Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
WS
Uploaded by
Wataru Shito
158 views
演習II.第1章 ベイズ推論の考え方 Part 2.講義ノート
西南学院大学経済学部 演習2 講義ノート(2021/8/22修正版) 講義ページ: http://courses.wshito.com/semi2/2019-bayes-AI
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 10
2
/ 10
3
/ 10
4
/ 10
5
/ 10
6
/ 10
7
/ 10
8
/ 10
9
/ 10
10
/ 10
More Related Content
PDF
演習II.第1章 ベイズ推論の考え方 Part 1.講義ノート
by
Wataru Shito
PDF
演習II.第1章 ベイズ推論の考え方 Part 2.スライド
by
Wataru Shito
PDF
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
PDF
2019年 演習II.第1章 ベイズ推論の考え方 Part 1
by
Wataru Shito
PDF
経済数学II 「第9章 最適化(Optimization)」
by
Wataru Shito
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
PDF
「全ての確率はコイン投げに通ず」 Japan.R 発表資料
by
Ken'ichi Matsui
PDF
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
演習II.第1章 ベイズ推論の考え方 Part 1.講義ノート
by
Wataru Shito
演習II.第1章 ベイズ推論の考え方 Part 2.スライド
by
Wataru Shito
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
2019年 演習II.第1章 ベイズ推論の考え方 Part 1
by
Wataru Shito
経済数学II 「第9章 最適化(Optimization)」
by
Wataru Shito
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
「全ての確率はコイン投げに通ず」 Japan.R 発表資料
by
Ken'ichi Matsui
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
What's hot
PPTX
基礎からのベイズ統計学 3章(3.1~3.3)
by
TeranishiKeisuke
PPTX
Rによるベイジアンネットワーク入門
by
Okamoto Laboratory, The University of Electro-Communications
PDF
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
PDF
MLaPP 5章 「ベイズ統計学」
by
moterech
PDF
基礎からのベイズ統計学 輪読会資料 第1章 確率に関するベイズの定理
by
Ken'ichi Matsui
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
ベイズ統計入門
by
Miyoshi Yuya
PPTX
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
PDF
「深層学習」第6章 畳込みニューラルネット
by
Ken'ichi Matsui
PDF
いいからベイズ推定してみる
by
Makoto Hirakawa
PDF
クラシックな機械学習の入門 2.ベイズ統計に基づく推論
by
Hiroshi Nakagawa
PDF
Rm20150520 6key
by
youwatari
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PDF
20170422 数学カフェ Part2
by
Kenta Oono
基礎からのベイズ統計学 3章(3.1~3.3)
by
TeranishiKeisuke
Rによるベイジアンネットワーク入門
by
Okamoto Laboratory, The University of Electro-Communications
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
MLaPP 5章 「ベイズ統計学」
by
moterech
基礎からのベイズ統計学 輪読会資料 第1章 確率に関するベイズの定理
by
Ken'ichi Matsui
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
ベイズ統計入門
by
Miyoshi Yuya
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
「深層学習」第6章 畳込みニューラルネット
by
Ken'ichi Matsui
いいからベイズ推定してみる
by
Makoto Hirakawa
クラシックな機械学習の入門 2.ベイズ統計に基づく推論
by
Hiroshi Nakagawa
Rm20150520 6key
by
youwatari
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
20170422 数学カフェ Part1
by
Kenta Oono
20170422 数学カフェ Part2
by
Kenta Oono
Similar to 演習II.第1章 ベイズ推論の考え方 Part 2.講義ノート
PPTX
【DBDA勉強会2013】Doing Bayesian Data Analysis Chapter 8: Inferring Two Binomial P...
by
Junki Marui
PDF
第2回ぞくパタ
by
Akifumi Eguchi
PDF
第4回MachineLearningのための数学塾資料(浅川)
by
Shin Asakawa
PPTX
PRML 1.2.3 ベイズ確率
by
KokiTakamiya
PDF
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PDF
PRML輪読#2
by
matsuolab
PDF
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PDF
PRML2.1 2.2
by
Takuto Kimura
PDF
ベイズ入門
by
Zansa
PPT
ma92007id395
by
matsushimalab
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
Pattern Recognition and Machine Learning study session - パターン認識と機械学習 勉強会資料
by
Taro Masuda
PDF
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
PPTX
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
PRML輪読#10
by
matsuolab
PDF
第一回ぞくパタ
by
Akifumi Eguchi
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
201803NC
by
Naoki Hayashi
PPTX
【DBDA勉強会2013】Doing Bayesian Data Analysis Chapter 9: Bernoulli Likelihood wit...
by
Koji Yoshida
【DBDA勉強会2013】Doing Bayesian Data Analysis Chapter 8: Inferring Two Binomial P...
by
Junki Marui
第2回ぞくパタ
by
Akifumi Eguchi
第4回MachineLearningのための数学塾資料(浅川)
by
Shin Asakawa
PRML 1.2.3 ベイズ確率
by
KokiTakamiya
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PRML輪読#2
by
matsuolab
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PRML2.1 2.2
by
Takuto Kimura
ベイズ入門
by
Zansa
ma92007id395
by
matsushimalab
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
Pattern Recognition and Machine Learning study session - パターン認識と機械学習 勉強会資料
by
Taro Masuda
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PRML輪読#10
by
matsuolab
第一回ぞくパタ
by
Akifumi Eguchi
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
201803NC
by
Naoki Hayashi
【DBDA勉強会2013】Doing Bayesian Data Analysis Chapter 9: Bernoulli Likelihood wit...
by
Koji Yoshida
More from Wataru Shito
PDF
第3章 遅延学習---最近傍法を使った分類
by
Wataru Shito
PDF
統計的推定の基礎 2 -- 分散の推定
by
Wataru Shito
PDF
統計的推定の基礎 1 -- 期待値の推定
by
Wataru Shito
PDF
演習II.第1章 ベイズ推論の考え方 Part 3.講義ノート
by
Wataru Shito
PDF
演習II.第1章 ベイズ推論の考え方 Part 3.スライド
by
Wataru Shito
PDF
マクロ経済学I 「第8章 総需要・総供給分析(AD-AS分析)」
by
Wataru Shito
PDF
マクロ経済学I 「第10章 総需要 II.IS-LM分析とAD曲線」
by
Wataru Shito
PDF
第9回 大規模データを用いたデータフレーム操作実習(3)
by
Wataru Shito
PDF
第8回 大規模データを用いたデータフレーム操作実習(2)
by
Wataru Shito
PDF
経済数学II 「第12章 制約つき最適化」
by
Wataru Shito
PDF
マクロ経済学I 「第9章 総需要 I」
by
Wataru Shito
PDF
経済数学II 「第11章 選択変数が2個以上の場合の最適化」
by
Wataru Shito
PDF
マクロ経済学I 「第6章 開放経済の長期分析」
by
Wataru Shito
PDF
経済数学II 「第8章 一般関数型モデルの比較静学」
by
Wataru Shito
PDF
マクロ経済学I 「第4,5章 貨幣とインフレーション」
by
Wataru Shito
PDF
マクロ経済学I 「第3章 長期閉鎖経済モデル」
by
Wataru Shito
PDF
経済数学II 「第7章 微分法とその比較静学への応用」
by
Wataru Shito
PDF
経済数学II 「第6章 比較静学と導関数の概念」
by
Wataru Shito
PDF
マクロ経済学I 「マクロ経済分析の基礎知識」
by
Wataru Shito
PDF
経済数学II 「第5章 線型モデルと行列代数 II」
by
Wataru Shito
第3章 遅延学習---最近傍法を使った分類
by
Wataru Shito
統計的推定の基礎 2 -- 分散の推定
by
Wataru Shito
統計的推定の基礎 1 -- 期待値の推定
by
Wataru Shito
演習II.第1章 ベイズ推論の考え方 Part 3.講義ノート
by
Wataru Shito
演習II.第1章 ベイズ推論の考え方 Part 3.スライド
by
Wataru Shito
マクロ経済学I 「第8章 総需要・総供給分析(AD-AS分析)」
by
Wataru Shito
マクロ経済学I 「第10章 総需要 II.IS-LM分析とAD曲線」
by
Wataru Shito
第9回 大規模データを用いたデータフレーム操作実習(3)
by
Wataru Shito
第8回 大規模データを用いたデータフレーム操作実習(2)
by
Wataru Shito
経済数学II 「第12章 制約つき最適化」
by
Wataru Shito
マクロ経済学I 「第9章 総需要 I」
by
Wataru Shito
経済数学II 「第11章 選択変数が2個以上の場合の最適化」
by
Wataru Shito
マクロ経済学I 「第6章 開放経済の長期分析」
by
Wataru Shito
経済数学II 「第8章 一般関数型モデルの比較静学」
by
Wataru Shito
マクロ経済学I 「第4,5章 貨幣とインフレーション」
by
Wataru Shito
マクロ経済学I 「第3章 長期閉鎖経済モデル」
by
Wataru Shito
経済数学II 「第7章 微分法とその比較静学への応用」
by
Wataru Shito
経済数学II 「第6章 比較静学と導関数の概念」
by
Wataru Shito
マクロ経済学I 「マクロ経済分析の基礎知識」
by
Wataru Shito
経済数学II 「第5章 線型モデルと行列代数 II」
by
Wataru Shito
演習II.第1章 ベイズ推論の考え方 Part 2.講義ノート
1.
第1章 ベイズ推論の考え方 Part
2 市東 亘 2021 年 8 月 22 日 1 概観 目 次 1 概観 1 2 ベイズ推定の基礎 1 2.1 連続型確率変数のベイズの定理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 2.2 コイン投げ問題 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2.3 コイン投げ問題の Python による視覚化 . . . . . . . . . . . . . . . . . . . . . . . . 7 2.4 コイン投げ問題の R による視覚化 . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 3 まとめ: ベイズ推定の手順 10 2 ベイズ推定の基礎 前回はベイズの定理を応用して,データが不十分な状態から信念(事前確率)を用いて,徐々に 入手可能となるデータに応じて事後確率を求める方法を学んだ. ⇒ 単なる条件確率の計算. ここからはベイズ推定について学ぶ. • 計量経済学を始めとする統計的なデータ分析では,データが従う を構築する.さらに, – その統計モデルが従う分布関数のパラメータを推定する. – 仮説(理論)が正しいか仮説検定を行う. • ベイズ推定では,統計モデルのパラメータ推定と仮説の検証に を 応用する. 1
2.
2.1 連続型確率変数のベイズの定理 ノーテーション定義 • データ
D の実現値を x,仮説 H の実現値を θ で表す. • f(x, θ): 連続型確率変数 D と H がそれぞれ D = x,H = θ の値をとる時の同時確率密度 関数. • f(x|θ): H = θ が与えられた時の D = x の条件付き確率密度関数. • f(θ|x): D = x が与えられた時の H = θ の条件付き確率密度関数. • f(x),f(θ): D と H の周辺確率密度関数. • 関数名が全て f だが関数形は異なる.関数形は与えられた確率変数で区別する. 連続型確率変数のベイズの定理 条件付き分布の定義より, f(θ|x) = f(θ, x) f(x) = f(x, θ) f(x) = f(x|θ)f(θ) f(x) 2.2 コイン投げ問題 目的: コインを投げた時,どちらの面が出るか予測するためにコイン投げをモデル化したい. • 理屈ではコインの表と裏が出る確率は 1/2. ⇒ 頻度主義 • 統計的推定: データを観測してコインの表と裏が出る確率を推定する. ⇒ データが従う統計モデルを構築する. – 頻度主義: 統計モデルが従う確率分布の は未知の定数で, が確率変数と考える1 . – ベイズ主義: は定数で, 統計モデルが従う確率分布の が確率変数と考える. • コイン投げで表が出る事象を x = 1,裏が出る事象を x = 0 で表す. • コインの表が出る確率を θ,裏が出る確率を 1 − θ とおくと,それぞれの事象が生じる確率 は以下で表される. Pr(x = 1 | θ) = Pr(x = 0 | θ) = 1頻度主義では,データは神のみぞ知る母集団から抽出された標本と考える.母集団データが従う分布のパラメータも 神のみぞ知る定数である.そして,母集団からランダム抽出された標本データを用いて,神のみぞ知るパラメータ定数を 推定する. 西南学院大学 演習 II(2019 年) 2 担当 市東 亘
3.
• 上式を 1
つにまとめると,いずれの事象が生じる確率も表せる. Pr(x|θ) = θx (1 − θ)1−x • 独立事象であるコイン投げを n 回実行した時,{xi}, i = 1, . . . , n の同時確率は以下で表さ れる. Pr({xi}|θ) = n ∏ i Pr(xi|θ) = ∏ i θxi (1 − θ)1−xi = θ ∑ xi (1 − θ) ∑ (1−xi) = θ#表 (1 − θ)#裏 • 統計モデル: コインを n 回投げた時,表が出る回数は にしたがう. • θ の値は? – θ = 0.5 のはずだ!⇐ 1 つの仮説に過ぎない. – このコインは表があまり出ないからイカサマコインで θ = 0.3 にちがいない!⇐ これ も 1 つの仮説に過ぎない. • どの仮説が正しいか?すなわち表が出る確率 θ は幾つになるか?これをデータ xi を用いて推 定する. • そもそもどの仮説が正しいのかは「確実」には分からない.そこで,データが与えられた時, ある仮説 Hi が支持される確率,Pr(Hi|D) を求めることにする. • ベイズの定理より, Pr(Hi|D) = Pr(Hi, D) Pr(D) = Pr(D, Hi) Pr(D) (4) = Pr(D|Hi)Pr(Hi) Pr(D) (5) • コイン投げの場合,Hi は表が出る確率 θ の値に対応.θ は 0 から 1 の連続値を取り得る.従っ て,上のベイズ定理の式は確率密度関数 f(·) に置き換わる. f(θ|x) = f(θ, x) f(x) = f(x, θ) f(x) = f(x|θ)f(θ) f(x) (6) ただし Hi = θ は連続値をとり,x はデータ D の観測値を表すとする.ちなみに x は n 回の コイン投げで表が出た回数を表すとする. 西南学院大学 演習 II(2019 年) 3 担当 市東 亘
4.
(6) 式の考察 • 右辺の各密度関数が決まれば左辺の事後分布
f(θ|x) が定まる. ⇒ この事後分布を求める行為こそがベイズ推定! • θ の値は仮説に対応するので,事後分布 f(θ|x) が求まれば様々な仮説を統計的に検証できる. • 例. 「表が出にくいイカサマコイン」かどうか調べるには,事後分布を使って θ < 0.5 の確率 を計算すれば良い. ∫ 0.5 0 f(θ|x)dθ = • 実際には上の計算に分母の f(x) は必要ない. • (6) 式の分母を左辺に移行し,以下のように変形する. f(x)f(θ|x) = f(x|θ)f(θ) この式の両辺を積分し,比をとることによって確率を計算できる. ∫ 0.5 0 f(x)f(θ|x)dθ ∫ ∞ −∞ f(x)f(θ|x)dθ = ∫ 0.5 0 f(x|θ)f(θ)dθ ∫ ∞ −∞ f(x|θ)f(θ)dθ ←→ f(x) ∫ 0.5 0 f(θ|x)dθ f(x) ∫ ∞ −∞ f(θ|x)dθ = ∫ 0.5 0 f(x|θ)f(θ)dθ ∫ ∞ −∞ f(x|θ)f(θ)dθ ←→ ∫ 0.5 0 f(θ|x)dθ = ∫ 0.5 0 f(x|θ)f(θ)dθ ∫ ∞ −∞ f(x|θ)f(θ)dθ , ( ∫ ∞ −∞ f(θ|x)dθ = 1 より) (7) コイン投げのモデルでは,θ の値域は 0 ≤ θ ≤ 1 なので分母の積分範囲もこの範囲でよい. • つまり,ベイズの定理 (6) 式の分子,f(x|θ)f(θ),の関数形のみ分かれば,あとは同じ関数 の積分の比で事後確率 f(θ|x) が求まり,周辺尤度 f(x) の情報は不要. • 結局,(6) 式の分母 f(x) は θ に依存せず,比にすると約分されて消えるので定数とみなすこ とができる. • 実際,1/f(x) を比例定数 c とおき, f(θ|x) = cf(x|θ)f(θ) ∝ f(x|θ)f(θ) と書ける. 西南学院大学 演習 II(2019 年) 4 担当 市東 亘
5.
• したがってベイズ推定では (6)
式を以下のように比例式で表すことが多い. f(θ|x) ∝ f(x|θ)f(θ) • この事後分布の密度関数を,与えられたデータから推定するのがベイズ推定! 推定 • 事前分布の決定 – データが観測される前に「表が出る確率 θ」が従う分布についての情報は? – 「理由不十分の原則」⇒ 一様分布 を仮定する. – 適切な事前分布の選び方については第 6 章で学ぶ. • 尤度の決定 – 尤度関数 = データが従う統計モデルにおいてパラメータを所与とし,データを確率変 数とみなす関数. – コイン投げは各試行が独立なので表や裏が出る順番は関係ない.表が何回出たかで分布 が決まる. – 総試行回数 = n,表が出る回数 = x とおく. – x ∼ nCxθx (1 − θ)n−x = ( n x ) θx (1 − θ)n−x – 尤度は,上式の θ を所与とし,観測データ x の関数とみなすことで定義できる. f(x|θ) = ( n x ) θx (1 − θ)n−x • 事後分布を求める. f(θ|x) ∝ f(x|θ)f(θ) = ( n x ) θx (1 − θ)n−x · 1 ∝ θx (1 − θ)n−x ( n x ) は θ に依存しないため積分の比で消える. 考察 • データ x が与えられた時,表が出る確率 θ が従う分布の密度関数の比例式が求まった. ⇒ これでベイズ推定は完了. • 事後分布の密度関数(の比例式)が求まったので,あとは実際のデータを式に代入すれば密 度関数のグラフが描ける2 . ⇒ テキスト p.7 の図 1.1. 2事後分布 f(θ|x) は右辺 θx(1 − θ)n−x の定数倍になるので,グラフの縦軸の値は左辺の値と等しくないが,θ の分布 (散らばり具合が全体に占める割合)は変わらない.右辺の比例式から確率を求めるには (7) 式(p.4)のように積分の比 を取る必要がある. 西南学院大学 演習 II(2019 年) 5 担当 市東 亘
6.
• ただし, ::::::::::::::::: 図の生成コードでは,右辺の
θx (1 − θ)n−x の代わりにベータ分布の密度関数を使用 している. • なぜか? • 事後分布 f(θ|x) ∝ θx (1 − θ)n−x の式は 2 項分布の密度関数に形が似ているが,2 項分布は が確率変数なのに対し,事後分布は が確率変数だから. • ベータ分布の密度関数 fBeta(x; α, β) = xα−1 (1 − x)β−1 B(α, β) – 0 ≤ x ≤ 1,x はベータ分布に従う正の実数.α と β はパラメータ. – B(α, β) はベータ関数で,B(α, β) = ∫ 1 0 xα−1 (1 − x)β−1 dx. • 事後分布の比例式はベータ分布の密度関数を用いて表せる. f(θ|x) ∝ θx (1 − θ)n−x = fBeta(θ; α, β) B(α, β) where α = 1 + x β = 1 + n − x ∝ fBeta(θ; α, β) since B(α, β) is constant. • コイン投げ問題では事後分布の関数形を明示的に求めることができたが,変数が相互に影響 しあうような統計モデルでは,事後分布の関数形を式で明示的に表すのは難しい. • 確率を求めるためには密度関数の積分が必要だが,代数的式変形で積分計算できる関数形は 限られている. • そこで,コンピュータを使って事後分布の関数形を近似的に求め,数値積分して確率を求め る. ⇒ Stan,JAGS,PyMC 等のソフトを使う. • テキスト第 2 章以降で PyMC を使った事後分布の推定方法を学ぶ. 西南学院大学 演習 II(2019 年) 6 担当 市東 亘
7.
2.3 コイン投げ問題の Python
による視覚化 0.0 0.2 0.4 0.6 0.8 1.0 p, probability of heads 0 2 4 observe 0 tosses, 0 heads 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 observe 1 tosses, 0 heads 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 observe 2 tosses, 1 heads 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 observe 3 tosses, 1 heads 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 observe 4 tosses, 1 heads 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 observe 5 tosses, 2 heads 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 observe 8 tosses, 3 heads 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 observe 15 tosses, 8 heads 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 observe 50 tosses, 23 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, probability of heads 0 10 observe 500 tosses, 257 heads Bayesian updating of posterior probabilities 図 1: Bayesian updating of posterior probabilities 西南学院大学 演習 II(2019 年) 7 担当 市東 亘
8.
コード 1 コイン投げ 1
%matplotlib inline 2 3 import numpy as np 4 import matplotlib.pyplot as plt 5 import scipy.stats as stats 6 7 dist = stats.beta # ベータ分布のクラスインスタンスを取得. 8 n_trials = [0, 1, 2, 3, 4, 5, 8, 15, 50, 500] # コイン投げの試行回数を指定する配列 9 data = stats.bernoulli.rvs(0.5, size=n_trials[-1]) # p=0.5 で 500 回のベルヌーイ試行データを生成 10 heads = np.concatenate([[0], data.cumsum(0)]) # 累積和で表が出た回数の配列を作成.最初に 0 回試行分を付加. 11 x = np.linspace(0, 1, 100) # 0 から 1 まで等間隔の 100 個の数列を作成.プロットの x 座標の値になる. 12 13 # 描画領域全体を表す fig オブジェクトと各グラフ・オブジェクトの配列( 「行 x 列」の 2 次元配列)を生成 14 fig, axes2d = plt.subplots( 15 nrows=int(len(n_trials)/2), 16 ncols=2, 17 figsize=(11, 9)) 18 19 axes = axes2d.flatten() # 行 x 列の配列を 1 次元配列にフラット化 20 21 for ax, N in zip(axes, n_trials): 22 head = heads[N] 23 y = dist.pdf(x, 1 + head, 1 + N - head) # ベータ分布の PDF.与えられた x 値に対する PDF の y 値を返す. 24 ax.plot(x, y, label="observe %d tosses,n %d heads" % (N, head)) # データをプロット 25 ax.fill_between(x, 0, y, color="#348ABD", alpha=0.4) # 塗りつぶし 26 ax.vlines(0.5, 0, 4, color="k", linestyles="--", lw=1) # x=0.5, y=0 から 4 まで垂直線 27 ax.legend().get_frame().set_alpha(0.4) # 凡例のフレームの濃さを設定 28 ax.autoscale(tight=True) 29 30 # 最初と最後の図だけ x 軸にラベルを付ける 31 axes[0].set_xlabel("$p$, probability of heads") 32 axes[-1].set_xlabel("$p$, probability of heads") 33 34 fig.suptitle("Bayesian updating of posterior probabilities", 35 y=1.02, 36 fontsize=14) 37 38 fig.tight_layout() • matplotlib.pyplot の使い方 – 図の描画領域全体は Figure クラス・オブジェクトを通してコントロールする. – 座標軸を持つ各グラフは,Axes クラス・オブジェクトを通してコントロールする. • ベルヌーイ試行で実際にデータを生成してから,データを所与として事後分布を計算し描画 している. • 事後分布の描画にはベータ分布の密度関数が用いられている. 西南学院大学 演習 II(2019 年) 8 担当 市東 亘
9.
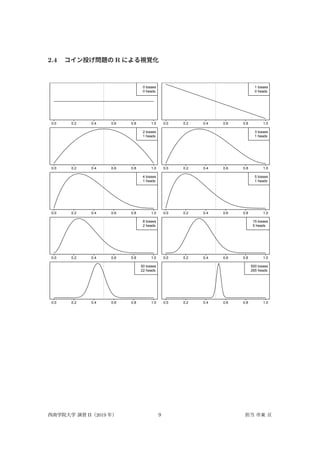
2.4 コイン投げ問題の R
による視覚化 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 0 tosses 0 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 1 tosses 0 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 2 tosses 1 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 3 tosses 1 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 4 tosses 1 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 5 tosses 1 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 8 tosses 2 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 15 tosses 5 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 50 tosses 22 heads 0.0 0.2 0.4 0.6 0.8 1.0 p, prob of heads 500 tosses 265 heads 西南学院大学 演習 II(2019 年) 9 担当 市東 亘
10.
n.trials <- c(0,
1, 2, 3, 4, 5, 8, 15, 50, 500) # 10 種類の試行回数 # R のインデックスは 1 からなので n.trials[10] は 500 data <- sample(c(0,1), size=n.trials[length(n.trials)], replace=TRUE) posterior <- function(data, size) { heads <- sum(data[1:size]) par(mar=c(1.8,0.5,0,0.5)) # 描画領域を増やすためにマージンパラメータを調整 curve(dbeta(x, 1+heads, 1+size-heads), 0, 1, # ベータ分布の曲線を描画 xlab="p, prob of heads", ylab='',yaxt='n', mgp=c(3,0.3,0), # 軸タイトル,軸ラベル,軸線が描かれる位置を設定 tcl=-0.25 # 軸の目盛り線の長さ設定 ) abline(v=0.5, lty=3) # x=0.5 で垂直 vertical な線を描画.lty は線種 legend("topright", legend=c(paste(size, "tosses"), paste(heads, "heads"))) } par(mfrow=c(length(n.trials)/2, 2)) # マルチ figure の行数,列数を設定 # n.trials ベクトルの各要素に対し,第 2 引数の関数を適用. # 第 2 引数の関数は posterior 関数を実行しグラフを描画. # 返り値は使わないので silent に代入して破棄. silent <- lapply(n.trials, function(size) { posterior(data,size) NULL}) • R の配列(ベクトル)のインデックスは 1 から始まる. • 上の R コードには Python コード中にあった for ループがない. ⇒ 関数型プログラミングと呼ばれるスタイルで書かれたもの. • for ループは手続き型プログラミングでよく使われる. • 関数型プログラミングでは,単一の処理を関数にまとめ,その関数を複数の要素に対し適用 (apply)することで繰り返し処理を実現する. 3 まとめ: ベイズ推定の手順 • リサーチ・クエスチョン(仮説)を立てる. • 仮説の下で生成されるデータを特定する. • データが従う統計モデルを構築する. • 事前分布を特定する. • ベイズの定理を用いて仮説を表すパラメータを推定する. • 事後分布を用いて仮説が支持される確率を計算したり,データの予測を行う. 西南学院大学 演習 II(2019 年) 10 担当 市東 亘
Download








![コード 1 コイン投げ
1 %matplotlib inline
2
3 import numpy as np
4 import matplotlib.pyplot as plt
5 import scipy.stats as stats
6
7 dist = stats.beta # ベータ分布のクラスインスタンスを取得.
8 n_trials = [0, 1, 2, 3, 4, 5, 8, 15, 50, 500] # コイン投げの試行回数を指定する配列
9 data = stats.bernoulli.rvs(0.5, size=n_trials[-1]) # p=0.5 で 500 回のベルヌーイ試行データを生成
10 heads = np.concatenate([[0], data.cumsum(0)]) # 累積和で表が出た回数の配列を作成.最初に 0 回試行分を付加.
11 x = np.linspace(0, 1, 100) # 0 から 1 まで等間隔の 100 個の数列を作成.プロットの x 座標の値になる.
12
13 # 描画領域全体を表す fig オブジェクトと各グラフ・オブジェクトの配列(
「行 x 列」の 2 次元配列)を生成
14 fig, axes2d = plt.subplots(
15 nrows=int(len(n_trials)/2),
16 ncols=2,
17 figsize=(11, 9))
18
19 axes = axes2d.flatten() # 行 x 列の配列を 1 次元配列にフラット化
20
21 for ax, N in zip(axes, n_trials):
22 head = heads[N]
23 y = dist.pdf(x, 1 + head, 1 + N - head) # ベータ分布の PDF.与えられた x 値に対する PDF の y 値を返す.
24 ax.plot(x, y, label="observe %d tosses,n %d heads" % (N, head)) # データをプロット
25 ax.fill_between(x, 0, y, color="#348ABD", alpha=0.4) # 塗りつぶし
26 ax.vlines(0.5, 0, 4, color="k", linestyles="--", lw=1) # x=0.5, y=0 から 4 まで垂直線
27 ax.legend().get_frame().set_alpha(0.4) # 凡例のフレームの濃さを設定
28 ax.autoscale(tight=True)
29
30 # 最初と最後の図だけ x 軸にラベルを付ける
31 axes[0].set_xlabel("$p$, probability of heads")
32 axes[-1].set_xlabel("$p$, probability of heads")
33
34 fig.suptitle("Bayesian updating of posterior probabilities",
35 y=1.02,
36 fontsize=14)
37
38 fig.tight_layout()
• matplotlib.pyplot の使い方
– 図の描画領域全体は Figure クラス・オブジェクトを通してコントロールする.
– 座標軸を持つ各グラフは,Axes クラス・オブジェクトを通してコントロールする.
• ベルヌーイ試行で実際にデータを生成してから,データを所与として事後分布を計算し描画
している.
• 事後分布の描画にはベータ分布の密度関数が用いられている.
西南学院大学 演習 II(2019 年) 8 担当 市東 亘](https://image.slidesharecdn.com/ch01-coin-handout-210823071848/85/II-Part-2-8-320.jpg)
![n.trials <- c(0, 1, 2, 3, 4, 5, 8, 15, 50, 500) # 10 種類の試行回数
# R のインデックスは 1 からなので n.trials[10] は 500
data <- sample(c(0,1), size=n.trials[length(n.trials)], replace=TRUE)
posterior <- function(data, size) {
heads <- sum(data[1:size])
par(mar=c(1.8,0.5,0,0.5)) # 描画領域を増やすためにマージンパラメータを調整
curve(dbeta(x, 1+heads, 1+size-heads), 0, 1, # ベータ分布の曲線を描画
xlab="p, prob of heads", ylab='',yaxt='n',
mgp=c(3,0.3,0), # 軸タイトル,軸ラベル,軸線が描かれる位置を設定
tcl=-0.25 # 軸の目盛り線の長さ設定
)
abline(v=0.5, lty=3) # x=0.5 で垂直 vertical な線を描画.lty は線種
legend("topright", legend=c(paste(size, "tosses"),
paste(heads, "heads")))
}
par(mfrow=c(length(n.trials)/2, 2)) # マルチ figure の行数,列数を設定
# n.trials ベクトルの各要素に対し,第 2 引数の関数を適用.
# 第 2 引数の関数は posterior 関数を実行しグラフを描画.
# 返り値は使わないので silent に代入して破棄.
silent <- lapply(n.trials, function(size) {
posterior(data,size)
NULL})
• R の配列(ベクトル)のインデックスは 1 から始まる.
• 上の R コードには Python コード中にあった for ループがない.
⇒ 関数型プログラミングと呼ばれるスタイルで書かれたもの.
• for ループは手続き型プログラミングでよく使われる.
• 関数型プログラミングでは,単一の処理を関数にまとめ,その関数を複数の要素に対し適用
(apply)することで繰り返し処理を実現する.
3 まとめ: ベイズ推定の手順
• リサーチ・クエスチョン(仮説)を立てる.
• 仮説の下で生成されるデータを特定する.
• データが従う統計モデルを構築する.
• 事前分布を特定する.
• ベイズの定理を用いて仮説を表すパラメータを推定する.
• 事後分布を用いて仮説が支持される確率を計算したり,データの予測を行う.
西南学院大学 演習 II(2019 年) 10 担当 市東 亘](https://image.slidesharecdn.com/ch01-coin-handout-210823071848/85/II-Part-2-10-320.jpg)






























































