Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takuto Kimura
4,817 views
PRML2.1 2.2
少し修正版
Technology
◦
Related topics:
Pattern Recognition
•
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 73 times
1
/ 31
2
/ 31
3
/ 31
Most read
4
/ 31
Most read
5
/ 31
6
/ 31
Most read
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半
by
Ohsawa Goodfellow
PDF
Prml 2.3
by
Yuuki Saitoh
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PPTX
PRML読み会第一章
by
Takushi Miki
PDF
PRML読書会#4資料+補足
by
Hiromasa Ohashi
PPTX
PRML 2.3 ガウス分布
by
KokiTakamiya
PDF
PRML輪読#4
by
matsuolab
PDF
PRML 2.4
by
kazunori sakai
PRML上巻勉強会 at 東京大学 資料 第1章前半
by
Ohsawa Goodfellow
Prml 2.3
by
Yuuki Saitoh
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PRML読み会第一章
by
Takushi Miki
PRML読書会#4資料+補足
by
Hiromasa Ohashi
PRML 2.3 ガウス分布
by
KokiTakamiya
PRML輪読#4
by
matsuolab
PRML 2.4
by
kazunori sakai
What's hot
PDF
PRML 2.3節 - ガウス分布
by
Yuki Soma
PDF
[PRML] パターン認識と機械学習(第2章:確率分布)
by
Ryosuke Sasaki
PPTX
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布
by
Nagayoshi Yamashita
PDF
PRML ベイズロジスティック回帰 4.5 4.5.2
by
tmtm otm
PDF
PRML輪読#9
by
matsuolab
PDF
Pattern Recognition and Machine Learning study session - パターン認識と機械学習 勉強会資料
by
Taro Masuda
PDF
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PDF
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PDF
PRML輪読#2
by
matsuolab
PDF
PRML輪読#3
by
matsuolab
PPTX
PRML2.4 指数型分布族
by
hiroki yamaoka
PDF
PRML輪読#7
by
matsuolab
PDF
PRML 1.6 情報理論
by
sleepy_yoshi
PDF
PRML読書会1スライド(公開用)
by
tetsuro ito
PDF
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PDF
PRML 2.3.2-2.3.4 ガウス分布
by
Akihiro Nitta
PDF
PRML 2.3.1-2.3.2
by
KunihiroTakeoka
PPTX
PRML6.4
by
hiroki yamaoka
PPTX
マルコフ連鎖モンテカルロ法
by
Masafumi Enomoto
PDF
研究室内PRML勉強会 11章2-4節
by
Koji Matsuda
PRML 2.3節 - ガウス分布
by
Yuki Soma
[PRML] パターン認識と機械学習(第2章:確率分布)
by
Ryosuke Sasaki
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布
by
Nagayoshi Yamashita
PRML ベイズロジスティック回帰 4.5 4.5.2
by
tmtm otm
PRML輪読#9
by
matsuolab
Pattern Recognition and Machine Learning study session - パターン認識と機械学習 勉強会資料
by
Taro Masuda
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PRML輪読#2
by
matsuolab
PRML輪読#3
by
matsuolab
PRML2.4 指数型分布族
by
hiroki yamaoka
PRML輪読#7
by
matsuolab
PRML 1.6 情報理論
by
sleepy_yoshi
PRML読書会1スライド(公開用)
by
tetsuro ito
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PRML 2.3.2-2.3.4 ガウス分布
by
Akihiro Nitta
PRML 2.3.1-2.3.2
by
KunihiroTakeoka
PRML6.4
by
hiroki yamaoka
マルコフ連鎖モンテカルロ法
by
Masafumi Enomoto
研究室内PRML勉強会 11章2-4節
by
Koji Matsuda
Viewers also liked
PDF
PRML勉強会第3回 2章前半 2013/11/28
by
kurotaki_weblab
PDF
Machine Learning Bootstrap
by
Takahiro Kubo
PDF
3分でわかる多項分布とディリクレ分布
by
Junya Saito
PDF
パターン認識 05 ロジスティック回帰
by
sleipnir002
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
今日から使える! みんなのクラスタリング超入門
by
toilet_lunch
PDF
ロジスティック回帰の考え方・使い方 - TokyoR #33
by
horihorio
PDF
Docker入門 - 基礎編 いまから始めるDocker管理
by
Masahito Zembutsu
PRML勉強会第3回 2章前半 2013/11/28
by
kurotaki_weblab
Machine Learning Bootstrap
by
Takahiro Kubo
3分でわかる多項分布とディリクレ分布
by
Junya Saito
パターン認識 05 ロジスティック回帰
by
sleipnir002
ノンパラベイズ入門の入門
by
Shuyo Nakatani
今日から使える! みんなのクラスタリング超入門
by
toilet_lunch
ロジスティック回帰の考え方・使い方 - TokyoR #33
by
horihorio
Docker入門 - 基礎編 いまから始めるDocker管理
by
Masahito Zembutsu
Similar to PRML2.1 2.2
PDF
PRML復々習レーン#3 前回までのあらすじ
by
sleepy_yoshi
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PPT
050 確率と確率分布
by
t2tarumi
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PDF
分布 isseing333
by
Issei Kurahashi
PDF
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
PDF
ベイズ統計入門
by
Miyoshi Yuya
PPTX
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
PDF
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PPTX
Bernoulli distribution and multinomial distribution (ベルヌーイ分布と多項分布)
by
Taro Tezuka
PDF
Chap12 4 appendix_suhara
by
sleepy_yoshi
PDF
Chap12 4 appendix_suhara
by
sleepy_yoshi
PPT
K040 確率分布とchi2分布
by
t2tarumi
PDF
Oshasta em
by
Naotaka Yamada
PDF
事前分布との出会い
by
Shigeru Kishikawa
PDF
Prml1.2.4
by
Tomoyuki Hioki
PDF
PRML ベイズロジスティック回帰
by
hagino 3000
PDF
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PDF
Prml 1.2,4 5,1.3|輪講資料1120
by
Hayato K
PPT
C:\D Drive\Prml\プレゼン\パターン認識と機械学習2 4章 D0703
by
Yoshinori Kabeya
PRML復々習レーン#3 前回までのあらすじ
by
sleepy_yoshi
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
050 確率と確率分布
by
t2tarumi
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
分布 isseing333
by
Issei Kurahashi
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
ベイズ統計入門
by
Miyoshi Yuya
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
Bernoulli distribution and multinomial distribution (ベルヌーイ分布と多項分布)
by
Taro Tezuka
Chap12 4 appendix_suhara
by
sleepy_yoshi
Chap12 4 appendix_suhara
by
sleepy_yoshi
K040 確率分布とchi2分布
by
t2tarumi
Oshasta em
by
Naotaka Yamada
事前分布との出会い
by
Shigeru Kishikawa
Prml1.2.4
by
Tomoyuki Hioki
PRML ベイズロジスティック回帰
by
hagino 3000
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
Prml 1.2,4 5,1.3|輪講資料1120
by
Hayato K
C:\D Drive\Prml\プレゼン\パターン認識と機械学習2 4章 D0703
by
Yoshinori Kabeya
PRML2.1 2.2
1.
PRML輪読会 2. 確率分布 2012.9.24
@americiumian
2.
発表概要
2.1 二値変数 2.2 多値変数 2.3 ガウス分布 2.4 指数型分布族 2.5 ノンパラメトリック法 2
3.
この章の目的
密度推定 観測値の有限集合𝑥1 , … , 𝑥 𝑁 が与えられた時,確率変数𝑥 の確率分布𝑝(𝑥)をモデル化すること このような確率分布は無限に存在しうる パラメトリック法 分布の形を仮定し,観測値に合わせてパラメータを調整する 手法 ノンパラメトリック法 分布の形を仮定せず,観測値によって分布を決める手法 3
4.
4
2.1 二値変数 • ベルヌーイ分布 • 二項分布 • ベータ分布
5.
ベルヌーイ分布 – 記号の定義
二値確率変数 x ∈ {0,1} ex. コインを投げて,表なら 𝑥 = 1 裏なら 𝑥 = 0 パラメータ μ 𝑥 = 1となる確率 0≦ 𝜇 ≦1 𝑝 𝑥 = 1 𝜇) = 𝜇, 𝑝 𝑥 = 0 𝜇 =1− 𝜇 計算例:𝜇 = 0.7の時 歪んだコインがある.このコインが表となる確率は0.7, 裏となる確率は0.3である.この時, 𝑝 𝑥 = 1 𝜇 = 0.7) = 0.7 𝑝 𝑥 = 0 𝜇 = 0.7 = 0.3 5
6.
ベルヌーイ分布
ベルヌーイ分布 Bern x 𝜇) = 𝜇 𝑥 (1 − 𝜇)1−𝑥 (2.2) 確率𝜇で表が出るコインを一回投げ,表(裏)が出る確率 特徴 𝐸[𝑥] = 𝜇 (2.3) 𝑣𝑎𝑟[𝑥] = 𝜇(1 − 𝜇) (2.4) 計算例:𝜇 = 0.7の時 歪んだコインがある.このコインが表となる確率は0.7, 裏となる確率は0.3である.この時, 𝐵𝑒𝑟𝑛 𝑥 = 1 𝜇 = 0.7) = 0.71 (1 − 0.7)0 = 0.7 𝐵𝑒𝑟𝑛 𝑥 = 0 𝜇 = 0.7 = 0.70 (1 − 0.7)1 = 0.3 6
7.
複数回観測した時の尤度関数
設定 D = 𝑥1 , … , 𝑥 𝑁 𝑥 𝑖 は,𝑝(𝑥 | 𝜇)から独立に得られたと仮定 尤度関数 𝑝 𝐷 𝜇) = 𝑛=1 𝑝 𝑥 𝑛 𝜇) = 𝑛=1 𝜇 𝑥 𝑛 (1 − 𝜇)1−𝑥 𝑛 (2.5) 𝑁 𝑁 𝜇が与えられた時,どのくらい,観測したデータが生起 しやすいかを表す 7
8.
パラメータ𝜇の値を最尤推定
対数尤度 𝑁 ln 𝑝(𝐷 | 𝜇) = ln 𝑝 𝑥 𝑛 𝜇) 𝑛=1 𝑁 = { 𝑥 𝑛 ln 𝜇 + 1 − 𝑥 𝑛 ln 1 − 𝜇 } (2.6) 𝑛=1 𝑁 = ln 𝜇 − ln 1 − 𝜇 𝑥 𝑛 + 𝑁 ln(1 − 𝜇) 𝑛=1 𝑁 この式は, 𝑛=1 𝑥 𝑛 のみに依存しているため,この式は, この分布の下,このデータに対する十分統計量の例 8
9.
パラメータ𝜇の値を最尤推定
最尤推定 ln 𝑝 𝐷 𝜇) を𝜇で偏微分して0とおいて解く 1 𝑁 𝜇 𝑀𝐿 = 𝑛=1 𝑥𝑛 (2.7) 𝑁 サンプル平均と呼ばれる 結果の違った見方 データ集合中で,𝑥 = 1になる回数を𝑚とすると, 𝑚 データ集合中での表の観測値の割合が 𝜇 𝑀𝐿 = (2.8) 𝑁 表が出る確率となる 9
10.
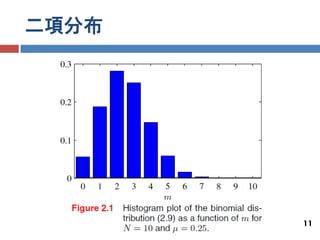
二項分布
記号の定義 𝑚 : 大きさ𝑁のデータ集合のうち,𝑥 = 1となる観測値mの数 二項分布 𝑁 𝐵𝑖𝑛(𝑚 | 𝑁, 𝜇) = 𝑚 𝜇 𝑚 (1 − 𝜇) 𝑁−𝑚 (2.9) 𝑁 = 𝑁! (2.10) 𝑚 𝑁−𝑚 !𝑚! 確率𝜇で表が出るコインを𝑁回投げた時, 表が出る回数𝑚の確率分布 特徴 𝐸[𝑚] = 𝑁𝜇 (2.11) 𝑣𝑎𝑟[𝑚] = 𝑁𝜇(1 − 𝜇) (2.12) 10
11.
二項分布
11
12.
ベータ分布
ベルヌーイ分布のパラメータ𝜇の最尤推定 3回表が出ると,以降ずっと表が出る? 𝑁 1 過学習の問題 𝜇 𝑀𝐿 = 𝑥𝑛 𝑁 𝑛=1 ベイズ主義的に扱う 事前分布𝑝(𝜇)を導入する必要性 𝑁 𝑥 𝑛 (1 − 𝑝 𝐷 𝜇) = 𝜇 𝜇)1−𝑥 𝑛 事後分布が事前分布と同様の 𝑛=1 形式となる事前分布を選びたい 共役性 𝜇と(1 − 𝜇) のべきに比例する事前分布を導入 12
13.
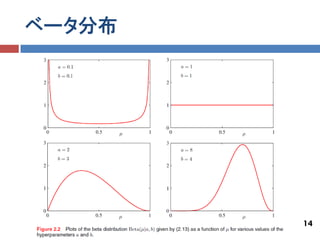
ベータ分布
Γ(a + b) 𝑎−1 𝐵𝑒𝑡𝑎 𝜇 𝑎, 𝑏) = 𝜇 (1 − 𝜇) 𝑏−1 (2.13) Γ a Γ(b) 特徴 𝑎 𝐸[𝜇] = (2.15) 𝑎+𝑏 𝑎𝑏 𝑣𝑎𝑟[𝜇] = (2.16) 𝑎+𝑏 2 (𝑎+𝑏+1) 𝑎, 𝑏は,𝜇の分布を決めるので,ハイパーパラメータと 呼ばれる 13
14.
ベータ分布
14
15.
事後分布を求める
事前分布 Γ(a + b) 𝑎−1 𝐵𝑒𝑡𝑎 𝜇 𝑎, 𝑏) = 𝜇 (1 − 𝜇) 𝑏−1 Γ a Γ(b) 尤度関数 𝑁 𝐵𝑖𝑛(𝑚 | 𝑁, 𝜇) = 𝜇 𝑚 (1 − 𝜇) 𝑙 (𝑙 = 𝑁 − 𝑚) 𝑚 事後分布 Γ(m + a + b + l) 𝑚+𝑎−1 𝑝 𝜇 𝑚, 𝑙, 𝑎, 𝑏) = (1 − 𝜇) 𝑙+𝑏−1 𝜇 Γ m + a Γ(b + l) (2.18) 𝑥 = 1の観測値が𝑚個,𝑥 = 0の観測値が𝑙個あった時, 事後分布を求めるには,𝑎を𝑚, 𝑏を𝑙だけ増やせばよい 𝑎, 𝑏はそれぞれ,𝑥 = 1, 𝑥 = 0の有効観測数と解釈できる 15
16.
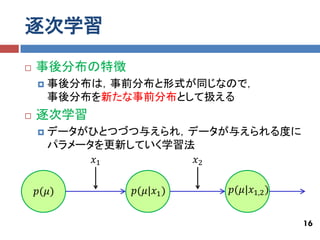
逐次学習
事後分布の特徴 事後分布は,事前分布と形式が同じなので, 事後分布を新たな事前分布として扱える 逐次学習 データがひとつづつ与えられ,データが与えられる度に パラメータを更新していく学習法 𝑥1 𝑥2 𝑝(𝜇) 𝑝(𝜇|𝑥1 ) 𝑝(𝜇|𝑥1,2 ) 16
17.
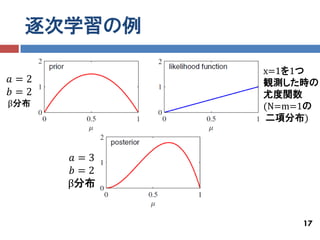
逐次学習の例
x=1を1つ 𝑎=2 観測した時の 𝑏=2 尤度関数 β分布 (N=m=1の 二項分布) 𝑎=3 𝑏=2 β分布 17
18.
逐次学習の長所・短所
長所 実時間での学習に利用できる 毎観測値ごとに事後確率を算出するので,全てのデータが なくともよい 大規模データ集合に有用 観測値の処理が終わった後,そのデータはもう捨ててよい 短所 学習の早さと,正しい解への収束性のトレードオフ 18
19.
𝑥の予測分布
これまでの議論 𝑝(𝜇 | 𝐷)の推定 観測データ集合𝐷から,パラメータ𝜇の確率分布を推定 ここからの議論 𝑝(𝑥 = 1 | 𝐷)の推定 観測データ集合𝐷から,𝑥 = 1となる確率を推定 19
20.
𝑥の予測分布
1 𝑝(𝑥 = 1 | 𝐷) = 𝑝 𝑥=1 𝜇)𝑝 𝜇 𝐷) 𝑑𝜇 0 1 = 𝜇𝑝 𝜇 𝐷) 𝑑𝜇 0 = 𝑬 𝜇 𝐷] (2.19) 𝑚+ 𝑎 = (2.20) 𝑚+ 𝑎+ 𝑙+ 𝑏 観測値のうち,𝑥 = 1に相当するものの割合 𝑚, 𝑙がとても大きい時,最尤推定の結果と一致する このような特性は,多くの例で見られる 有限のデータ集合では, 事前平均 ≦ 事後平均 ≦ 𝜇の最尤推定量 →演習2.7 20
21.
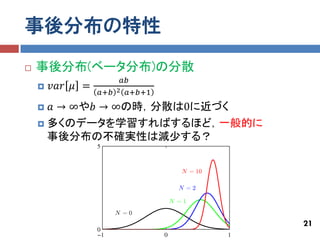
事後分布の特性
事後分布(ベータ分布)の分散 𝑎𝑏 𝑣𝑎𝑟 𝜇 = 𝑎+𝑏 2 𝑎+𝑏+1 𝑎 → ∞や𝑏 → ∞の時,分散は0に近づく 多くのデータを学習すればするほど,一般的に 事後分布の不確実性は減少する? 21
22.
平均・分散の不確実性
事前平均と事後平均 𝐸 𝜽 𝜽 = 𝐸 𝐷 [𝐸 𝜽 𝜽 | 𝐷 ] (2.21) 𝜽の事後平均を,データを生成する分布上で平均すると, 𝜽の事前平均に等しい 事前分散と事後分散 𝑣𝑎𝑟 𝜃 𝜃 = 𝐸 𝐷 [𝑣𝑎𝑟 𝜃 𝜃 𝐷]] + 𝑣𝑎𝑟 𝐷 [𝐸 𝐷 𝜃 𝐷]] (2.24) 事前分散 事後分散の平均 事後平均の分散 の平均 平均的には 事前分散 > 事後分散 成り立たないデータセットもある 22
23.
23
2.2 多値変数 • 多項分布 • ディリクレ分布
24.
例えば
サイコロを投げる 6通りの状態がありうる 1-of-K 符号化法 K個の状態を取りうる離散変数を扱う際に用いられる 要素の一つ𝑥 𝑘 のみが1で他が0 𝐾 𝑘=1 𝑥 𝑘 = 1を満たす ex. サイコロの目を観測値𝑥として,3が出た時 𝑥 = (0,0,1,0,0,0) 𝑇 24
25.
歪んだサイコロ
記号の定義 𝜇 𝑘 ∶ 𝑥 𝑘 = 1となる確率 正確なサイコロの場合 1 1 1 1 1 1 𝝁=( , , , , , ) 6 6 6 6 6 6 シゴロ賽の場合 1 1 1 𝝁 = (0,0,0, , , ) 3 3 3 ピンゾロ賽の場合 𝝁 = (1,0,0,0,0,0) 25
26.
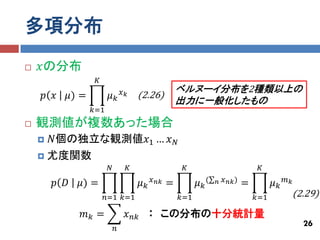
多項分布
𝑥の分布 𝐾 𝑥𝑘 ベルヌーイ分布を2種類以上の 𝑝 𝑥 𝜇) = 𝜇𝑘 (2.26) 出力に一般化したもの 𝑘=1 観測値が複数あった場合 𝑁個の独立な観測値𝑥1 … 𝑥 𝑁 尤度関数 𝑁 𝐾 𝐾 𝐾 𝑝 𝐷 𝜇) = 𝜇𝑘 𝑥 𝑛𝑘 = 𝜇 𝑘( 𝑛 𝑥 𝑛𝑘 ) = 𝜇𝑘 𝑚𝑘 𝑛=1 𝑘=1 𝑘=1 𝑘=1 (2.29) 𝑚𝑘 = 𝑥 𝑛𝑘 : この分布の十分統計量 26 𝑛
27.
𝝁の最尤推定
制約付き対数尤度最大化 ラグランジュの未定乗数法を用いる 𝐾 𝐾 𝜇 𝑘 = 1 に代入して, 𝑓= 𝑚 𝑘 ln 𝜇 𝑘 + 𝜆 𝜇𝑘−1 𝑘 𝑘=1 𝑘=1 𝑚𝑘 𝜕𝑓 𝑚𝑘 − =1 = + 𝜆 𝜆 𝜕𝜇 𝑘 𝜇𝑘 𝑘 𝜕𝑓 − 𝑚𝑘 = 𝜆 = 0 より, 𝜕𝜇 𝑘 𝑘 𝑚𝑘 𝜆 = −𝑁 𝜇𝑘 =− 𝑚𝑘 𝜆 𝜇 𝑘 𝑀𝐿 = 𝑁 27
28.
多項分布
𝐾 𝑁 𝑚𝑘 𝑀𝑢𝑙𝑡 𝑚1 , … 𝑚 𝐾 𝝁, 𝑁) = 𝜇𝑘 (2.34) 𝑚1 𝑚2 … 𝑚 𝐾 𝑘=1 𝑁 𝑁! ただし, = 𝑚1 𝑚2 … 𝑚 𝐾 𝑚1 ! 𝑚2 ! … 𝑚 𝐾 ! 𝐾 𝑚𝑘 = 𝑁 𝑘=1 パラメータ𝜇と観測値の総数𝑁が与えられた条件の下, 𝑚1 … 𝑚 𝐾 の同時確率 28
29.
ディリクレ分布
多項分布の𝜇 𝑘 についての事前分布 共役分布の形は以下の通り 𝐾 𝛼 𝑘 −1 (2.37) 𝑝 𝝁 𝜶) ∝ 𝜇𝑘 𝑘=1 ただし,0 ≦ 𝜇 𝑘 ≦ 1, 𝑘 𝜇 𝑘 = 1 ハイパーパラメータ 𝜶 = (𝛼1 , … , 𝛼 𝐾 ) 𝑇 ディリクレ分布 𝐾 Γ(𝛼0 ) 𝐷𝑖𝑟 𝝁 𝜶) = 𝜇𝑘 𝛼 𝑘 −1 (2.38) Γ 𝛼1 … Γ(𝛼 𝐾 ) 𝑘=1 ただし,𝛼0 = 𝑘 𝛼𝑘 29
30.
共役性の確認
事前分布 𝐾 Γ(𝛼0 ) 𝛼 𝑘 −1 𝑝 𝝁 𝜶) = 𝜇𝑘 (2.38) Γ 𝛼1 … Γ(𝛼 𝐾 ) 𝑘=1 尤度関数 𝐾 𝑁 𝑝 𝐷 𝝁) = 𝑚1 𝑚2 … 𝑚 𝐾 𝜇𝑘 𝑚𝑘 (2.34) 𝑘=1 事後分布 𝑝 𝝁 𝐷, 𝜶) = 𝐷𝑖𝑟 𝝁 𝜶 + 𝒎) 𝐾 Γ(𝛼0 + 𝑁) = 𝜇𝑘 𝛼 𝑘 +𝑚 𝑘 −1 (2.41) Γ 𝛼1 + 𝑚1 … Γ(𝛼 𝐾 + 𝑚 𝐾 ) 30 𝑘=1
31.
参考サイト
朱鷺の杜Wiki http://ibisforest.org/index.php?FrontPage Bishopさんのサイト http://research.microsoft.com/en- us/um/people/cmbishop/PRML/ prml_note@wiki http://www43.atwiki.jp/prml_note/pages/1.html 十分統計量について http://www012.upp.so- net.ne.jp/doi/math/anova/sufficientstatistic.pdf 31
Download






![ベルヌーイ分布
ベルヌーイ分布
Bern x 𝜇) = 𝜇 𝑥 (1 − 𝜇)1−𝑥 (2.2)
確率𝜇で表が出るコインを一回投げ,表(裏)が出る確率
特徴
𝐸[𝑥] = 𝜇 (2.3)
𝑣𝑎𝑟[𝑥] = 𝜇(1 − 𝜇) (2.4)
計算例:𝜇 = 0.7の時
歪んだコインがある.このコインが表となる確率は0.7,
裏となる確率は0.3である.この時,
𝐵𝑒𝑟𝑛 𝑥 = 1 𝜇 = 0.7) = 0.71 (1 − 0.7)0 = 0.7
𝐵𝑒𝑟𝑛 𝑥 = 0 𝜇 = 0.7 = 0.70 (1 − 0.7)1 = 0.3 6](https://image.slidesharecdn.com/prml2-1-2-2-120924025246-phpapp02/85/PRML2-1-2-2-6-320.jpg)



![二項分布
記号の定義
𝑚 : 大きさ𝑁のデータ集合のうち,𝑥 = 1となる観測値mの数
二項分布
𝑁
𝐵𝑖𝑛(𝑚 | 𝑁, 𝜇) = 𝑚
𝜇 𝑚 (1 − 𝜇) 𝑁−𝑚 (2.9)
𝑁
=
𝑁! (2.10)
𝑚 𝑁−𝑚 !𝑚!
確率𝜇で表が出るコインを𝑁回投げた時,
表が出る回数𝑚の確率分布
特徴
𝐸[𝑚] = 𝑁𝜇 (2.11)
𝑣𝑎𝑟[𝑚] = 𝑁𝜇(1 − 𝜇) (2.12)
10](https://image.slidesharecdn.com/prml2-1-2-2-120924025246-phpapp02/85/PRML2-1-2-2-10-320.jpg)

![ベータ分布
Γ(a + b) 𝑎−1
𝐵𝑒𝑡𝑎 𝜇 𝑎, 𝑏) = 𝜇 (1 − 𝜇) 𝑏−1 (2.13)
Γ a Γ(b)
特徴
𝑎
𝐸[𝜇] = (2.15)
𝑎+𝑏
𝑎𝑏
𝑣𝑎𝑟[𝜇] = (2.16)
𝑎+𝑏 2 (𝑎+𝑏+1)
𝑎, 𝑏は,𝜇の分布を決めるので,ハイパーパラメータと
呼ばれる
13](https://image.slidesharecdn.com/prml2-1-2-2-120924025246-phpapp02/85/PRML2-1-2-2-13-320.jpg)



![𝑥の予測分布
1
𝑝(𝑥 = 1 | 𝐷) = 𝑝 𝑥=1 𝜇)𝑝 𝜇 𝐷) 𝑑𝜇
0
1
= 𝜇𝑝 𝜇 𝐷) 𝑑𝜇
0
= 𝑬 𝜇
𝐷] (2.19)
𝑚+ 𝑎
= (2.20)
𝑚+ 𝑎+ 𝑙+ 𝑏
観測値のうち,𝑥 = 1に相当するものの割合
𝑚, 𝑙がとても大きい時,最尤推定の結果と一致する
このような特性は,多くの例で見られる
有限のデータ集合では,
事前平均 ≦ 事後平均 ≦ 𝜇の最尤推定量 →演習2.7 20](https://image.slidesharecdn.com/prml2-1-2-2-120924025246-phpapp02/85/PRML2-1-2-2-20-320.jpg)
![平均・分散の不確実性
事前平均と事後平均
𝐸 𝜽 𝜽 = 𝐸 𝐷 [𝐸 𝜽 𝜽 | 𝐷 ] (2.21)
𝜽の事後平均を,データを生成する分布上で平均すると,
𝜽の事前平均に等しい
事前分散と事後分散
𝑣𝑎𝑟 𝜃 𝜃 = 𝐸 𝐷 [𝑣𝑎𝑟 𝜃 𝜃 𝐷]] + 𝑣𝑎𝑟 𝐷 [𝐸 𝐷 𝜃 𝐷]] (2.24)
事前分散 事後分散の平均 事後平均の分散
の平均
平均的には 事前分散 > 事後分散
成り立たないデータセットもある
22](https://image.slidesharecdn.com/prml2-1-2-2-120924025246-phpapp02/85/PRML2-1-2-2-22-320.jpg)
















![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)










