めよ.
主要な参考文献:[Watanabe, 2009]
65](https://image.slidesharecdn.com/mcstutorial1st-releasever-190806052151/85/slide-64-320.jpg)

![ベイズ統計理論
• 一般の自由エネルギーの漸近挙動
𝐹𝑛 = 𝑛𝑆 𝑛 + 𝜆 log 𝑛 − 𝑚 − 1 log log 𝑛 + 𝑜 𝑝 log log 𝑛
• 係数𝜆や𝑚とは何か?
• 事後分布が正規分布で近似可能なとき(正則モデル):
𝜆 =
𝑑
2
, 𝑚 = 1; 𝑑: パラメータ次元
‒ この結果は古くから知られていた→ベイズ情報量規準BIC[Schwarz, 1978]
• 近似不可能な場合を含む一般の場合はλは実対数閾値、mは多重度である。
67](https://image.slidesharecdn.com/mcstutorial1st-releasever-190806052151/85/slide-66-320.jpg)
![ベイズ統計理論
• 自由エネルギーに登場したものと同じλを用いて、汎化損失
と経験損失の漸近挙動を記すことができる:
• 一般の汎化損失と経験損失の漸近挙動
𝔼 𝐺 𝑛 = 𝑆 +
𝜆
𝑛
+ 𝑜
1
𝑛
𝔼 𝑇𝑛 = 𝑆 +
𝜆 − 2𝜈
𝑛
+ 𝑜
1
𝑛
• ここで新たに登場した𝜈は特異ゆらぎと呼ばれ、対数モデルの事後分散の総和
𝑉𝑛 =
𝑖=1
𝑛
𝔼 𝑤 log 𝑝 𝑋𝑖 𝑤 2 − 𝔼 𝑤 log 𝑝 𝑋𝑖 𝑤 2
を用いて2𝜈 = 𝔼 𝑉𝑛 と書ける。𝑉𝑛は汎函数分散と呼ばれる。
汎化損失・経験損失においても、
(実現可能な)正則モデルの場合は
𝜆 = 𝜈 =
𝑑
2
が成立する。
こちらも古くから知られていた
→赤池情報量規準AIC[Akaike, 1977]
68](https://image.slidesharecdn.com/mcstutorial1st-releasever-190806052151/85/slide-67-320.jpg)
![学習理論のゼータ函数
一般に、qからpへのKL情報量すなわち平均誤差函数をK、事前分布をφとする
とき、学習理論のゼータ函数が次で定義される:
ζ(z)=∫K(w)zφ(w)dw.
• ζ(z)は複素数平面全体に有理型函数として一意に解析接続され、その極
はすべて負の有理数となることが証明できる[Atiyah, 1970]。
• 最大極の絶対値を実対数閾値と,その極の位数を多重度と呼ぶ。
平均誤差関数は𝑲 𝒘 = ∫ 𝒒(𝒙) 𝐥𝐨𝐠
𝒒 𝒙
𝒑 𝒙 𝒘
𝒅𝒙
𝐎𝐗 𝐗 𝐗 𝐗 𝐗
𝟏/ 𝒛 + 𝝀 𝑚
ℂ
具体的なモデルについてFn及びGnの挙動を知りたければ、
上記ゼータ函数の最大極を調べればよい。
→たくさんの研究(Aoyagi, Drton, Rusakov, Yamazaki,…)
公式10本ノック?watanabe-www.math.dis.titech.ac.jp/users/swatanab/joho-gakushu5.html
69](https://image.slidesharecdn.com/mcstutorial1st-releasever-190806052151/85/slide-68-320.jpg)


![広く使える情報量規準
ベイズ統計理論の結果から、新たな情報量規準が作られた。
• 広く使える情報量規準WAIC[Watanabe, 2010]:
WAIC = 𝑇𝑛 +
𝑉𝑛
𝑛
, 𝔼 WAIC = 𝔼 𝐺 𝑛 + 𝑜
1
𝑛
• 経験損失𝑇𝑛と汎函数分散𝑉𝑛は共にデータから計算できる量である。
73](https://image.slidesharecdn.com/mcstutorial1st-releasever-190806052151/85/slide-71-320.jpg)


![広く使えるベイズ情報量規準
ベイズ統計理論の結果から、新たな情報量規準が作られた。
• 広く使えるベイズ情報量規準WBIC[Watanabe, 2013]:
WBIC = −𝔼 𝑤
1
log 𝑛
log 𝑃 𝑋 𝑛|𝑤 , WBIC = 𝐹𝑛 + 𝑂𝑝 log 𝑛
‒ 𝔼 𝑤
𝛽
⋅ は「逆温度βの事後分布𝜓 𝛽」による平均:
𝜓 𝛽 𝑤 𝑋 𝑛
≔
𝑃 𝑋 𝑛
𝑤 𝛽
𝜑 𝑤
∫ 𝑃 𝑋 𝑛 𝑤 𝛽 𝜑 𝑤 𝑑𝑤
, 𝔼 𝑤
𝛽
⋅ : = ⋅ 𝜓 𝛽 𝑤 𝑋 𝑛
𝑑𝑤 .
• 対数尤度log 𝑃 𝑋 𝑛|𝑤 も𝜓 𝛽からのサンプリングもデータから計算できる。
76](https://image.slidesharecdn.com/mcstutorial1st-releasever-190806052151/85/slide-74-320.jpg)





![参考文献
[Akaike, 1977]:
“Likelihood and Bayes Procedure”
[Atiyah, 1970]:
“Resolution of singularities and division of distributions”
[Schwarz, 1978]:
“Estimating the dimension of a model”
[Watanabe, 2009]:
“Algebraic Geometry and Statistical Learning Theory”
[Watanabe, 2010]:
“Asymptotic equivalence of Bayes cross validation and widely applicable
information criterion in singular learning theory”
[Watanabe, 2013]:
“A widely applicable Bayesian information criterion”
82](https://image.slidesharecdn.com/mcstutorial1st-releasever-190806052151/85/slide-80-320.jpg)

ベイズ統計学の基礎概念からW理論まで概論的に紹介するスライドです.数理・計算科学チュートリアル実践のチュートリアル資料です.引用しているipynbは * http://nhayashi.main.jp/codes/BayesStatAbstIntro.zip * https://github.com/chijan-nh/BayesStatAbstIntro を参照ください. 以下,エラッタ. * 52 of 80:KL(q||p)≠KL(q||p)ではなくKL(q||p)≠KL(p||q). * 67 of 80:2ν=E[V_n]ではなくE[V_n] → 2ν (n→∞). * 70 of 80:AICの第2項は d/2n ではなく d/n. * 76 of 80:βH(w)ではなくβ log P(X^n|w) + log φ(w). - レプリカ交換MCと異なり、逆温度を尤度にのみ乗することはWBIC導出では本質的な仮定となる.
















![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

















































