先行研究
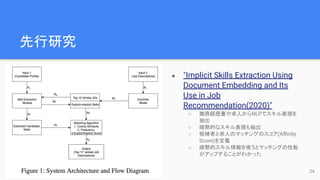
● "Implicit SkillsExtraction Using
Document Embedding and Its
Use in Job
Recommendation(2020)"
○ 職務経歴書や求人からNLPでスキル表現を
抽出
○ 暗黙的なスキル表現も抽出
○ 候補者と求人のマッチングのスコア(Affinity
Score)を定義
○ 暗黙的スキル情報を使うとマッチングの性能
がアップすることがわかった
24
25.
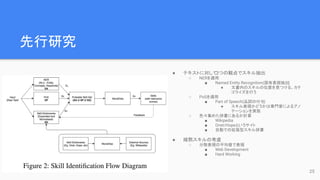
先行研究
● テキストに対して
3つの観点でスキル抽出
○ NERを適用
■Named Entity Recognition(固有表現抽出)
● 文書内のスキルの位置を見つける、カテ
ゴライズを行う
○ PoSを適用
■ Part of Speech(品詞の付与)
● スキル表現かどうかは専門家によるアノ
テーションを実施
○ 色々集めた辞書にあるか計算
■ Wikipedia
■ Onet/Hopeというサイト
■ 自動での拡張型スキル辞書
● 暗黙スキルの考慮
○ 分散表現の平均値で表現
■ Web Development
■ Hard Working
25
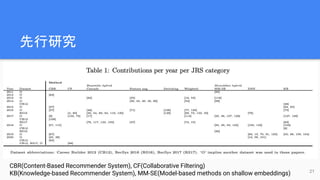
参考情報
● Corné deRuijt, Sandjai Bhulai(2021), "Job Recommender Systems: A
Review"
● Luiza Sayfullina, Eric Malmi, Yiping Liao, Alex Jung(2017), "Domain
Adaptation for Resume Classification Using Convolutional Neural
Networks"
● Saket Maheshwary, Hemant Misra(2018), "Matching Resumes to Jobs via
Deep Siamese Network"
● Akshay Gugnani, Hemant Misra(2020), "Implicit Skills Extraction Using
Document Embedding and Its Use in Job Recommendation"
35
36.
参考情報
● Yiou Lin,Hang Lei, Prince Clement Addo, Xiaoyu Li(2016), "Machine
Learned Resume-Job Matching Solution"
● Meng Zhao, Faizan Javed, Ferosh Jacob, Matt McNair(2015), "SKILL: A
System for Skill Identification and Normalization"
● Mesut Kaya and Toine Bogers(2021), “Effectiveness of job title based
embeddings on résumé to job ad recommendation"
● Yuya Matsumura(2022), "事業会社における推薦システム開発事例 /
recsys-in-wantedly-2022"
36







![先行研究
● "Job Recommender Systems: A Review(2021)"
○ Job Recommender System(JRS)研究のサーベイ論文 (2011〜2021)[計133本]
■ 近年は求人などの大量のテキストを用いたジョブレコメンデーションが多い。深層学習も
使われている。BERTもCNNも使われている。
■ ハイブリッドモデルが多い。
■ アルゴリズムの公平性 (年齢/性別での差別)に関心が持たれている。
● 特徴量として差別的なものがなくても学習してしまう可能性。
■ 求職者とリクルーターのインタラクティブなデータ (click/skip)の利活用が重要となってい
る。
● 研究者はRecsysなどのコンペのデータに依存している。
○ 企業がデータセットの提供をするのが限定的
○ JRSの発展のためには KaggleやRecsysのコンペが重要
20](https://image.slidesharecdn.com/ml15minutes2022-220924044139-383a0f3b/85/2022-20-320.jpg)
















![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み](https://cdn.slidesharecdn.com/ss_thumbnails/marunouchianalytics202107-210729113930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Music×Analytics]プロの音に近づくための研究と練習](https://cdn.slidesharecdn.com/ss_thumbnails/muanalt-210227062125-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSO] Machine Learning Seminar Vol.8 Chapter 9](https://cdn.slidesharecdn.com/ss_thumbnails/chapter9slides-200927083926-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第11回]データ分析ランチセッション - モダンな機械学習データパイプラインKedroを触ってみる](https://cdn.slidesharecdn.com/ss_thumbnails/lunchsession11-200325093135-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第6回]データ分析ランチセッション - Camphrでモダンな自然言語処理](https://cdn.slidesharecdn.com/ss_thumbnails/dsolunchsession6-200219123751-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2](https://cdn.slidesharecdn.com/ss_thumbnails/chapter12slides-200211153032-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第1回]データ分析ランチセッション ~ Qiita Advent Calendar2019から得た情報10選](https://cdn.slidesharecdn.com/ss_thumbnails/dsolunchsession1-200110120923-thumbnail.jpg?width=640&height=640&fit=bounds)



