Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Classi.corp
PDF, PPTX
2,666 views
pymcとpystanでベイズ推定してみた話
mcmcをPythonで行うためのパッケージ比較についての話
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
Most read
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
Most read
19
/ 21
20
/ 21
Most read
21
/ 21
More Related Content
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
グラフニューラルネットワーク入門
by
ryosuke-kojima
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
不均衡データのクラス分類
by
Shintaro Fukushima
生成モデルの Deep Learning
by
Seiya Tokui
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
What's hot
PDF
数式からみるWord2Vec
by
Okamoto Laboratory, The University of Electro-Communications
PDF
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PDF
スパース推定法による統計モデリング(入門)
by
Hidetoshi Matsui
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PPTX
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PDF
数学カフェ 確率・統計・機械学習回 「速習 確率・統計」
by
Ken'ichi Matsui
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
PPTX
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
PDF
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PDF
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
数式からみるWord2Vec
by
Okamoto Laboratory, The University of Electro-Communications
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
スパース推定法による統計モデリング(入門)
by
Hidetoshi Matsui
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
変分ベイズ法の説明
by
Haruka Ozaki
数学カフェ 確率・統計・機械学習回 「速習 確率・統計」
by
Ken'ichi Matsui
これからの仮説検証・モデル評価
by
daiki hojo
Stan超初心者入門
by
Hiroshi Shimizu
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
バンディットアルゴリズム入門と実践
by
智之 村上
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
pymcとpystanでベイズ推定してみた話
1.
Copyright © 2019
Classi Corp. All Rights Reserved. 1 pymc3とpystanを比較してみた話 Classi株式会社 データAI部 小原
2.
Copyright © 2019
Classi Corp. All Rights Reserved. ● 自己紹介 ● pymc3/pystanを使おうと思ったきっかけ ● pymc3/pystanとは ○ 特徴 ○ 使い方 ○ 比較結果 ● まとめ アジェンダ
3.
Copyright © 2019
Classi Corp. All Rights Reserved.3 ◯ 高校への営業 ◯ 学習支援アプリ開発 ◯ 活用コンサルテーション ◯ プラットフォーム開発 ◯ ネイティブアプリ開発 ◯ 学校へのICT関連サポート 会社概要 ベネッセとソフトバンクのジョイントベンチャー
4.
Copyright © 2019
Classi Corp. All Rights Reserved. 「Classi」は教育現場を支援する クラウドサービス • 国内No.1、全国の高校の 50%超が導入 • 利用者数83万人超 • 先生、生徒、保護者が繋がる 学習支援プラットフォーム 4 事業について
5.
Copyright © 2019
Classi Corp. All Rights Reserved. ● 名前: 小原陽介(Twitter: @deerto_herajika) ● 所属: Classi株式会社 データAI部 ○ 学校教育現場をICT活用で支援する会社です ● 職業: DataScientist ○ 元データ整備職人 ○ 普段の業務 ■ 学習データに関する分析・モデル開発/社内BI環境の構築/ etc ○ 使用している言語・ツール: Python(Jupyter Lab)/GCP/Tableau ■ 一昨年R→Pythonにチェンジしました 自己紹介
6.
Copyright © 2019
Classi Corp. All Rights Reserved. pymc3・pystanを触ろうと思ったきっかけ ● 業務でベイズ推定を行う必要が発生した ● 既存のパッケージでサクッと事後分布を取得したい ○ pymc3とpystanが良さそう ■ 両方試してみよう ● pymc3とpystanとは: MCMC法(マルコフ連鎖モンテカルロ法)を行うパッケージ ○ MCMC法: マルコフ連鎖に則りサンプリングを行うことで、解析的に解くことので きない計算や分布を求める方法
7.
Copyright © 2019
Classi Corp. All Rights Reserved. pymc3の特徴 ● 環境 ○ python: >=3.5.4 ○ Theano:>=3.3 and < 3.6 ○ 3.6までは開発テスト済み ■ →3.5.4の環境で使用 ● 使い方 ○ with pm.model()でモデルを定義 し、確率分布を記述
8.
Copyright © 2019
Classi Corp. All Rights Reserved. pstanの特徴 ● 環境 ○ python: >=3.3 ● 特徴 ○ .stan(C++の確率的プログラミン グ言語)でモデルを定義 ○ 下記の3構造で構成される ■ data: 渡すデータ(dict) ■ parameters: 推定するパラ メータ ■ model: モデル(確率分布)
9.
Copyright © 2019
Classi Corp. All Rights Reserved. 使い方 ● 流れ: モデルを記述→サンプリングを「iteration × chain」回実行→結果を取得 ○ 推定結果のsummaryとplotが取得できる summary plot
10.
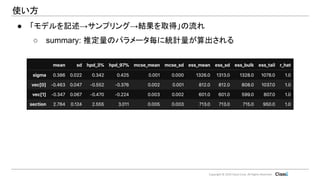
Copyright © 2019
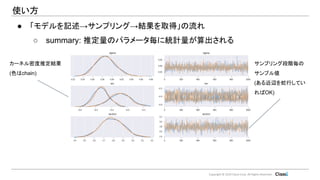
Classi Corp. All Rights Reserved. 使い方 ● 「モデルを記述→サンプリング→結果を取得」の流れ ○ summary: 推定量のパラメータ毎に統計量が算出される
11.
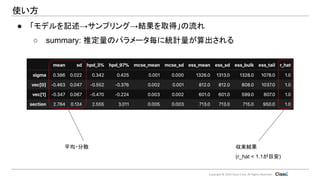
Copyright © 2019
Classi Corp. All Rights Reserved. 使い方 ● 「モデルを記述→サンプリング→結果を取得」の流れ ○ summary: 推定量のパラメータ毎に統計量が算出される 平均・分散 収束結果 (r_hat < 1.1が目安)
12.
Copyright © 2019
Classi Corp. All Rights Reserved. 使い方 ● 「モデルを記述→サンプリング→結果を取得」の流れ ○ summary: 推定量のパラメータ毎に統計量が算出される
13.
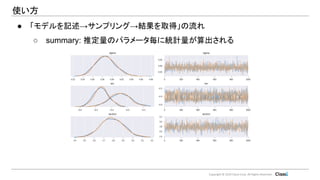
Copyright © 2019
Classi Corp. All Rights Reserved. 使い方 ● 「モデルを記述→サンプリング→結果を取得」の流れ ○ summary: 推定量のパラメータ毎に統計量が算出される カーネル密度推定結果 (色はchain) サンプリング段階毎の サンプル値 (ある近辺を蛇行してい ればOK)
14.
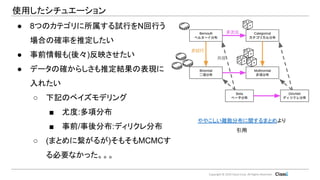
Copyright © 2019
Classi Corp. All Rights Reserved. 使用したシチュエーション ● 8つのカテゴリに所属する試行をN回行う 場合の確率を推定したい ● 事前情報も(後々)反映させたい ● データの確からしさも推定結果の表現に 入れたい ○ 下記のベイズモデリング ■ 尤度:多項分布 ■ 事前/事後分布:ディリクレ分布 ○ (まとめに繋がるが)そもそもMCMCす る必要なかった。。。 ややこしい離散分布に関するまとめより 引用
15.
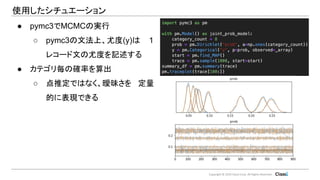
Copyright © 2019
Classi Corp. All Rights Reserved. 使用したシチュエーション ● pymc3でMCMCの実行 ○ pymc3の文法上、尤度(y)は 1 レコード文の尤度を記述する ● カテゴリ毎の確率を算出 ○ 点推定ではなく、曖昧さを 定量 的に表現できる
16.
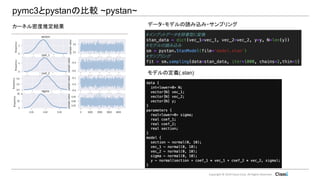
Copyright © 2019
Classi Corp. All Rights Reserved. pymc3とpystanの比較 ● (社内データを出せないの で)sklearn.datasets.load_wineに対し て重回帰モデルを使って比較 ● 相関の高い2つの変数を選択し、 下 記のモデルを定義 wine_dataのインポート 相関表 モデル式
17.
Copyright © 2019
Classi Corp. All Rights Reserved. pymc3とpystanの比較 ~pymc3~ カーネル密度推定結果 inputデータの定義 モデルの定義 説明変数の次元が2なのでshapeを入力
18.
Copyright © 2019
Classi Corp. All Rights Reserved. pymc3とpystanの比較 ~pystan~ データ・モデルの読み込み・サンプリング モデルの定義(.stan) カーネル密度推定結果
19.
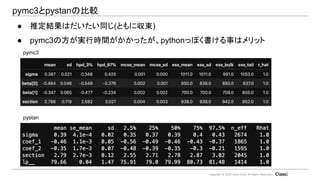
Copyright © 2019
Classi Corp. All Rights Reserved. pymc3とpystanの比較 ● 推定結果はだいたい同じ(ともに収束) ● pymc3の方が実行時間がかかったが、pythonっぽく書ける事はメリット pymc3 pystan
20.
Copyright © 2019
Classi Corp. All Rights Reserved. まとめ ● pymc3とpystan(あくまで個人の感想です) ○ 実行スピード: pymc3 < pystan ○ 書きやすさ: pymc3 > pystan ○ ドキュメントの充実度: pymc3 < pystan ○ モデルの表現度: pymc3 < pystan (?) ■ pymc3で使っているtheanoの開発が終了しているのも気になるところ ● 業務のベイズ推定はそもそも解析的に解けるパターンだった ○ (ディリクレ分布 × 多項分布 = ディリクレ分布) ○ まずは解析的に解けるかどうか考える癖をつける ■ 解析的に解けない / 階層モデルを作る際に初めて選択肢に入れる
21.
Copyright © 2019
Classi Corp. All Rights Reserved. We are Hiring! Classiでは一緒に働く仲間を募集しています ● Pythonエンジニア/データサイエンティスト/データエンジニア/… ● 詳細は採用ページにて https://hrmos.co/pages/classi
Download


































![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)




