Download as PDF, PPTX



![4
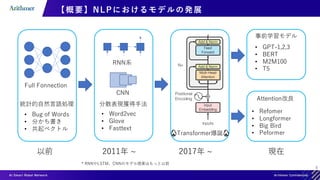
【概要】Transformerって何?
2017年の論文 Attention Is All You Need[1] で発表されたモデル
[1] Vaswani, Ashish et al. “Attention is All you Need.” ArXiv abs/1706.03762 (2017)
機械翻訳タスクにおいて既存SOTAよりも高いスコアを記録](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-4-320.jpg)
![5
【概要】Transformerの他分野への応用
[2] Dosovitskiy, A. et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” ArXiv abs/2010.11929 (2020)
[3] Gulati, Anmol et al. “Conformer: Convolution-augmented Transformer for Speech Recognition.” ArXiv abs/2005.08100 (2020)
[2] 画像分野での応用
[3] 音声分野での応用
NLPだけでなく幅広い分野へ応用](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-5-320.jpg)


![10
【構造解説】Positional Encoding( 1)
入力例:[“猫”, “は”, “可愛い”]
Embedding Layer
[“猫”, “は”, “可愛い”]
単語をベクトル化(単語列なので行列)
猫
は
可愛い
入力長
(3 dim.)
埋め込み次元
(512 dim.)
Positional Encoding 時系列情報の付与
猫
は
可愛い
時系列情報 時系列情報が付与された
単語特徴量
単語特徴量](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-10-320.jpg)

![12
【構造解説】Positional Encoding( 3)
[4] http://jalammar.github.io/illustrated-transformer より
Positional Encodingの可視化[4]
横軸:特徴量のインデックス(𝑖)
縦軸:単語の位置(pos)
1
-1
0
猫
は
可愛い
時系列情報
単語特徴量](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-12-320.jpg)

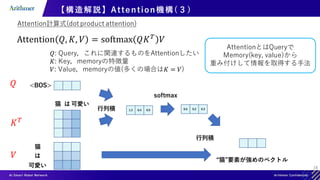

![20
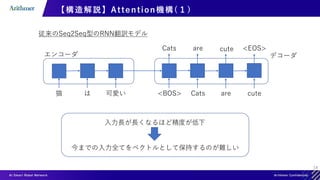
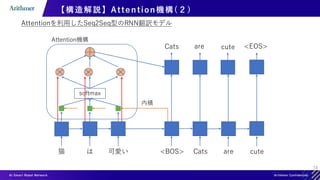
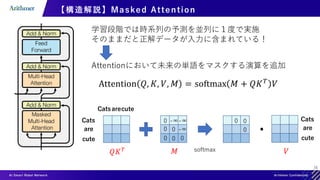
【構造解説】Self-Attention
Query, Key, Valueが全て同じAttention
猫 は 可愛い
𝑄
𝐾𝑇
𝑉
行列積
softmax
行列積
各単語の特徴量が他の単語を考慮されて再構成
猫
は
可愛い
猫
は
可愛い
[seq_len, emb_dim]
[emb_dim, seq_len]
[seq_len, seq_len]
[seq_len, emb_dim]
0.1 0.0 0.0
0.1 0.3 0.2
0.0 0.0 0.0
猫
は
可愛い
猫 は 可愛い
1.2 0.4 0.9
1.3 2.1 1.9
0.2 0.5 0.7](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-20-320.jpg)

![22
【構造解説】Multi-Head Attention( 1)
猫 は 可愛い
𝑄
𝐾𝑇
𝑉
行列積
softmax
行列積
各単語の特徴量が他の単語を考慮されて再構成
猫
は
可愛い
猫
は
可愛い
[seq_len, emb_dim]
[emb_dim, seq_len]
[seq_len, seq_len]
[seq_len, emb_dim]
0.1 0.0 0.0
0.1 0.3 0.2
0.0 0.0 0.0
猫
は
可愛い
猫 は 可愛い
1.2 0.4 0.9
1.3 2.1 1.9
0.2 0.5 0.7
並列に複数のAttentionを実施 • 愚直にn並列にすると計算量もn倍
• 結果も同じ](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-22-320.jpg)
![23
【構造解説】Multi-Head Attention( 2)
𝑄
𝑉
猫
は
可愛い
猫
は
可愛い
[seq_len, emb_dim]
𝐾
猫
は
可愛い
線形写像で行列の次元を減らしてから並列化(図の例では3並列)
[emb_dim, emb_dim/3] [seq_len, emb_dim/3]
行列積
𝑄1
′
転置
𝐾1
′
𝑉1
′
softmax
[seq_len, seq_len]
0.1 0.0 0.0
0.1 0.3 0.2
0.0 0.0 0.0
猫
は
可愛い
猫 は 可愛い
1.2 0.4 0.9
1.3 2.1 1.9
0.2 0.5 0.7
[emb_dim/3, seq_len]
[seq_len, seq_len]
[seq_len, emb_dim/3]
行列積
[seq_len, emb_dim/3]
𝑊
1
𝑄
𝑊1
𝐾
𝑊1
𝑧](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-23-320.jpg)
![24
【構造解説】Multi-Head Attention( 3)
𝑄
𝑉
猫
は
可愛い
猫
は
可愛い
[seq_len, emb_dim]
𝐾
猫
は
可愛い
線形写像で行列の次元を減らしてから並列化(図の例では3並列)
[emb_dim, emb_dim/3] [seq_len, emb_dim/3]
𝑄𝑖
′
𝐾𝑖
′
𝑉𝑖
′
𝑊
𝑖
𝑄
𝑊𝑖
𝐾
𝑊𝑖
𝑉
Attention
結合
[seq_len, emb_dim]
𝑊𝑜
[emb_dim, emb_dim]
出力
[seq_len, emb_dim]](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-24-320.jpg)


![27
【構造解説】Shortcut Connection
2015年に提案されたResidual Network(ResNet)[4]の要素
Shortcut Connection
[4] He, Kaiming et al. “Deep Residual Learning for Image Recognition.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016).
レイヤ部分は入力と出力の残差を予測すれば良く,
入力が理想的であれば値をほぼ変えずに出力できる
導入によりTransformerは層をより増やすことが可能](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-27-320.jpg)
![29
【構造解説】Position-wise Feed-Forward Networks
各単語ごとに隔離された全結合層
猫
は
可愛い
[seq_len, emb_dim] [emb_dim, emb_dim*4]
𝑊1
普通の全結合層
[seq_len * emb_dim]
[seq_len * emb_dim, emb_dim*4]
𝑊2
[emb_dim*4, emb_dim]
各単語への重みは共有(図で言うと横方向に同じ重みが並ぶ)](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-29-320.jpg)
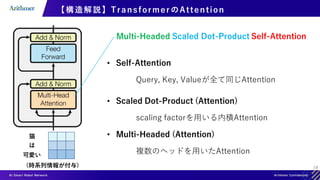
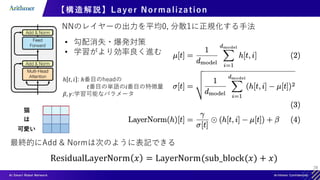
![30
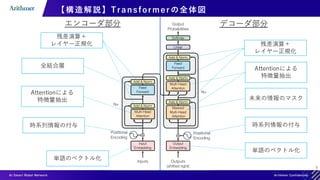
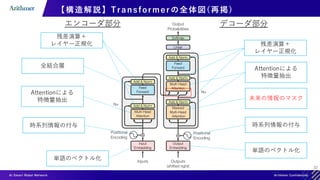
【構造解説】Transformer Module のまとめ
Multi-Head Attention
[seq_len, emb_dim]
[seq_len, emb_dim]
Add &Norm
ResidualLayerNorm 𝑥 = LayerNorm(sub_block(𝑥) + 𝑥)
Feed Forward
各サブレイヤーの出力次元は入力次元と同一,実際にはこのModuleを複数層重ねる](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-30-320.jpg)

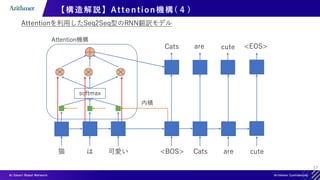
![34
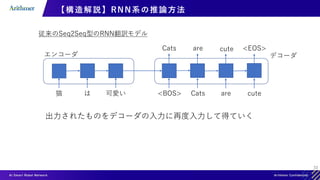
【構造解説】Transformer Decoder の推論(イメージ)
入力例:[“猫”, “は”, “可愛い”] [”<BOS>”,“Cats”, “are”]
1. Decoderの入力として[“<BOS>”,””,””]を入れる
2. Outputに”Cats”が出力される
3. Decoderの入力として[“<BOS>”,”Cats”,””]を入れる
4. Outputに”are”が出力される
RNN系の推論と類似(自己回帰)
“cute”](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-34-320.jpg)
![35
【構造解説】 Transformer Decoderの学習
[“猫”, “は”, “可愛い”] [”<BOS>”,“Cats”, “are”, ”cute”,”<EOS>”]
[“Cats”, ”are”, “cute”, “<EOS>”, “<PAD>”]
学習段階では時系列の予測を並列に1度で実施
Transformer Moduleの変換
”<BOS>”
“Cats”
“are”
”cute”
”<EOS>”]
Linear変換
[seq_len, emb_dim] [seq_len, emb_dim] [seq_len, vocab_size]
softmax
[seq_len, vocab_size]
確率最大なindexを抽出
[seq_len, 1]
“Cats”
“are”
”cute”
”<EOS>”
“<PAD>”](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-35-320.jpg)

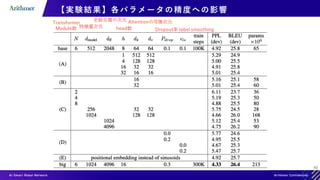
![38
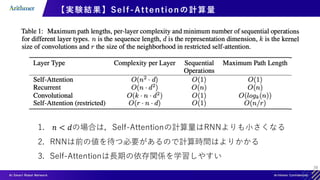
【実験結果】機械翻訳タスクの実験結果
[1] Vaswani, Ashish et al. “Attention is All you Need.” ArXiv abs/1706.03762 (2017)
既存の手法よりも高いスコア & 学習コストも](https://image.slidesharecdn.com/transformerintroduction-210527102807/85/Transformer-38-320.jpg)



本スライドは、弊社の梅本により弊社内の技術勉強会で使用されたものです。 近年注目を集めるアーキテクチャーである「Transformer」の解説スライドとなっております。 "Arithmer Seminar" is weekly held, where professionals from within and outside our company give lectures on their respective expertise. The slides are made by the lecturer from outside our company, and shared here with his/her permission. Arithmer株式会社は東京大学大学院数理科学研究科発の数学の会社です。私達は現代数学を応用して、様々な分野のソリューションに、新しい高度AIシステムを導入しています。AIをいかに上手に使って仕事を効率化するか、そして人々の役に立つ結果を生み出すのか、それを考えるのが私たちの仕事です。 Arithmer began at the University of Tokyo Graduate School of Mathematical Sciences. Today, our research of modern mathematics and AI systems has the capability of providing solutions when dealing with tough complex issues. At Arithmer we believe it is our job to realize the functions of AI through improving work efficiency and producing more useful results for society.





![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)




















