Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Ken'ichi Matsui
14,097 views
「深層学習」勉強会LT資料 "Chainer使ってみた"
機械学習プロフェッショナルシリーズの「深層学習」勉強会のLTスライドです。
Data & Analytics
◦
Related topics:
Deep Learning
•
Read more
61
Save
Share
Embed
Embed presentation
Download
Downloaded 115 times
1
/ 38
2
/ 38
3
/ 38
4
/ 38
5
/ 38
6
/ 38
7
/ 38
8
/ 38
9
/ 38
10
/ 38
11
/ 38
12
/ 38
13
/ 38
14
/ 38
15
/ 38
16
/ 38
17
/ 38
18
/ 38
19
/ 38
20
/ 38
21
/ 38
22
/ 38
23
/ 38
24
/ 38
25
/ 38
26
/ 38
27
/ 38
28
/ 38
29
/ 38
30
/ 38
31
/ 38
32
/ 38
33
/ 38
34
/ 38
35
/ 38
36
/ 38
37
/ 38
38
/ 38
More Related Content
PPTX
Jupyter NotebookとChainerで楽々Deep Learning
by
Jun-ya Norimatsu
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
PDF
科学技術計算関連Pythonパッケージの概要
by
Toshihiro Kamishima
PDF
画像認識で物を見分ける
by
Kazuaki Tanida
PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習
by
Motoya Wakiyama
PDF
深層学習フレームワークChainerの紹介とFPGAへの期待
by
Seiya Tokui
PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
Jupyter NotebookとChainerで楽々Deep Learning
by
Jun-ya Norimatsu
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
科学技術計算関連Pythonパッケージの概要
by
Toshihiro Kamishima
画像認識で物を見分ける
by
Kazuaki Tanida
2013.07.15 はじパタlt scikit-learnで始める機械学習
by
Motoya Wakiyama
深層学習フレームワークChainerの紹介とFPGAへの期待
by
Seiya Tokui
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
What's hot
PDF
Introduction to Chainer (LL Ring Recursive)
by
Kenta Oono
PDF
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
PDF
Chainerの使い方と 自然言語処理への応用
by
Yuya Unno
PDF
Chainer の Trainer 解説と NStepLSTM について
by
Retrieva inc.
PDF
ディープラーニングフレームワーク とChainerの実装
by
Ryosuke Okuta
PDF
Chainerの使い方と自然言語処理への応用
by
Seiya Tokui
PDF
ディープニューラルネット入門
by
TanUkkii
PDF
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
PPTX
Deep Learning基本理論とTensorFlow
by
Tadaichiro Nakano
PDF
深層学習フレームワーク Chainer の開発と今後の展開
by
Seiya Tokui
PDF
GPU上でのNLP向け深層学習の実装について
by
Yuya Unno
PDF
Python 機械学習プログラミング データ分析演習編
by
Etsuji Nakai
PDF
PythonによるDeep Learningの実装
by
Shinya Akiba
PDF
Deep learning入門
by
magoroku Yamamoto
PDF
mxnetで頑張る深層学習
by
Takashi Kitano
PDF
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
PDF
Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾)
by
Ohsawa Goodfellow
PDF
TensorFlowの使い方(in Japanese)
by
Toshihiko Yamakami
PDF
Deep Learning を実装する
by
Shuhei Iitsuka
PDF
Chainer v1.6からv1.7の新機能
by
Ryosuke Okuta
Introduction to Chainer (LL Ring Recursive)
by
Kenta Oono
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
Chainerの使い方と 自然言語処理への応用
by
Yuya Unno
Chainer の Trainer 解説と NStepLSTM について
by
Retrieva inc.
ディープラーニングフレームワーク とChainerの実装
by
Ryosuke Okuta
Chainerの使い方と自然言語処理への応用
by
Seiya Tokui
ディープニューラルネット入門
by
TanUkkii
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
Deep Learning基本理論とTensorFlow
by
Tadaichiro Nakano
深層学習フレームワーク Chainer の開発と今後の展開
by
Seiya Tokui
GPU上でのNLP向け深層学習の実装について
by
Yuya Unno
Python 機械学習プログラミング データ分析演習編
by
Etsuji Nakai
PythonによるDeep Learningの実装
by
Shinya Akiba
Deep learning入門
by
magoroku Yamamoto
mxnetで頑張る深層学習
by
Takashi Kitano
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾)
by
Ohsawa Goodfellow
TensorFlowの使い方(in Japanese)
by
Toshihiko Yamakami
Deep Learning を実装する
by
Shuhei Iitsuka
Chainer v1.6からv1.7の新機能
by
Ryosuke Okuta
Similar to 「深層学習」勉強会LT資料 "Chainer使ってみた"
PDF
Chainer, Cupy入門
by
Yuya Unno
PDF
[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用
by
de:code 2017
PDF
[第2版]Python機械学習プログラミング 第16章
by
Haruki Eguchi
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PDF
NINと画像分類 for 人工知能LT祭
by
t dev
PPTX
Chainer Familyで始めるComputer Visionの研究・開発【修正版】
by
belltailjp
PDF
Chainerチュートリアル -v1.5向け- ViEW2015
by
Ryosuke Okuta
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也
by
Preferred Networks
DOCX
深層学習 Day1レポート
by
taishimotoda
PDF
Introduction to Chainer and CuPy
by
Kenta Oono
PDF
日本神経回路学会セミナー「DeepLearningを使ってみよう!」資料
by
Kenta Oono
PDF
Scikit-learn and TensorFlow Chap-14 RNN (v1.1)
by
孝好 飯塚
PDF
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
PPTX
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
by
Naonori Nagano
PDF
2015年9月18日 (GTC Japan 2015) 深層学習フレームワークChainerの導入と化合物活性予測への応用
by
Kenta Oono
PDF
TensorflowとKerasによる深層学習のプログラム実装実践講座
by
Ruo Ando
PDF
深層学習フレームワーク Chainerとその進化
by
Yuya Unno
PPTX
PythonでDeepLearningを始めるよ
by
Tanaka Yuichi
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
Chainer, Cupy入門
by
Yuya Unno
[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用
by
de:code 2017
[第2版]Python機械学習プログラミング 第16章
by
Haruki Eguchi
Deep learning実装の基礎と実践
by
Seiya Tokui
NINと画像分類 for 人工知能LT祭
by
t dev
Chainer Familyで始めるComputer Visionの研究・開発【修正版】
by
belltailjp
Chainerチュートリアル -v1.5向け- ViEW2015
by
Ryosuke Okuta
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也
by
Preferred Networks
深層学習 Day1レポート
by
taishimotoda
Introduction to Chainer and CuPy
by
Kenta Oono
日本神経回路学会セミナー「DeepLearningを使ってみよう!」資料
by
Kenta Oono
Scikit-learn and TensorFlow Chap-14 RNN (v1.1)
by
孝好 飯塚
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
by
Naonori Nagano
2015年9月18日 (GTC Japan 2015) 深層学習フレームワークChainerの導入と化合物活性予測への応用
by
Kenta Oono
TensorflowとKerasによる深層学習のプログラム実装実践講座
by
Ruo Ando
深層学習フレームワーク Chainerとその進化
by
Yuya Unno
PythonでDeepLearningを始めるよ
by
Tanaka Yuichi
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
More from Ken'ichi Matsui
PDF
ベータ分布の謎に迫る
by
Ken'ichi Matsui
PDF
音楽波形データからコードを推定してみる
by
Ken'ichi Matsui
PDF
データサイエンティストの仕事とデータ分析コンテスト
by
Ken'ichi Matsui
PDF
分析コンペティションの光と影
by
Ken'ichi Matsui
PDF
Kaggle Google Quest Q&A Labeling 反省会 LT資料 47th place solution
by
Ken'ichi Matsui
PDF
BERT入門
by
Ken'ichi Matsui
PDF
データ分析コンテストとデータサイエンティストの働きかた
by
Ken'ichi Matsui
PDF
確率分布の成り立ちを理解してスポーツにあてはめてみる
by
Ken'ichi Matsui
PDF
SIGNATE 産業技術総合研究所 衛星画像分析コンテスト 2位入賞モデルの工夫点
by
Ken'ichi Matsui
PDF
Introduction of VAE
by
Ken'ichi Matsui
PDF
Variational Autoencoderの紹介
by
Ken'ichi Matsui
PDF
数学カフェ 確率・統計・機械学習回 「速習 確率・統計」
by
Ken'ichi Matsui
PDF
DS LT祭り 「AUCが0.01改善したって どういうことですか?」
by
Ken'ichi Matsui
PDF
統計的学習の基礎 4章 前半
by
Ken'ichi Matsui
PDF
基礎からのベイズ統計学 輪読会資料 第8章 「比率・相関・信頼性」
by
Ken'ichi Matsui
PDF
第13回数学カフェ「素数!!」二次会 LT資料「乱数!!」
by
Ken'ichi Matsui
PDF
「ベータ分布の謎に迫る」第6回 プログラマのための数学勉強会 LT資料
by
Ken'ichi Matsui
PPTX
15分でわかる(範囲の)ベイズ統計学
by
Ken'ichi Matsui
PPTX
Random Forest による分類
by
Ken'ichi Matsui
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
ベータ分布の謎に迫る
by
Ken'ichi Matsui
音楽波形データからコードを推定してみる
by
Ken'ichi Matsui
データサイエンティストの仕事とデータ分析コンテスト
by
Ken'ichi Matsui
分析コンペティションの光と影
by
Ken'ichi Matsui
Kaggle Google Quest Q&A Labeling 反省会 LT資料 47th place solution
by
Ken'ichi Matsui
BERT入門
by
Ken'ichi Matsui
データ分析コンテストとデータサイエンティストの働きかた
by
Ken'ichi Matsui
確率分布の成り立ちを理解してスポーツにあてはめてみる
by
Ken'ichi Matsui
SIGNATE 産業技術総合研究所 衛星画像分析コンテスト 2位入賞モデルの工夫点
by
Ken'ichi Matsui
Introduction of VAE
by
Ken'ichi Matsui
Variational Autoencoderの紹介
by
Ken'ichi Matsui
数学カフェ 確率・統計・機械学習回 「速習 確率・統計」
by
Ken'ichi Matsui
DS LT祭り 「AUCが0.01改善したって どういうことですか?」
by
Ken'ichi Matsui
統計的学習の基礎 4章 前半
by
Ken'ichi Matsui
基礎からのベイズ統計学 輪読会資料 第8章 「比率・相関・信頼性」
by
Ken'ichi Matsui
第13回数学カフェ「素数!!」二次会 LT資料「乱数!!」
by
Ken'ichi Matsui
「ベータ分布の謎に迫る」第6回 プログラマのための数学勉強会 LT資料
by
Ken'ichi Matsui
15分でわかる(範囲の)ベイズ統計学
by
Ken'ichi Matsui
Random Forest による分類
by
Ken'ichi Matsui
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
「深層学習」勉強会LT資料 "Chainer使ってみた"
1.
Chainer使ってみた @kenmatsu4 2015.8.5 機械学習プロフェッショナルシリーズ輪読会 #4 Lightning Talk
2.
自己紹介 ・Twitterアカウント @kenmatsu4 ・Qiitaでブログを書いています(統計、機械学習、Python等) http://qiita.com/kenmatsu4 (2500 contributionを超えました!) ・趣味 - バンドでベースを弾いたりしています。 -
主に東南アジアへバックパック旅行に行ったりします (カンボジア、ミャンマー、バングラデシュ、新疆ウイグル自治区 etc) 旅行の写真 : http://matsu-ken.jimdo.com Twitterアイコン
3.
2015.6.9 Deep Learning Framework
Chainer Release!
4.
特徴 • All Pythonで記載ができるので、設定ファイル等 のフォーマットを覚える必要がない。 •
インストールが簡単 pip install chainer
5.
王道、MNIST手書き数字で試す。
6.
モデルは入力784 units、出力10 units
7.
# Prepare multi-layer
perceptron model # 多層パーセプトロンモデルの設定 # 入力 784次元、出力 10次元 model = FunctionSet( l1=F.Linear(784, n_units), l2=F.Linear(n_units, n_units), l3=F.Linear(n_units, 10)) コード:モデル定義
8.
# Prepare multi-layer
perceptron model # 多層パーセプトロンモデルの設定 # 入力 784次元、出力 10次元 model = FunctionSet( l1=F.Linear(784, n_units), l2=F.Linear(n_units, n_units), l3=F.Linear(n_units, 10)) コード:モデル定義(POINT:入出力定義)
9.
# ニューラルネットの構造 def forward(x_data,
y_data, train=True): x, t = Variable(x_data), Variable(y_data) h1 = F.dropout(F.relu(model.l1(x)), train=train) h2 = F.dropout(F.relu(model.l2(h1)), train=train) y = model.l3(h2) # 多クラス分類なので誤差関数としてソフトマックス関数の # 交差エントロピー関数を用いて、誤差を導出 return F.softmax_cross_entropy(y, t), F.accuracy(y, t) コード:順伝播
10.
# ニューラルネットの構造 def forward(x_data,
y_data, train=True): x, t = Variable(x_data), Variable(y_data) h1 = F.dropout(F.relu(model.l1(x)), train=train) h2 = F.dropout(F.relu(model.l2(h1)), train=train) y = model.l3(h2) # 多クラス分類なので誤差関数としてソフトマックス関数の # 交差エントロピー関数を用いて、誤差を導出 return F.softmax_cross_entropy(y, t), F.accuracy(y, t) コード:順伝播(POINT: Variableクラス)
11.
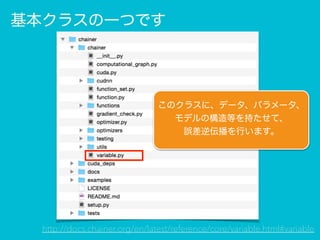
基本クラスの一つです http://docs.chainer.org/en/latest/reference/core/variable.html#variable
12.
基本クラスの一つです http://docs.chainer.org/en/latest/reference/core/variable.html#variable このクラスに、データ、パラメータ、 モデルの構造等を持たせて、 誤差逆伝播を行います。
13.
# ニューラルネットの構造 def forward(x_data,
y_data, train=True): x, t = Variable(x_data), Variable(y_data) h1 = F.dropout(F.relu(model.l1(x)), train=train) h2 = F.dropout(F.relu(model.l2(h1)), train=train) y = model.l3(h2) # 多クラス分類なので誤差関数としてソフトマックス関数の # 交差エントロピー関数を用いて、誤差を導出 return F.softmax_cross_entropy(y, t), F.accuracy(y, t) コード:順伝播(POINT: relu関数)
14.
コード:順伝播(POINT: relu関数) relu(x) =
max(0, x)
15.
# ニューラルネットの構造 def forward(x_data,
y_data, train=True): x, t = Variable(x_data), Variable(y_data) h1 = F.dropout(F.relu(model.l1(x)), train=train) h2 = F.dropout(F.relu(model.l2(h1)), train=train) y = model.l3(h2) # 多クラス分類なので誤差関数としてソフトマックス関数の # 交差エントロピー関数を用いて、誤差を導出 return F.softmax_cross_entropy(y, t), F.accuracy(y, t) コード:順伝播(POINT: dropout関数)
16.
コード:順伝播(POINT: dropout関数) x2# x783 x784 x1 x0 z10u10 z1u1 z2u1 z9u9 z1000u1000 z999u999 u1##z1 u2##z2 z0 z1000u1000 z999u999 u1##z1 u2##z2 z0
17.
コード:順伝播(POINT: dropout関数) x2# x784 x0 z10u10 z1u1 z2u1 z9u9 z999u999 u1##z1 z0 z1000u1000 u1##z1 z0
18.
# ニューラルネットの構造 def forward(x_data,
y_data, train=True): x, t = Variable(x_data), Variable(y_data) h1 = F.dropout(F.relu(model.l1(x)), train=train) h2 = F.dropout(F.relu(model.l2(h1)), train=train) y = model.l3(h2) # 多クラス分類なので誤差関数としてソフトマックス関数の # 交差エントロピー関数を用いて、誤差を導出 return F.softmax_cross_entropy(y, t), F.accuracy(y, t) コード:順伝播(POINT: softmax関数)
19.
コード:順伝播(POINT: softmax関数) yk =
zk = fk(u) = exp(uk) PK j exp(uj) En = X k dk log exp(uk) PK j exp(uj) ! 交差エントロピー関数 ソフトマックス関数
20.
# Setup optimizer optimizer
= optimizers.Adam() optimizer.setup(model.collect_parameters()) コード:Optimizerの設定 Optimizerで勾配法を選択する。 今回はAdamを使用。 http://ja.scribd.com/doc/260859670/30minutes-Adam Adamの参考
21.
for epoch in
xrange(1, n_epoch+1): perm = np.random.permutation(N) # 0∼Nまでのデータをバッチサイズごとに使って学習 for i in xrange(0, N, batchsize): x_batch = x_train[perm[i:i+batchsize]] y_batch = y_train[perm[i:i+batchsize]] # 勾配を初期化 optimizer.zero_grads() # 順伝播させて誤差と精度を算出 loss, acc = forward(x_batch, y_batch) # 誤差逆伝播で勾配を計算 loss.backward() optimizer.update() コード:学習
22.
train_loss.append(loss.data) train_acc.append(acc.data) sum_loss += float(cuda.to_cpu(loss.data)) *
batchsize sum_accuracy += float(cuda.to_cpu(acc.data)) * batchsize # 訓練データの誤差と、正解精度を表示 print 'train mean loss={}, accuracy={}' .format(sum_loss / N,sum_accuracy / N) コード:学習
23.
#evaluation #テストデータで誤差と、正解精度を算出し汎化性能を確認 sum_accuracy = 0 sum_loss
= 0 for i in xrange(0, N_test, batchsize): x_batch = x_test[i:i+batchsize] y_batch = y_test[i:i+batchsize] # 順伝播させて誤差と精度を算出 loss, acc = forward(x_batch, y_batch, train=False) test_loss.append(loss.data) test_acc.append(acc.data) コード:評価
24.
sum_loss += float(cuda.to_cpu(loss.data)) *
batchsize sum_accuracy += float(cuda.to_cpu(acc.data)) * batchsize # テストデータでの誤差と、正解精度を表示 print 'test mean loss={}, accuracy={}’ .format(sum_loss / N_test, sum_accuracy / N_test) コード:評価
25.
結果
26.
結果 間違ったのはこの1つだけ。 でも、9にも見えるので仕方ない!?
27.
結果:パラメーター の可視化w
28.
Autoencoder
29.
概要
30.
時間がないので結果だけ・・・
31.
活性化関数 中間層数 Dropout
ノイズ付加 Sigmoid 1000 あり なし 誤差の推移:20回しくらいで大体収束
32.
活性化関数 中間層数 Dropout
ノイズ付加 Sigmoid 1000 あり なし 出力結果:ほとんど復元できている
33.
活性化関数 中間層数 Dropout
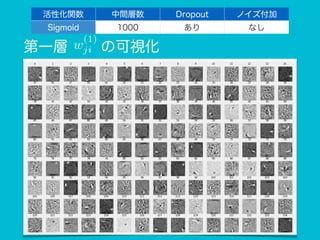
ノイズ付加 Sigmoid 1000 あり なし 第一層 w (1) ji の可視化
34.
活性化関数 中間層数 Dropout
ノイズ付加 Sigmoid 1000 あり なし 第一層 w (1) ji の可視化 結構、数字のエッジ等、 特徴らしきものを捉えられている
35.
活性化関数 中間層数 Dropout
ノイズ付加 Sigmoid 1000 あり なし 第二層 の可視化w (2) ji
36.
詳細はこちらをご覧ください! • 【機械学習】ディープラーニング フレームワーク Chainerを試しながら解説してみる。 http://qiita.com/kenmatsu4/items/7b8d24d4c5144a686412 •
【ディープラーニング】ChainerでAutoencoderを試 して結果を可視化してみる。 http://qiita.com/kenmatsu4/items/99d4a54d5a57405ecaf8
37.
また、Chainerの仕組みについては作者の方が非常に わかりやすくまとめられているので、ぜひご参考ください! http://www.slideshare.net/beam2d/chainer-atfpgax7
38.
Thanks • Chainer Homepage http://chainer.org •
Chainer Github page https://github.com/pfnet/chainer • Chainer Document http://docs.chainer.org • Azusa Colors (Keynote template) http://sanographix.github.io/azusa-colors/
Download




















![for epoch in xrange(1, n_epoch+1):
perm = np.random.permutation(N)
# 0∼Nまでのデータをバッチサイズごとに使って学習
for i in xrange(0, N, batchsize):
x_batch = x_train[perm[i:i+batchsize]]
y_batch = y_train[perm[i:i+batchsize]]
# 勾配を初期化
optimizer.zero_grads()
# 順伝播させて誤差と精度を算出
loss, acc = forward(x_batch, y_batch)
# 誤差逆伝播で勾配を計算
loss.backward()
optimizer.update()
コード:学習](https://image.slidesharecdn.com/lt20150805rev003-150805120446-lva1-app6891/85/LT-Chainer-21-320.jpg)

![#evaluation
#テストデータで誤差と、正解精度を算出し汎化性能を確認
sum_accuracy = 0
sum_loss = 0
for i in xrange(0, N_test, batchsize):
x_batch = x_test[i:i+batchsize]
y_batch = y_test[i:i+batchsize]
# 順伝播させて誤差と精度を算出
loss, acc = forward(x_batch,
y_batch, train=False)
test_loss.append(loss.data)
test_acc.append(acc.data)
コード:評価](https://image.slidesharecdn.com/lt20150805rev003-150805120446-lva1-app6891/85/LT-Chainer-23-320.jpg)










































![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第2版]Python機械学習プログラミング 第16章](https://cdn.slidesharecdn.com/ss_thumbnails/16-190318023255-thumbnail.jpg?width=640&height=640&fit=bounds)





![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)






























