Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
SN
Uploaded by
Shushi Namba
PPTX, PDF
9,563 views
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
Osaka.stan #3にて発表した6章「統計モデリングの視点から確率分布の紹介」という資料です。
Data & Analytics
◦
Read more
16
Save
Share
Embed
Embed presentation
Download
Downloaded 141 times
1
/ 156
2
/ 156
Most read
3
/ 156
4
/ 156
5
/ 156
6
/ 156
Most read
7
/ 156
8
/ 156
9
/ 156
10
/ 156
11
/ 156
12
/ 156
13
/ 156
14
/ 156
15
/ 156
16
/ 156
17
/ 156
18
/ 156
19
/ 156
20
/ 156
21
/ 156
22
/ 156
23
/ 156
24
/ 156
Most read
25
/ 156
26
/ 156
27
/ 156
28
/ 156
29
/ 156
30
/ 156
31
/ 156
32
/ 156
33
/ 156
34
/ 156
35
/ 156
36
/ 156
37
/ 156
38
/ 156
39
/ 156
40
/ 156
41
/ 156
42
/ 156
43
/ 156
44
/ 156
45
/ 156
46
/ 156
47
/ 156
48
/ 156
49
/ 156
50
/ 156
51
/ 156
52
/ 156
53
/ 156
54
/ 156
55
/ 156
56
/ 156
57
/ 156
58
/ 156
59
/ 156
60
/ 156
61
/ 156
62
/ 156
63
/ 156
64
/ 156
65
/ 156
66
/ 156
67
/ 156
68
/ 156
69
/ 156
70
/ 156
71
/ 156
72
/ 156
73
/ 156
74
/ 156
75
/ 156
76
/ 156
77
/ 156
78
/ 156
79
/ 156
80
/ 156
81
/ 156
82
/ 156
83
/ 156
84
/ 156
85
/ 156
86
/ 156
87
/ 156
88
/ 156
89
/ 156
90
/ 156
91
/ 156
92
/ 156
93
/ 156
94
/ 156
95
/ 156
96
/ 156
97
/ 156
98
/ 156
99
/ 156
100
/ 156
101
/ 156
102
/ 156
103
/ 156
104
/ 156
105
/ 156
106
/ 156
107
/ 156
108
/ 156
109
/ 156
110
/ 156
111
/ 156
112
/ 156
113
/ 156
114
/ 156
115
/ 156
116
/ 156
117
/ 156
118
/ 156
119
/ 156
120
/ 156
121
/ 156
122
/ 156
123
/ 156
124
/ 156
125
/ 156
126
/ 156
127
/ 156
128
/ 156
129
/ 156
130
/ 156
131
/ 156
132
/ 156
133
/ 156
134
/ 156
135
/ 156
136
/ 156
137
/ 156
138
/ 156
139
/ 156
140
/ 156
141
/ 156
142
/ 156
143
/ 156
144
/ 156
145
/ 156
146
/ 156
147
/ 156
148
/ 156
149
/ 156
150
/ 156
151
/ 156
152
/ 156
153
/ 156
154
/ 156
155
/ 156
156
/ 156
More Related Content
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
Stanの便利な事後処理関数
by
daiki hojo
PPTX
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
by
Masashi Komori
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PPTX
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
PDF
負の二項分布について
by
Hiroshi Shimizu
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
階層モデルの分散パラメータの事前分布について
by
hoxo_m
Stanの便利な事後処理関数
by
daiki hojo
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
by
Masashi Komori
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
負の二項分布について
by
Hiroshi Shimizu
What's hot
PPTX
15分でわかる(範囲の)ベイズ統計学
by
Ken'ichi Matsui
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
関数データ解析の概要とその方法
by
Hidetoshi Matsui
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
PDF
質的変数の相関・因子分析
by
Mitsuo Shimohata
PDF
Rで階層ベイズモデル
by
Yohei Sato
PDF
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
pymcとpystanでベイズ推定してみた話
by
Classi.corp
PPTX
ブートストラップ法とその周辺とR
by
Daisuke Yoneoka
PDF
あなたの心にBridgeSampling
by
daiki hojo
PDF
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
統計的学習の基礎 5章前半(~5.6)
by
Kota Mori
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PDF
Chapter9 一歩進んだ文法(前半)
by
itoyan110
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
15分でわかる(範囲の)ベイズ統計学
by
Ken'ichi Matsui
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
関数データ解析の概要とその方法
by
Hidetoshi Matsui
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
質的変数の相関・因子分析
by
Mitsuo Shimohata
Rで階層ベイズモデル
by
Yohei Sato
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
2 3.GLMの基礎
by
logics-of-blue
pymcとpystanでベイズ推定してみた話
by
Classi.corp
ブートストラップ法とその周辺とR
by
Daisuke Yoneoka
あなたの心にBridgeSampling
by
daiki hojo
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
Stan超初心者入門
by
Hiroshi Shimizu
階層ベイズとWAIC
by
Hiroshi Shimizu
統計的学習の基礎 5章前半(~5.6)
by
Kota Mori
変分ベイズ法の説明
by
Haruka Ozaki
Chapter9 一歩進んだ文法(前半)
by
itoyan110
ノンパラベイズ入門の入門
by
Shuyo Nakatani
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
Viewers also liked
PDF
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
PDF
データ解析のための統計モデリング入門 1~2章
by
itoyan110
PDF
StanとRで折れ線回帰──空間的視点取得課題の反応時間データを説明する階層ベイズモデルを例に──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PDF
Osaka.Stan #3 Chapter 5-2
by
Takayuki Goto
PPTX
馬に蹴られるモデリング
by
Shushi Namba
PDF
Stanでpsychophysics──階層ベイズモデルで恒常法データを分析する──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PDF
魅せる・際立つ・役立つグラフ Hands on!! ggplot2!! ~導入編~
by
MrUnadon
PPTX
NagoyaStat #5 データ解析のための 統計モデリング入門 第10章
by
nishioka1
PPTX
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
PDF
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
PPTX
Osaka.stan#4 chap8
by
Takashi Yamane
PPTX
シンポジウム「データの時代の心理学」指定討論
by
Masashi Komori
PPTX
Mental model for emotion
by
Shushi Namba
PPTX
Osaka.stan#2 chap5-1
by
Makoto Hirakawa
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
データ解析のための統計モデリング入門 1~2章
by
itoyan110
StanとRで折れ線回帰──空間的視点取得課題の反応時間データを説明する階層ベイズモデルを例に──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
Osaka.Stan #3 Chapter 5-2
by
Takayuki Goto
馬に蹴られるモデリング
by
Shushi Namba
Stanでpsychophysics──階層ベイズモデルで恒常法データを分析する──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
魅せる・際立つ・役立つグラフ Hands on!! ggplot2!! ~導入編~
by
MrUnadon
NagoyaStat #5 データ解析のための 統計モデリング入門 第10章
by
nishioka1
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
Osaka.stan#4 chap8
by
Takashi Yamane
シンポジウム「データの時代の心理学」指定討論
by
Masashi Komori
Mental model for emotion
by
Shushi Namba
Osaka.stan#2 chap5-1
by
Makoto Hirakawa
Similar to StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
「全ての確率はコイン投げに通ず」 Japan.R 発表資料
by
Ken'ichi Matsui
PDF
PRML輪読#2
by
matsuolab
PDF
[PRML] パターン認識と機械学習(第2章:確率分布)
by
Ryosuke Sasaki
PDF
MLaPP 5章 「ベイズ統計学」
by
moterech
PDF
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PDF
PRML2.1 2.2
by
Takuto Kimura
PDF
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PPTX
色々な確率分布とその応用
by
Hiroki Iida
PPTX
Beta distribution and Dirichlet distribution (ベータ分布とディリクレ分布)
by
Taro Tezuka
PDF
Pattern Recognition and Machine Learning study session - パターン認識と機械学習 勉強会資料
by
Taro Masuda
PDF
PRML 2.3.1-2.3.2
by
KunihiroTakeoka
PPTX
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
PPTX
Bernoulli distribution and multinomial distribution (ベルヌーイ分布と多項分布)
by
Taro Tezuka
PDF
PRML復々習レーン#3 前回までのあらすじ
by
sleepy_yoshi
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PPT
C:\D Drive\Prml\プレゼン\パターン認識と機械学習2 4章 D0703
by
Yoshinori Kabeya
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
Infer net wk77_110613-1523
by
Wataru Kishimoto
ベイズ統計入門
by
Miyoshi Yuya
Stanコードの書き方 中級編
by
Hiroshi Shimizu
「全ての確率はコイン投げに通ず」 Japan.R 発表資料
by
Ken'ichi Matsui
PRML輪読#2
by
matsuolab
[PRML] パターン認識と機械学習(第2章:確率分布)
by
Ryosuke Sasaki
MLaPP 5章 「ベイズ統計学」
by
moterech
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PRML2.1 2.2
by
Takuto Kimura
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
色々な確率分布とその応用
by
Hiroki Iida
Beta distribution and Dirichlet distribution (ベータ分布とディリクレ分布)
by
Taro Tezuka
Pattern Recognition and Machine Learning study session - パターン認識と機械学習 勉強会資料
by
Taro Masuda
PRML 2.3.1-2.3.2
by
KunihiroTakeoka
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
Bernoulli distribution and multinomial distribution (ベルヌーイ分布と多項分布)
by
Taro Tezuka
PRML復々習レーン#3 前回までのあらすじ
by
sleepy_yoshi
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
C:\D Drive\Prml\プレゼン\パターン認識と機械学習2 4章 D0703
by
Yoshinori Kabeya
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
Infer net wk77_110613-1523
by
Wataru Kishimoto
More from Shushi Namba
PPTX
ベイズモデリングで見る因子分析
by
Shushi Namba
PDF
ベイズモデリングと仲良くするために
by
Shushi Namba
PPTX
心理学における「再現性」の問題とBayes Factor
by
Shushi Namba
PPTX
ベイズ統計モデリングと心理学
by
Shushi Namba
PPTX
変数同士の関連_MIC
by
Shushi Namba
PPTX
主成分分析(Pca)
by
Shushi Namba
PDF
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
PPTX
Rはいいぞ!むしろなぜ使わないのか!!
by
Shushi Namba
PPTX
表情から見た情動
by
Shushi Namba
PPTX
回帰モデルとして見る信号検出理論
by
Shushi Namba
PDF
Psychophysical functions@BCM勉強会
by
Shushi Namba
PPTX
今夜は動的モデリングよ~Dynrで簡単クッキング!~
by
Shushi Namba
PDF
がんばろう!はじめてのDnn!
by
Shushi Namba
ベイズモデリングで見る因子分析
by
Shushi Namba
ベイズモデリングと仲良くするために
by
Shushi Namba
心理学における「再現性」の問題とBayes Factor
by
Shushi Namba
ベイズ統計モデリングと心理学
by
Shushi Namba
変数同士の関連_MIC
by
Shushi Namba
主成分分析(Pca)
by
Shushi Namba
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
Rはいいぞ!むしろなぜ使わないのか!!
by
Shushi Namba
表情から見た情動
by
Shushi Namba
回帰モデルとして見る信号検出理論
by
Shushi Namba
Psychophysical functions@BCM勉強会
by
Shushi Namba
今夜は動的モデリングよ~Dynrで簡単クッキング!~
by
Shushi Namba
がんばろう!はじめてのDnn!
by
Shushi Namba
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
1.
統計モデリングの視点 から確率分布の紹介 Osaka.Stan #3 広島大学 難波修史 StanとRで
ベイズ統計モデリング読書会
2.
自己紹介 • 難波修史 @Nsushi •
広島大学教育学研究科心理学専攻D生 • 専門:顔、感情、ド文系 • 興味:ベイズ • 使用言語:Python, R • R歴:初心者
3.
過去の発表 日本最大級のRのイベントで「にっこにっこにー」 というアニメの決め台詞を口にし、ダダ滑りした人
4.
本発表の対象者 •「数式に苦手意識あり」、「統計モ デリング初学者」、「でも勉強しと かないとやばい気がする」という 方々をメインにしています。 •僕も上記の対象者に含まれます。
5.
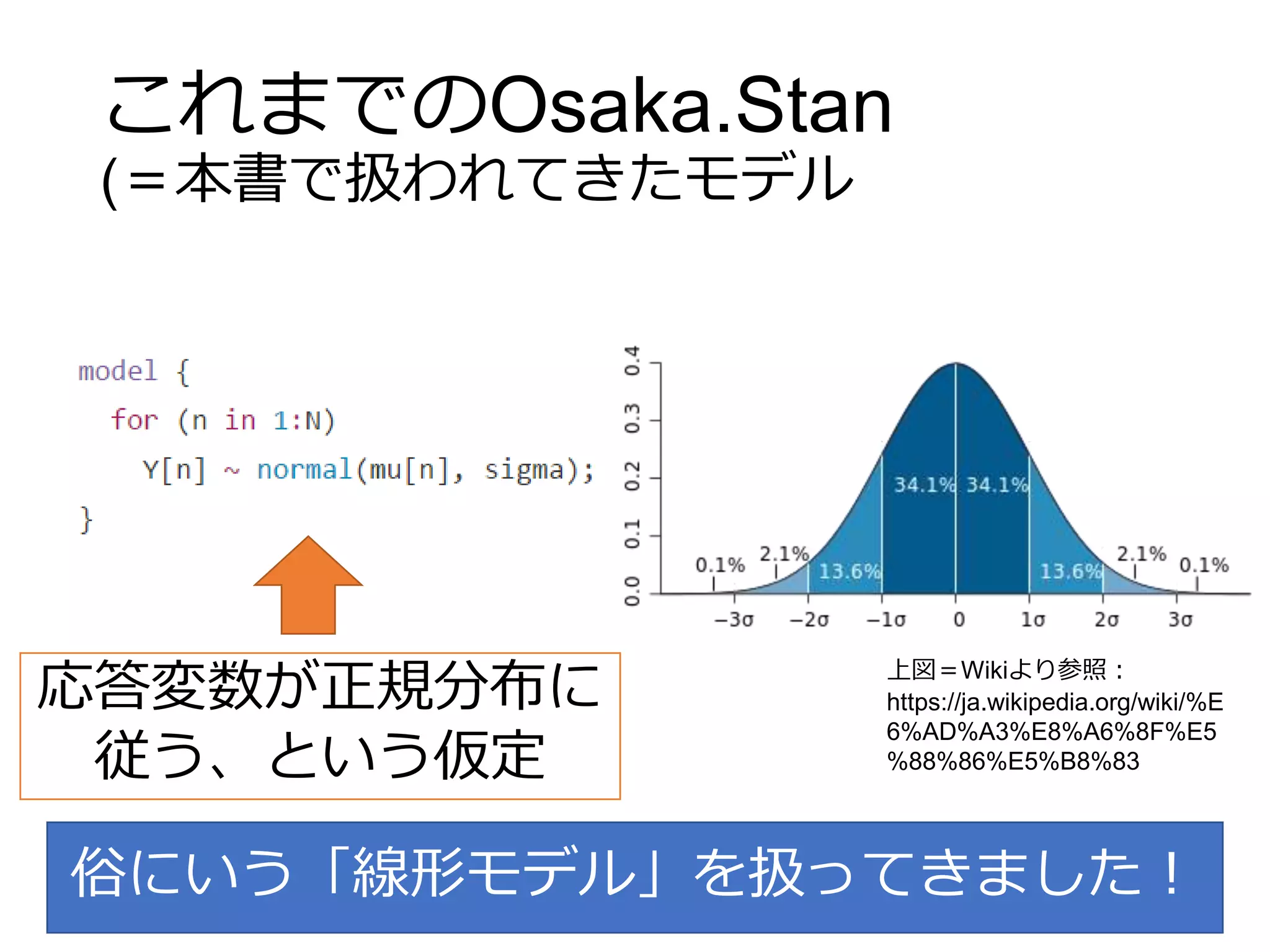
これまでのOsaka.Stan (=本書で扱われてきたモデル 応答変数が正規分布に 従う、という仮定 上図=Wikiより参照: https://ja.wikipedia.org/wiki/%E 6%AD%A3%E8%A6%8F%E5 %88%86%E5%B8%83 俗にいう「線形モデル」を扱ってきました!
6.
これまでの (心理) 統計 •
因子分析の前提=データが正規分布して いること (松尾・中村、2002) • 分散分析の前提=データが正規分布して いること(村山先生のHP 我々=すでに正規分布のフレンズ
7.
感想 正 規 分 布 ©なんJ
8.
今後の話 線形モデル (正規分布がメイン 一般化線形モデル (Chapter 5も含む 正規分布以外 の確率分布を 扱いたい。 このための準備 (正規分布以外 の確率分布の知識)
が必要!!
9.
正規分布以外の分布を 使う必要性? •応答変数が明らかに正規分布しない 例:出席率 (5-2等)、履修登録 (5-4) •データが少ない場合に推定がうまく いかない
→ 事前分布による調整が 必要な場合も 例:コーシー分布や t 分布 (10章等)
10.
他の分布の理解は必要不可欠 •ベイズ統計モデリングでは、事前分 布を選択する時にも確率分布に関す る最低限の理解が必要 • 色んな分布と適用例を詳しく 知りたい人は豊田 (2015,
2017) を読もう→
11.
この章の目的 •この本の読者 =統計モデリングがしたい! •基本的な道具を知っておかないと! (よく使われる)確率分布 をまずは知りましょう!!
12.
ま だ
13.
分布の紹介時の注意① • 本資料では松浦本と同様、数学的に扱い やすい分散でなく標準偏差を記載します。 • 理由1.平均と標準偏差は同じ単位で比 較しやすく、モデリングを考察しやすい •
理由2.正規分布を指定する関数では引 数として、標準偏差をとるため
14.
分布の紹介時の注意② 関数や平均などの情報も一応記載 していますが、基本的にはイメー ジをつかむことを優先して淡々と 作成した資料です。 過度な期待はしないでください。 (また、誤りがあれば適宜ご指摘ください
15.
分布勉強におすすめのアプリ • http://statdist.ksmzn.com/ • @ksmzn様が作成したShinyで確率分布 を動かして遊べるページがあります。 •
6章を読みながらパラメータをいじって いろんな確率分布とフレンドになりま しょう!! • 右図=Interface 「確率分布いろいろ」でググる!
16.
分布勉強におすすめの…
17.
一様分布
18.
一様分布とは •特定区間の確率が等しい分布
19.
6.1 一様分布 • 確率密度関数(確率変数を記述する関数 •
Uniform (y | a,b) 1 𝑏−𝑎 (a ≦ x ≦ b) 0 上記以外
20.
一様分布 • パラメータ:実数a, b
(a < b) • 範囲:y=[a, b]の範囲の実数 • 平均:(a+b) / 2 • 標準偏差:(b-a) / √12
21.
一様分布の例 a = -2,
b = 1
22.
使用例:無情報事前分布 • 無情報事前分布=事後分布を求める際 に、影響を与えないような分布 一様分布=特定区間の確率が等しい分布
23.
Stanでは? •Stan:パラメータの事前分布を明示 的にmodelブロックで設定しない → とりうる範囲で一様な事前分布 が設定される!
24.
例:model4-5.stan • 右図では各パラメータ で明示的な事前分布が 設定されてない a ~
uniform(-∞, ∞) b ~ uniform(-∞, ∞) sigma ~ uniform(0, ∞) ← 下限設定のため modelブロックには以下 が非明示的に設定される
25.
ベルヌーイ分布
26.
ベルヌーイ分布とは •表裏があるコインの表が出る 確率の分布
27.
6.2 ベルヌーイ分布 • 確率質量関数(離散だと密度ではなく質量 •
Bernoulli (y | θ) θ y = 1の場合 1 − θ y=0の場合 ※θ 𝑦 1 − θ 1 − 𝑦
28.
ベルヌーイ分布 • パラメータ: θ
[0,1] の範囲の実数 • 範囲:y=0か1のいずれかの整数値 • 平均: θ • 標準偏差:√θ(1 − θ)
29.
ベルヌーイ分布の例 θ=0.2 (例:けん玉 側面にのせる 成功確率
30.
例①:コイン • コインの表・裏のような2値を表現する 際に用いる (他には薬が効く、効かない など)。
31.
例②:出席率 •パラメータθ= [0, 1]
の範囲の実数 •出席率 (欠席=0、出席=1) のような 応答変数に対して、ロジスティック 関数と組み合わせて用いることが多 い (具体例など詳しくは5-3)。
32.
二項分布
33.
二項分布とは •ベルヌーイ分布に従う試行 をN回行った結果の確率に 関する分布
34.
6.3 二項分布 • 確率質量関数 •
Binomial (y | N, θ) N! 𝑦! 𝑁 −𝑦 ! θ 𝑦 1 − θ 𝑁 − 𝑦
35.
二項分布 • パラメータ: N=正の整数、θ=[0,1] の範囲の実数 •
範囲:y=0,1, … N のいずれかの整数値 • 平均: Nθ (1いれるとベルヌーイ分布と一致 • 標準偏差:√Nθ(1 − θ)
36.
二項分布の例 N = 10 θ=0.2 ×
10
37.
二項分布の再生性 • Nの異なる同じパラメータθの二項分布か ら確率変数y1とy2が生成される → y1
+ y2 はBinomial (N1 + N2, θ) に従う コイン表が出るパラメータ=多分0.5 × 10 × 6 = × 16 Binom (10, 0.5) Binom (6, 0.5) Binom (16, 0.5) +
38.
例 • Nが与えられた場合のベルヌーイと同様 • 具体的な例は5-2
39.
ベータ分布
40.
ベータ分布とは •ベルヌーイ・二項分布と共役 な関係 (事後分布算出に都合 のいい性質) を持つ分布
41.
6.4 ベータ分布 • 確率密度関数 •
Beta (θ| α, β) 1 𝐵 α,β θα − 1 1 − θ β − 1
42.
ベータ分布 • パラメータ: α、β=正の実数 •
範囲:θ=[0,1]の範囲の実数 • 平均: α α+β • 標準偏差: √αβ α+β √α+β+1 • 範囲 0-1 の連続型分布=確率θ生成分布 → 尤度がベルヌーイ・二項分布時に利用可能 +その他の [0, 1] の範囲の変数にも適用可能
43.
ベータ分布の挙動① α=1, β=1 → 標準一様分布と等価 α固定、β変化 →
β小さくなる → 平均が1へ
44.
ベータ分布の挙動② α=0.5, β=0.5 → 逆正弦分布と等価 ?逆正弦分布: http://physnotes.jp/stat/asin_d/ β固定、α変化 →
α大きくなる → 平均が1へ
45.
ベータ分布の挙動③ 極めて多様な 分布形状をと ることができ るのが特徴 参照: http://www.ntrand.com/jp /beta-distribution/
46.
使用例:広島大学平川先生の資料より拝借(ベータ分布とは: http://www.slideshare.net/makotohirakawa3/nituite) ベルヌーイ・二項分布におけるパラメータの場合が多い
47.
書籍内での例:故障率 • 見たいパラメータ=故障率 • M個中Y個故障×N品目 イメージ図
[N = 1:アンパン] モデル式 θ ~ Beta(α、β) #故障率パラメータ Y ~ Binomial (M, θ) ジャムおじさん のパン工場 3つのアンパンと 1つのこげパン
48.
ジャムおじさん (データ生成源) に関する事前情報を設定可能 • 書籍ではN品目間の違いから弱情報事前 分布をイメージ+設定 あのおじさん ムラがはんぱ ないよね。 →
α、βにちょっ とした情報を載 せた解析も可能 まぁ、基本的には我々が科学的な用途で 用いる場合、無情報を設定しましょう。 かばおくん リアルな ジャムおじさん
49.
カテゴリカル分布、 多項分布、 ディリクレ分布
50.
基本的に… カテゴリカル分布・多項分布・ ディリクレ分布 これらの分布はベルヌーイ分布・ 二項分布・ベータ分布を拡張した ものです。 これらが分かっていれば理解は 比較的簡単…なはず!!
51.
分布間の関係 参考:http://machine- learning.hatenablog.com/ent ry/2016/03/26/211106 ?共役=尤度関数 (データ) と掛けて事後分布を求めると関数系が同じになるやつ
52.
カテゴリカル分布
53.
カテゴリカル分布とは •kの目が出る確率 (生起確 率) が𝜃
𝐾であるようなK面 を持つサイコロの分布
54.
6.5 カテゴリカル分布 • 確率質量関数 •
Categorigal (y = 𝑘|θ) = θk ※Categorigal (y = 2|θ) ≠ Bernoulli (θ) ※ 𝑘=1 K θ 𝑘 𝑦𝑘
55.
カテゴリカル分布 • パラメータ: K=2以上の正の整数 θ=長さKのベクトル、各要素は[0,1]の 範囲の実数で合計すると1になる。 •
範囲:y=1,2, … Kのいずれかの整数 • 平均: I[y = k] の平均=θ 𝑘 • 分散共分散:I[y = k] の分散=θ 𝑘 (1 − θ 𝑘) I[y = k] とI[y = k’] の共分散 (k ≠ k’)=−θ 𝑘θ 𝑘‘ I[y = k] は y = k となる場合に1を返し、それ以外は0を返す関数
56.
カテゴリカル分布の例 • 右図:K=5, 𝜃=(0.1,
0.2, 0.25,0.35, 0.1)T • 確率なので合計は1
57.
使用例:ソフトマックス回帰 • 店Aに3つの商品 (チョコ、飴、グミ)
があると する (K = 3)。 • その選択に関わりそうな説明変数=性別のみと する。 すると以下のモデル式が提案可能。 • μ[n] = a + b*Sex[n] n = 個人 • θ[n] = softmax (μ[n]) = ベクトル • Y[n] ~ Categorical(θ[n]) 長さKのベクトル=3商品 の選択に関する線形結合 ※softmax関数=expを用いて [-∞, ∞] をとりう る値を正の値にしてから、合計が1になる (カテ ゴリカル分布にあう) ように規格化するもの
58.
多項分布
59.
多項分布とは •kの目が出る確率が𝜃 𝐾であるようなK 面を持つ (カテゴリカル分布に従う) サイコロ投げをN回行ったときの、 各目の出る確率を示す分布 •イメージ:二項分布の拡張
(ただし K=2の多項分布=y1, y2をカウント ⇔二項分布=生起回数のみカウン ト)
60.
6.6 多項分布 • 確率質量関数 •
Multinomial (y|𝑁, θ) = N! Π 𝑘=1 𝐾 𝑦 𝑘 𝑘=1 K θ 𝑘 𝑦𝑘
61.
多項分布 • パラメータ: K=2以上の正の整数、 N=正の整数 θ=長さKのベクトル、各要素は
[0,1] の 範囲の実数で合計すると1になる。 • 範囲:y=長さKのベクトル。各要素は0,1, … Nのいずれかの整数で合計するとNになる • 平均: yk の平均=Nθ 𝑘 • 分散共分散:yk の分散=Nθ 𝑘 (1 − θ 𝑘) yk と yk’ の共分散 (k ≠ k’)=−Nθ 𝑘θ 𝑘‘
62.
多項分布の例 N=3, 𝜃=(0.3, 0.3,
0.4)T (参照 http://www.biwako.shiga- u.ac.jp/sensei/mnaka/ut/statdist.html
63.
使用例 •Nが与えられたカテゴリカル分 布、でOK ⇔ 試行回数1の多項 分布=カテゴリカル分布 •
実際、平均や分散などもカテゴリカル分布 のやつにNがかけられてるだけ(本参照) (ベルヌーイ・二項分布も同じ関係
64.
式的な差異 • カテゴリカル分布 • 多項分布 試行回数の要素 中身はほぼ一緒
65.
ディリクレ分布
66.
ディリクレ分布とは =ベータ分布の多変量版。多項・カテゴ リカル分布の共役事前分布 =「合計すると1になる確率のベクトル𝜽」 を生成する分布。 ゆえに重要!
67.
6.7 ディリクレ分布 • 確率密度関数 •
Dirichlet (θ|α) = 1 B(α) 𝑘=1 K θ 𝑘 α 𝑘−1 正規化定数 カーネル Q. 正規化定数?カーネル? A. 前者は積分を1にするための定数 (定義は本家) 後者は確率分布の本質的な部分
68.
ディリクレ分布 • パラメータ: K=2以上の正の整数、 α=各要素は正の実数。 •
範囲:θ=長さKのベクトル。各要素は (0,1) の範囲の実数で合計すると1になる • 平均: θk の平均=α 𝑘/αsum • 分散共分散: θk の分散=α 𝑘 αsum − α 𝑘 / α 𝑠𝑢𝑚 2 (α 𝑠𝑢𝑚+1) θk と θk’ の共分散 (k ≠ k’)=−α 𝑘α 𝑘‘/(α 𝑠𝑢𝑚 2 (α 𝑠𝑢𝑚+1)) ※ 𝑘=1 𝐾 α 𝑘 = α 𝑠𝑢𝑚とする
69.
視覚化①(参照:http://y-mattu.hatenablog.com/entry/2016/03/03/143451 • 我々にぎりぎり可視化できる3次元の図 αが高い =確実性 が高い
70.
視覚化② • 歪んだパラメータ 平均をとると、(0.09, 0.23,0.68) =わー!確率になります!!
71.
使用例:多項・カテ分布のパラメータθベクトル生成 • θをデータから推定する。αは固定値を与 えることもあれば、データから推定する こともある。 • ディリクレ分布=どんな形のサイコロを 生成しやすいかを決める分布ともいえる。
72.
具体例 • 店Aの例 (3商品:チョコ、飴、グミ)
で いうとグミだけ選ばれやすいαの事前分 布の例は以下。 • θ = Dirichlet (α1 = 1, α2 = 1, α3 = 8) • Y ~ Categorical(θ) チョコ 飴 グミ
73.
指数分布
74.
指数分布とは •事象の生起間隔 (ある事象が起こって 次にまた発生するまでの間隔) の確率 •
ランダムなイベントの発生間隔を表す分布
75.
6.8 指数分布 • 確率密度関数 •
Exponential (y|λ) = λexp(−λ𝑦) 超参照(指数分布とポアソン分布のいけない関係): http://www.slideshare.net/teramonagi/ss-11296227 ※ 本家ではλではなくβですが、後でポアソン分布との関係をわ かりやすくするためあえてλとしています。 ※λ𝑒 − λ𝑦
76.
指数分布 • パラメータ: λ(rate)=正の実数 •
範囲:y = y≧0の実数 • 平均: 1/λ • 標準偏差:1/λ ただ一つのパラメータ だけで特徴づけられる パラメータはいつも一つ +コナン君
77.
指数分布の例
78.
指数分布の無記憶性 • 無記憶性を持つ連続型の確率分布 • Pr(y
> s+t | y > t) = P(y > s) • 次に事象が発生するまでの時間 は今まで待った時間と関係ない 指数分布の擬人化 記憶なくす人
79.
無記憶性の例 Pr(y > s+t
| y > t) = P(y > s) 例: 指数分布に従うワイングラス が壊れるまでの時間 → 3年 (t) 使っても壊れない → その先1年 (s+t) で壊れる確率 = 使い始め1年 (s) で壊れる確率 2日連続で 記憶失う人
80.
データ・使用例 • パラメータλの解釈=ある時間中におけ る事象の平均生起回数 → 事故・地震の発生間隔など •
正の実数を持つパラメータを生成する分 布として使うことも(10章参照
81.
計算してみる • 1時間に平均5人が訪れるWebサイト → 次の訪問者が来るまでの間隔が12分 である確率を求めよ •
λ=5, y = 12 / 60を公式に代入 • 確率“密度”=1を超える tera-monagi様の資料より参照:http://www.slideshare.net/teramonagi/ss-11296227
82.
ポアソン分布
83.
ポアソン分布とは •単位時間 (1時間・1秒間など) 当た りのある事象の生起確率 •単位時間あたり平均λ回起こるラン ダムな事象が単位時間中にy回起こ る確率= 1 𝑦! λ
𝑦 exp(−λ)
84.
6.9 ポアソン分布 • 確率密度関数 •
Poisson (y|λ) = 1 𝑦! λ 𝑦 exp(−λ) 参照=tera-monagi様の「指数分布とポアソン分布のいけない 関係」:http://www.slideshare.net/teramonagi/ss-11296227
85.
ポアソン分布 • パラメータ: λ=正の実数 •
範囲:y=0,1,2…のいずれかの整数値 • 平均: λ • 標準偏差:√λ ただ一つのパラメーター だけで特徴づけられる パラメータ=平均なので 「パラメータλのポアソン分布」 or「平均λのポアソン分布」 呼び方
86.
ポアソン分布の例 λ=2.5
87.
ポアソン分布の再生性 • 同じパラメータλのポアソン分布から確率 変数y1とy2が生成される → y1
+ y2 はPoisson (λ1 + λ2) に従う とあるアカウントがつぶやくパラメータ=1時間当たり2.5 y1 y2 y1+y2+ = 2時間に5回 4時間に10回 6時間に15回
88.
指数分布とポアソンの関係① • 単位時間あたり平均 λ
回起こるような ランダムなイベントに対して、 1.一単位時間にイベントが起きる 回数は平均 λ のポアソン分布に従う。 2.イベントの発生間隔は平均 1 / λ の指数分布に従う。
89.
指数分布とポアソンの関係② 同一のある“事象”に対して • ポアソン分布=単位時間当たり平均 λ
回 → 回数に注目 • 指数分布=平均 1/λ 単位時間に一回 → 時間に注目! シミュレーションはtera-monagi様の資料を参照(指数分布とポアソン分布 のいけない関係):http://www.slideshare.net/teramonagi/ss-11296227
90.
二項分布とポアソンの関係 •Nが大きく、θが小さい二項分布 → ポアソン分布に近似!! 証明の仕方は各自ググるなり、以下のスライドを参照するなりし てください(itoyan110様の「ベルヌーイ分布からベータ分布まで を関係づける」http://www.slideshare.net/itoyan110/ss-69491897 すごーいって 言ってるサー バルちゃん
91.
正規分布とポアソンの関係 •λが大きいポアソン分布 → 正規分布に近似!! 証明の仕方は各自ググるなりしてください すごーいって 言ってるサー バルちゃん
92.
データ例① • 1日の間に観測される動物の個体数、1 時間の間に届くメールの数 (指数分布の 解説も含むよい例が以下のサイトに (http://www.ntrand.com/jp/poisson-distribution/)
)、これら は背後に指数分布に従うイベントが考え られる。 例は「馬に蹴られてポアソン分布」でググ れば一番上にでてきます (2017.2月現在)。
93.
データ例② • マンボウが卵を生んで、成魚になる 数、これは背後に二項分布があって、 Nが大きくθが小さいと考えられる。
94.
使用例 • カウントデータに対して使う場合が多い • 具体的な例は5-4
95.
ガンマ分布
96.
ガンマ分布とは? • 流れ星の例で考える • 流れ星がα個観測されるまでの時間 →
ガンマ分布 =母数βの指数分布に従う事象がα回 生じるまでの時間の分布 お笑い芸人の 流れ星のプロ フィール画像
97.
6.10 ガンマ分布 • 確率密度関数 •
Gamma(y|α, β) = βα Γ(α) 𝑦α−1 exp(−β𝑦) 正規化定数 カーネル 正規化定数の定義は本家を参照
98.
ガンマ分布 • パラメータ:α (shape),
β (rate)=正の実数 • 範囲:y=正の実数 • 平均: α/β • 標準偏差:√α/β
99.
他の分布との関連 •おなじく流れ星の例 •単位時間あたりに流れる流れ星の数 → ポアソン分布 •流れ星が初めて観測されるまでの時間 → 指数分布
100.
まとめ ポアソン分布=回数、 指数・ガンマ分布=時間に注目 ただし、指数分布の場合は最初の観 測まで。ガンマ分布はα回数観測ま での時間、ゆえにαが1の場合は指数 分布と定義式が一致する(本書参照
101.
ガンマ分布の例 α固定でβ大きく → 平均が小さく
102.
ガンマ分布の再生性 • (一部の分布同様), 同じパラメータβのガンマ 分布から確率変数y1とy2が生成される それの和
→ Gamma(α1 + α2, β) に従う 具 体 例 を 説 明 で き な い ベ ジ ー タ 思い浮か ばなかっ ただけ。
103.
データ例: 広島大学山根先生の資料より拝借(ガンマ 分布:http://tyamane1969.net/?p=97)
104.
使用例:引き続き同資料より抜粋 • 正の実数を持つパラメータを生成する分布とし て使うことが多い。具体例は10章を参照。
105.
正規分布
106.
正規分布とは •平均値μから正負の両方向に 均等に広がる分布 • 色んな現象がN増やしたら概ね正規分 布に近似する (中心極限定理)、様々な 分布と関連するなど、とにかく人気の 分布・統計学における金字塔(多分
107.
6.11 (みんな大好き) 正規分布 •
確率密度関数 • Normal(y|μ, σ) = 1 √2πσ exp(− 1 2 y−μ σ 2)
108.
正規分布 • パラメータ:μ=実数、σ=正の実数 • 範囲:y=実数 •
平均: μ • 標準偏差:σ 親の顔よりも 見慣れた景色
109.
正規分布の再生性 • 確率変数y1 ~
Normal(μ1, σ1) と y2 ~ Normal(μ2, σ2) が独立で生成される → その和=Normal(μ1+ μ2, √ σ1 + σ2) に従う • 例:子供の身長+タケノコ μ1=100 μ2=30 + = μ1 + μ2=130
110.
データ例 •色々。生成メカニズムがよくわかん なくてもとりあえず正規分布をあて はめることが多い。優秀すぎる。 •モデリングでは個人差や潜在変数な ども正規分布を仮定する。
111.
正規分布の特徴 •±2σを超えたあたりから、確率密度関 数の値が小さくなる(=裾が短い) → 外れ値に弱い → 後述するコーシー・t分布を使う ここら辺
ここら辺
112.
使用例 • 5-1の重回帰 • グループ差や個人差が正規分布に従うと 仮定する階層モデルを8章で扱う。 •
また、y≧0の部分だけを取り出して正規 化する半正規分布はパラメータの弱情報 事前分布として用いる場合が多い (10章
113.
こういう教材もあります。 ※キモオタ以外のご視聴はお勧めしておりません。 • ニコニコ動画より「月読アイの理系なお話『神 様が愛した正規分布[前編]』」
114.
対数正規分布
115.
対数正規分布とは: • 対数正規分布の名前 =“ある確率変数が対数正規分布に従うと き、その対数をとった確率変数は正規分 布になる“という性質に由来する 広島大学山根先生の資料より拝 借(Hirodai.stan発表非公開資料 「どういうこと だってばよ?」っ て言ってる忍者
116.
つまり •「低い値に分布が集中する が、まれに高い値も生じ る」データ ⇒ 対数正規分布
117.
6.12 対数正規分布 • 確率密度関数 •
LogNormal(y|μ, σ) = 1 √2πσ 1 𝑦 exp(− 1 2 𝑙𝑜𝑔y−μ σ 2)
118.
対数正規分布 • パラメータ:μ=実数、σ=正の実数 • 範囲:y=実数 •
平均: exp(μ + σ2 / 2) • 標準偏差:exp(μ + σ2/2) √(eσ2-1)
119.
対数正規分布の例
120.
データ例・使用例 • 人間の体重、年収の金額など •上記のデータのほか、正の実数 値をとるパラメータの弱情報事 前分布として利用(10章参照
121.
多変量正規分布
122.
多変量正規分布とは •正定値対称行列である分散共分散行 列を含む、2つ以上 (m次元) の正規 分布の同時密度関数である
(多分)。 2変量の 場合の例
123.
6.13 多変量正規分布 • 確率密度関数 •
MultiNormal(y|μ, Σ) = 1 2π K/2 1 √|Σ| exp(− 1 2 y − μ T Σ−1 y − μ )
124.
多変量正規分布 • パラメータ:K=正の整数、 μ=長さKのベクトルで各要素は実数、 Σ=K×Kの対称な正定値行列 (分散共分散行列 •
範囲:y=長さKのベクトルで各要素は実数 • 平均:ykの平均=μk • 分散共分散:ykの分散=Σk,k ykとyk’の共分散 (k ≠ k’) =Σk,k’ 正定値行列=すべての固有値が正の実数であること、らしい。 ここがキモ!
125.
分散共分散行列:二変量の例 x1=横軸: 一次元目の 正規分布 x2=縦軸: 二次元目の 正規分布 ※多変量正 規分布はm次 元正規分布
126.
他にもいろんな特徴が •再生性あり 腕が生えてる ピッコロさん
127.
すごいぞ!多変量正規分布! • 多変量正規分布に従う確率変数を線形結合 → 多変量正規分布に従う •
周辺化する → 多変量正規分布 • 各変数の条件付き分布 → 多変量正規分布 驚いてる犬
128.
余談 Q. 周辺化? A. 同時確率を足し合わせて特定の確率変 数を消すこと。 Q.
条件付き確率? A. ある事象Yが起こるという条件の下で別 の事象Xが起きる確率:P(X|Y) 黄線のx1 の分布 p124の例
129.
データ・使用例 •相関しそうなデータ •例:小学生の50m走のタイムと走り 幅跳びで飛んだ距離を並べたベクト ルの分布 •本書では9.3.1項から扱っていく。
130.
コーシー分布
131.
コーシー分布とは •時々とんでもない外れ値を出 すことがある裾が重い分布 (シミュレーション例:山口大学小杉 先生の「Cauchy分布について」参照 http://www.slideshare.net/KojiKosugi/cauc hy20150726) ⇒ この性質がモデリングに重宝
132.
6.14 コーシー分布 • 確率密度関数 •
Cauchy(y|μ, σ) = 1 πσ 1 1+ 𝑦−μ σ 2
133.
コーシー分布 • パラメータ:μ=実数、σ=正の実数 • 範囲:y=実数 •
平均:存在しない(正確には定義されない • 標準偏差:存在しない
134.
コーシー分布の例 μ=0, σ=1 ⇒
標準コーシー分布(自由度1のt分布)
135.
使用例 • 分散パラメタの事前分布として Cauchy (0,
2.5), Cauchy (0, 5)など • 外れ値を含むモデルとして ごくまれに出現する外れ値を許容するモデル y[n] ~ cauchy (a + b * X[n], σ) Cf. y[n] ~ normal(a + b * X[n], σ) 広島大学平川先生の資料より拝借 (Hirodai.stan発表非公開資料 7.9節へ
136.
Student の t
分布
137.
Studentのt分布とは •正規分布する母集団の平均と分散が 未知で標本サイズが小さい場合に平 均を推定する問題に利用される分布 •自由度によって裾の長さは大き く変化する。 ⇒ この性質がモデリングに重宝
138.
6.15 Studentのt分布 • 確率密度関数 •
Studen_t(y|ν, μ, σ) = Γ ν+1 2 Γ ν 2 𝜋𝜈𝜎 (1 + 1 ν 𝑦−μ σ )−(ν+1)/2
139.
Studentのt分布 • パラメータ:ν=正の実数(自由度 μ=実数、σ=正の実数 • 範囲:y=実数 •
平均:ν > 1の場合はμ、それ以外は存在 しない • 標準偏差:ν > 2の場合はσ√ν/(ν-2). 1 < ν ≦2の場合は∞、それ以外の場合は 存在しない。
140.
Studentのt分布の例 自由度 (ν) によって裾 が変化!!
141.
使用例 •コーシー分布ほどではないが、裾の 重い分布を使いたいときに自由度 2~8程度のt分布が重宝される。 •(コーシー同様)外れ値を含むモデル や、回帰係数の弱情報事前分布とし て使う場合も。7,10,12章参照
142.
二重指数分布 (ラプラス分布)
143.
ラプラス分布とは •正規分布と比べると裾が長め +μを中心とした鋭いピーク を持つ分布
144.
6.16 二重指数分布 (ラプラス 分布) •
確率密度関数 • DoubleExponential(y|μ, σ) = 1 2σ 𝑒𝑥𝑝 − 𝑦−μ σ • 指数分布を二つ貼り合わせた ような分布=二重指数分布 ← p75
145.
ラプラス分布 • パラメータ:μ=実数、σ=正の実数 • 範囲:y=実数 •
平均:μ • 標準偏差:√2σ
146.
ラプラス分布の例 ラプラス分布のデータ例:下図 鼻が尖ってる人
147.
使用例 •鋭いピーク → 回帰係数の事前分布に設定 → 変数選択に適用可能 具体例は7章にて。
148.
Rでの作り方: http://cse.naro.affrc.go.jp/ta kezawa/r-tips/r/60.html
149.
このパッケージも推奨 逆ガンマ分布 など本章にな い確率分布も rIGAMMA(n, mu, sigma) な どで簡単に求 まります。
150.
まだまだあるぞ!モデリング で用いる分布!! =ウィッシャート君: p, n, Σをパラメータと して持つ分布の分布を 表すモデル
(wiki)
151.
おわりに • 以上で6章で紹介された分布の解説を終 わります。 • 関数同士の関係、累積分布関数、算出過 程などの詳細は本家と同様に省いていま す。各自色々な資料を参照してください。 •
以下では個別学習に役立つと個人的に感 じているものをさらに2つ紹介します。
152.
1.確率分布の包括的理解に • Lawrence et
al. (2008: title=Univariate Distribution Relationships) • http://www.math.wm.edu/~leemis/chart/U DR/UDR.html 分布同士の関係 が見れたり、分 布の詳細を見れ たり出来るゾ!
153.
2.物足りないあなたへ • 世界最大級のオンライン学習プラット フォームUdemyでTamaki先生が「ベイズ 推定とグラフィカルモデル」というガチ 講義を開講されています。 • 分布の知識から、コンピュータ科学への 応用までお話ししてくれて興奮します。 本資料の一部 もこれを参考 にしてます!
154.
Enjoy R &
Stan ! And… Bayesian Modeling!!
155.
参考文献① • 当然アヒル本 • 各ページに記載されてるURLや資料 •
各分布のWiki • ややこしい離散分布に関するまとめ http://machine- learning.hatenablog.com/entry/2016/03/26/21110 6 • 多項分布とディリクレ分布のまとめと可視化 http://y- mattu.hatenablog.com/entry/2016/03/03/143451
156.
参考文献② • 松尾太加志・中村知靖(2002) 誰も教えてく れなかった因子分析-数式が
絶対に出てこな い因子分析入門- 北大路書房 • 村山先生によるANOVAに関する解説 http://koumurayama.com/koujapanese/anova.h tm • 様々な確率分布probability distributions - 数理 的思考 - 中川雅央 【知と情報の科学】 http://www.biwako.shiga- u.ac.jp/sensei/mnaka/ut/statdist.html
Download


















![一様分布
• パラメータ:実数a, b (a < b)
• 範囲:y=[a, b]の範囲の実数
• 平均:(a+b) / 2
• 標準偏差:(b-a) / √12](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-20-2048.jpg)







![ベルヌーイ分布
• パラメータ: θ [0,1] の範囲の実数
• 範囲:y=0か1のいずれかの整数値
• 平均: θ
• 標準偏差:√θ(1 − θ)](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-28-2048.jpg)


![例②:出席率
•パラメータθ= [0, 1] の範囲の実数
•出席率 (欠席=0、出席=1) のような
応答変数に対して、ロジスティック
関数と組み合わせて用いることが多
い (具体例など詳しくは5-3)。](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-31-2048.jpg)



![二項分布
• パラメータ:
N=正の整数、θ=[0,1] の範囲の実数
• 範囲:y=0,1, … N のいずれかの整数値
• 平均: Nθ (1いれるとベルヌーイ分布と一致
• 標準偏差:√Nθ(1 − θ)](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-35-2048.jpg)






![ベータ分布
• パラメータ: α、β=正の実数
• 範囲:θ=[0,1]の範囲の実数
• 平均:
α
α+β
• 標準偏差:
√αβ
α+β √α+β+1
• 範囲 0-1 の連続型分布=確率θ生成分布
→ 尤度がベルヌーイ・二項分布時に利用可能
+その他の [0, 1] の範囲の変数にも適用可能](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-42-2048.jpg)




![書籍内での例:故障率
• 見たいパラメータ=故障率
• M個中Y個故障×N品目
イメージ図 [N = 1:アンパン]
モデル式
θ ~ Beta(α、β) #故障率パラメータ
Y ~ Binomial (M, θ)
ジャムおじさん
のパン工場
3つのアンパンと
1つのこげパン](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-47-2048.jpg)







![カテゴリカル分布
• パラメータ: K=2以上の正の整数
θ=長さKのベクトル、各要素は[0,1]の
範囲の実数で合計すると1になる。
• 範囲:y=1,2, … Kのいずれかの整数
• 平均: I[y = k] の平均=θ 𝑘
• 分散共分散:I[y = k] の分散=θ 𝑘 (1 − θ 𝑘)
I[y = k] とI[y = k’] の共分散 (k ≠ k’)=−θ 𝑘θ 𝑘‘
I[y = k] は y = k となる場合に1を返し、それ以外は0を返す関数](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-55-2048.jpg)

![使用例:ソフトマックス回帰
• 店Aに3つの商品 (チョコ、飴、グミ) があると
する (K = 3)。
• その選択に関わりそうな説明変数=性別のみと
する。 すると以下のモデル式が提案可能。
• μ[n] = a + b*Sex[n] n = 個人
• θ[n] = softmax (μ[n]) = ベクトル
• Y[n] ~ Categorical(θ[n])
長さKのベクトル=3商品
の選択に関する線形結合
※softmax関数=expを用いて [-∞, ∞] をとりう
る値を正の値にしてから、合計が1になる (カテ
ゴリカル分布にあう) ように規格化するもの](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-57-2048.jpg)



![多項分布
• パラメータ: K=2以上の正の整数、
N=正の整数
θ=長さKのベクトル、各要素は [0,1] の
範囲の実数で合計すると1になる。
• 範囲:y=長さKのベクトル。各要素は0,1, …
Nのいずれかの整数で合計するとNになる
• 平均: yk の平均=Nθ 𝑘
• 分散共分散:yk の分散=Nθ 𝑘 (1 − θ 𝑘)
yk と yk’ の共分散 (k ≠ k’)=−Nθ 𝑘θ 𝑘‘](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-61-2048.jpg)



















































![こういう教材もあります。
※キモオタ以外のご視聴はお勧めしておりません。
• ニコニコ動画より「月読アイの理系なお話『神
様が愛した正規分布[前編]』」](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-113-2048.jpg)





















![使用例
• 分散パラメタの事前分布として
Cauchy (0, 2.5), Cauchy (0, 5)など
• 外れ値を含むモデルとして
ごくまれに出現する外れ値を許容するモデル
y[n] ~ cauchy (a + b * X[n], σ)
Cf. y[n] ~ normal(a + b * X[n], σ)
広島大学平川先生の資料より拝借
(Hirodai.stan発表非公開資料
7.9節へ](https://image.slidesharecdn.com/osaka-170228093442/75/Stan-R-Osaka-stan-6-135-2048.jpg)



































































![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)



























