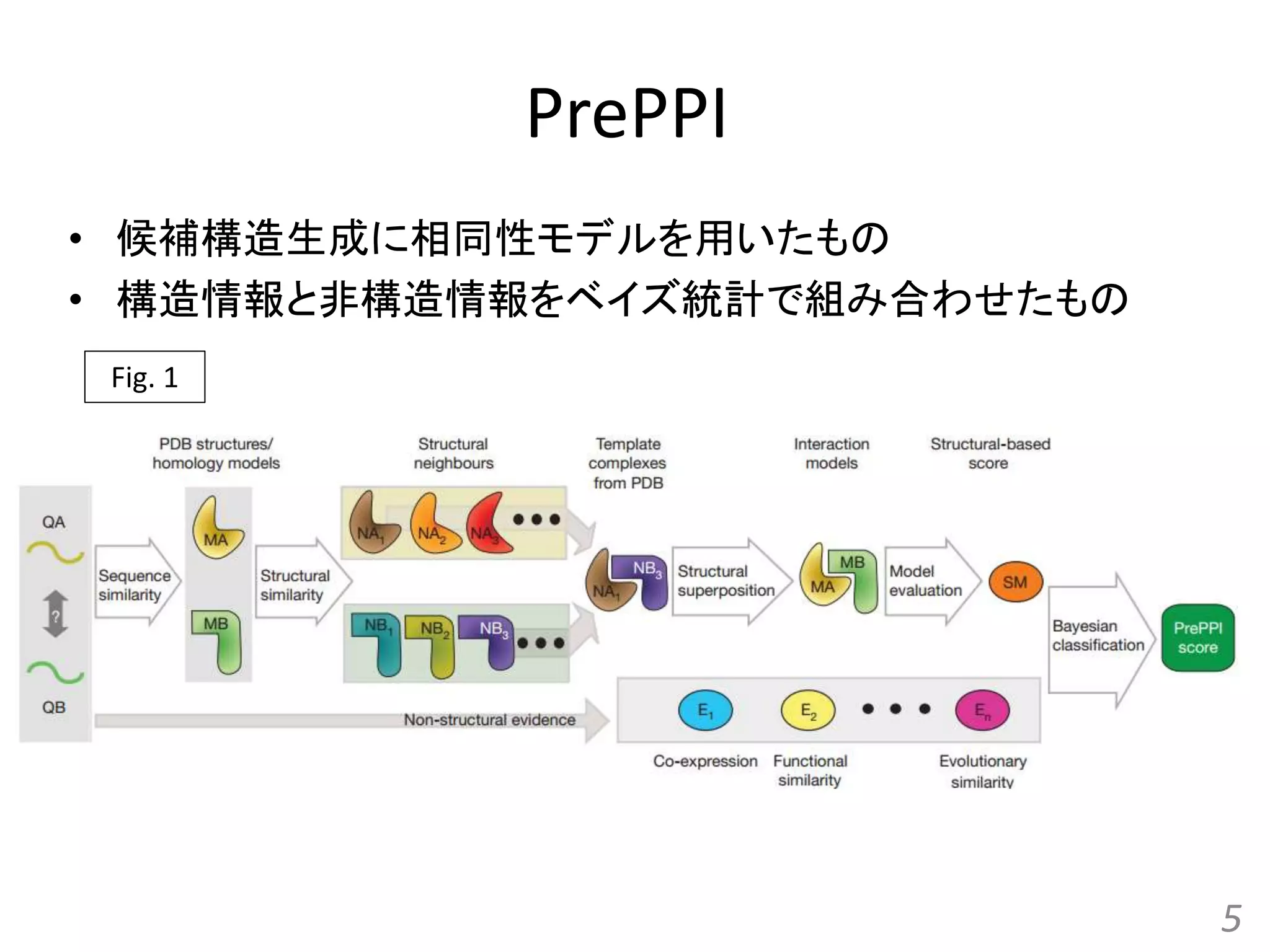
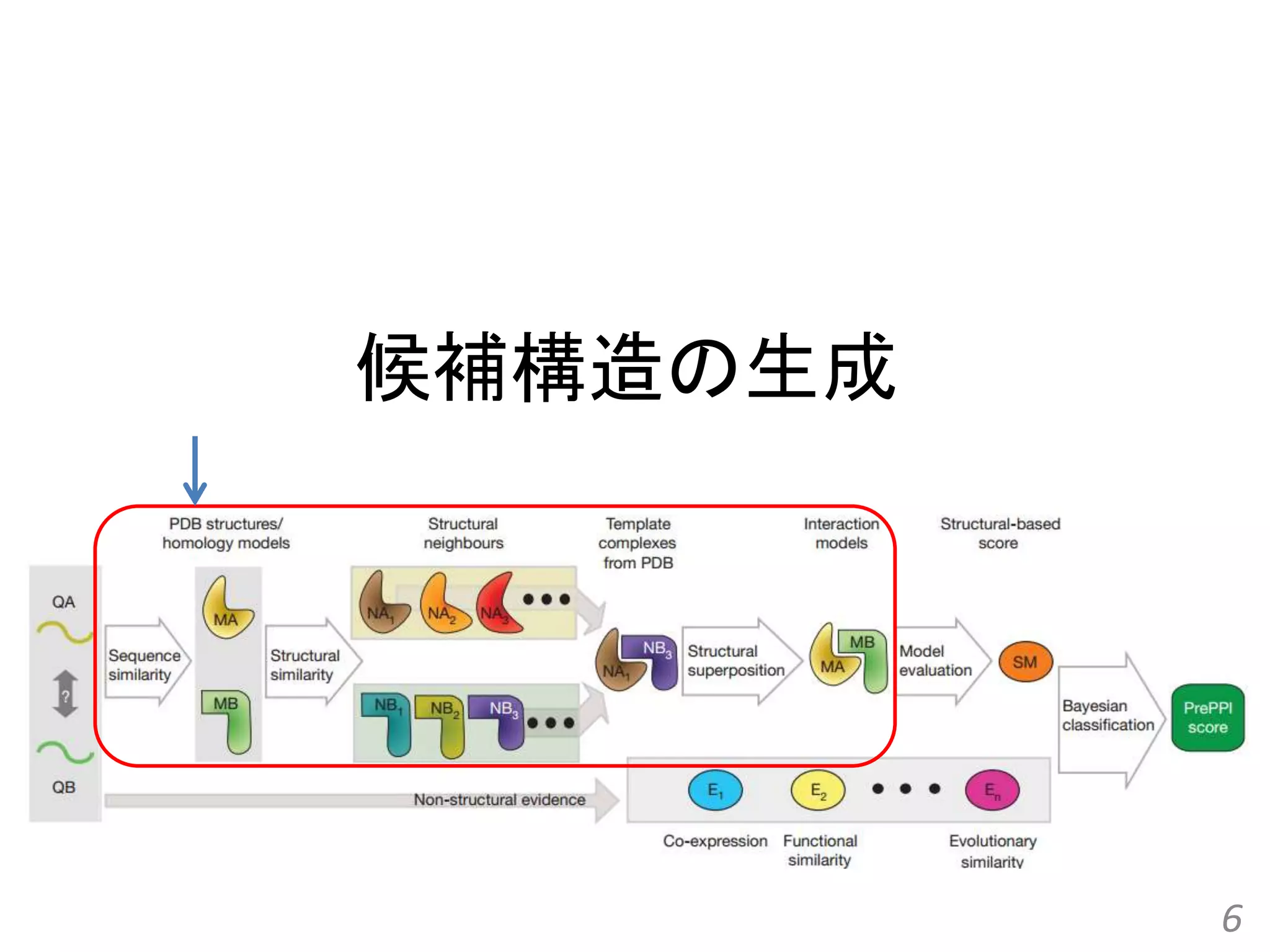
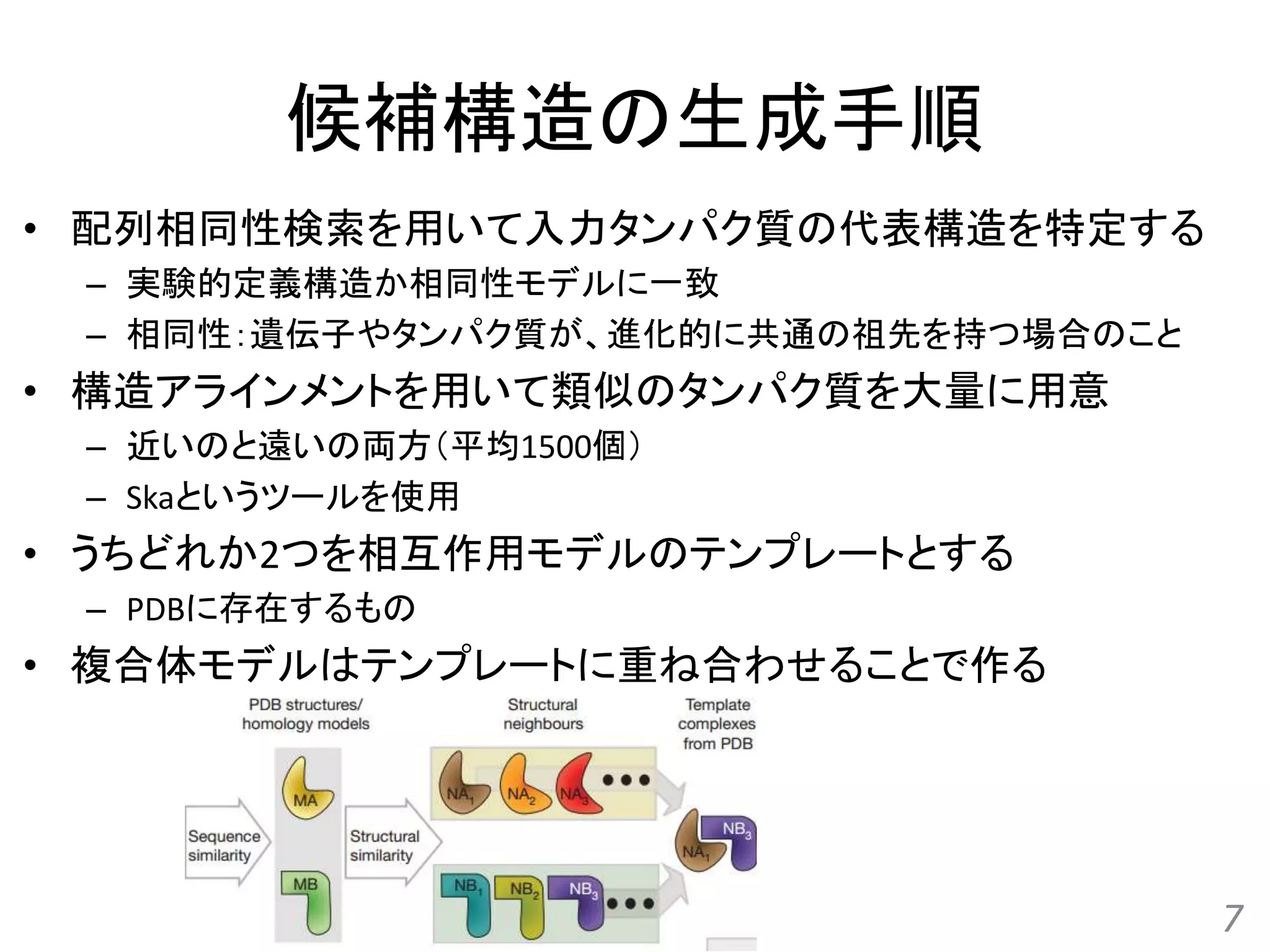
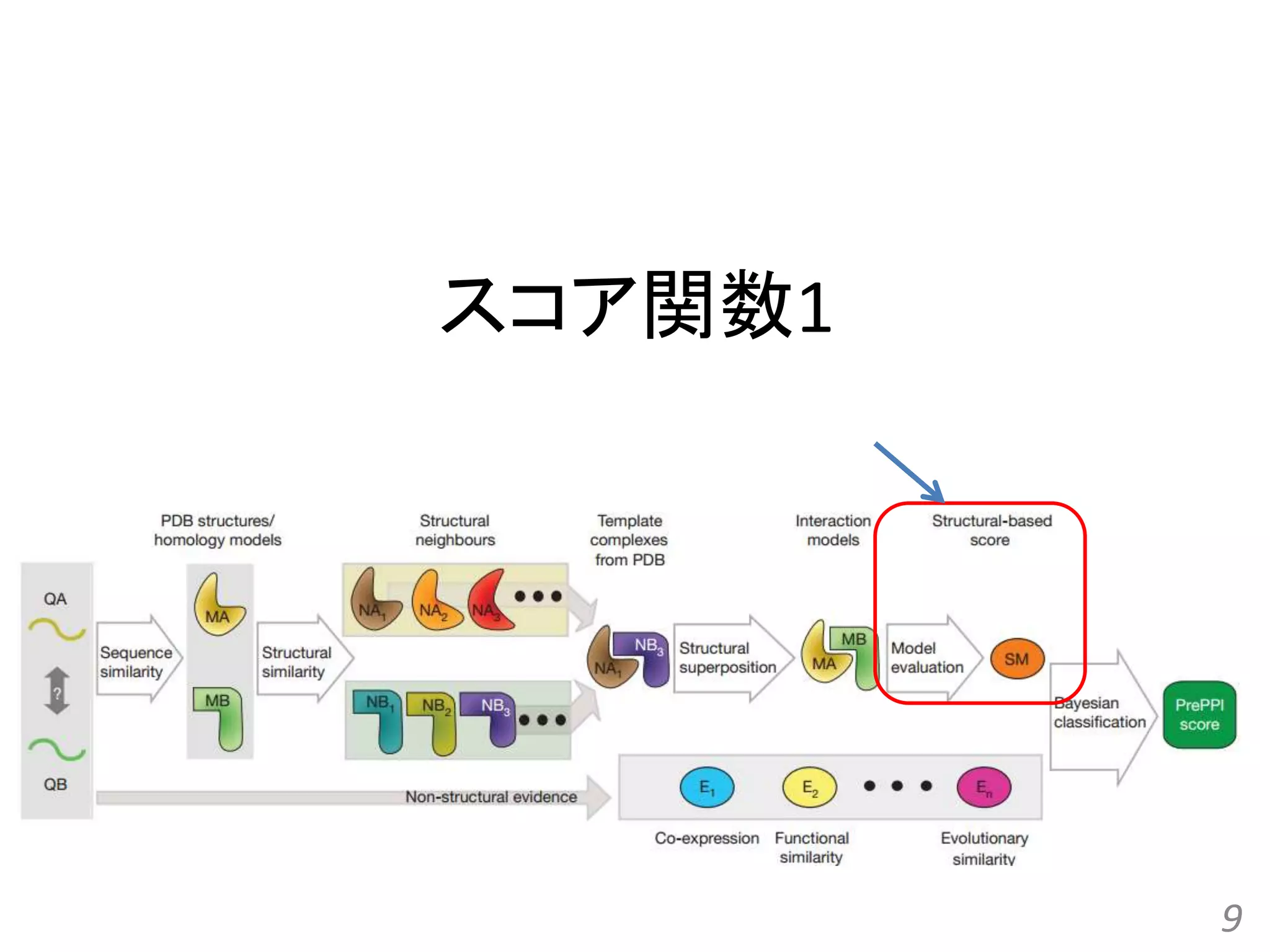
Structure-based prediction of protein-protein interactions on a genome-wide scale Qiangfeng Cliff Zhang, et al. Nature, 490(7421): 556-560, 2012.








![BN用いたモデル: 例
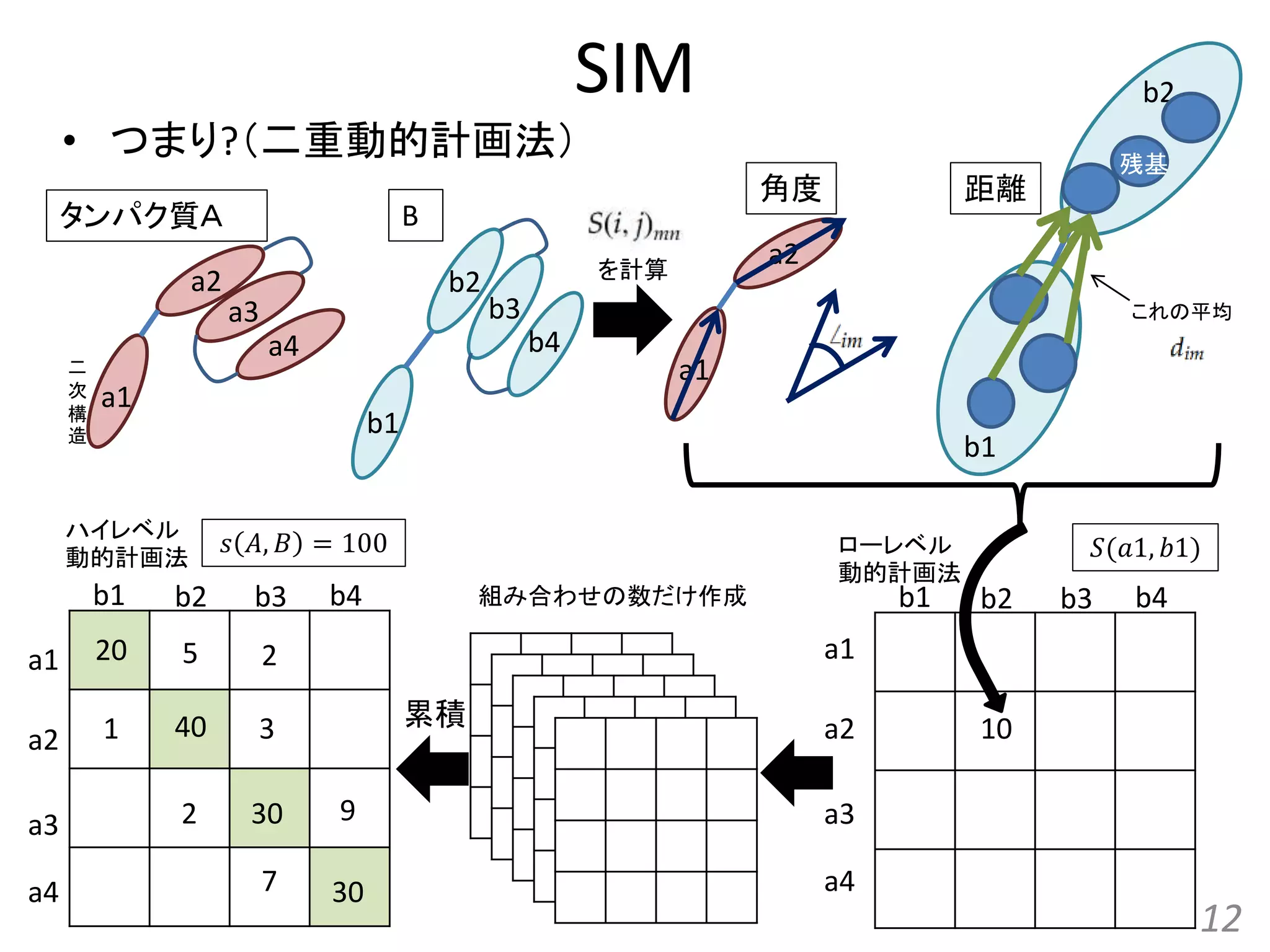
• つまり
22
10個 990個
HC N
学習データセット
𝑃 𝑁 =0.99
𝑃 𝐻𝐶 =0.01
HC:8
N:92
HC:2
N:898
0.5< 0.5≧
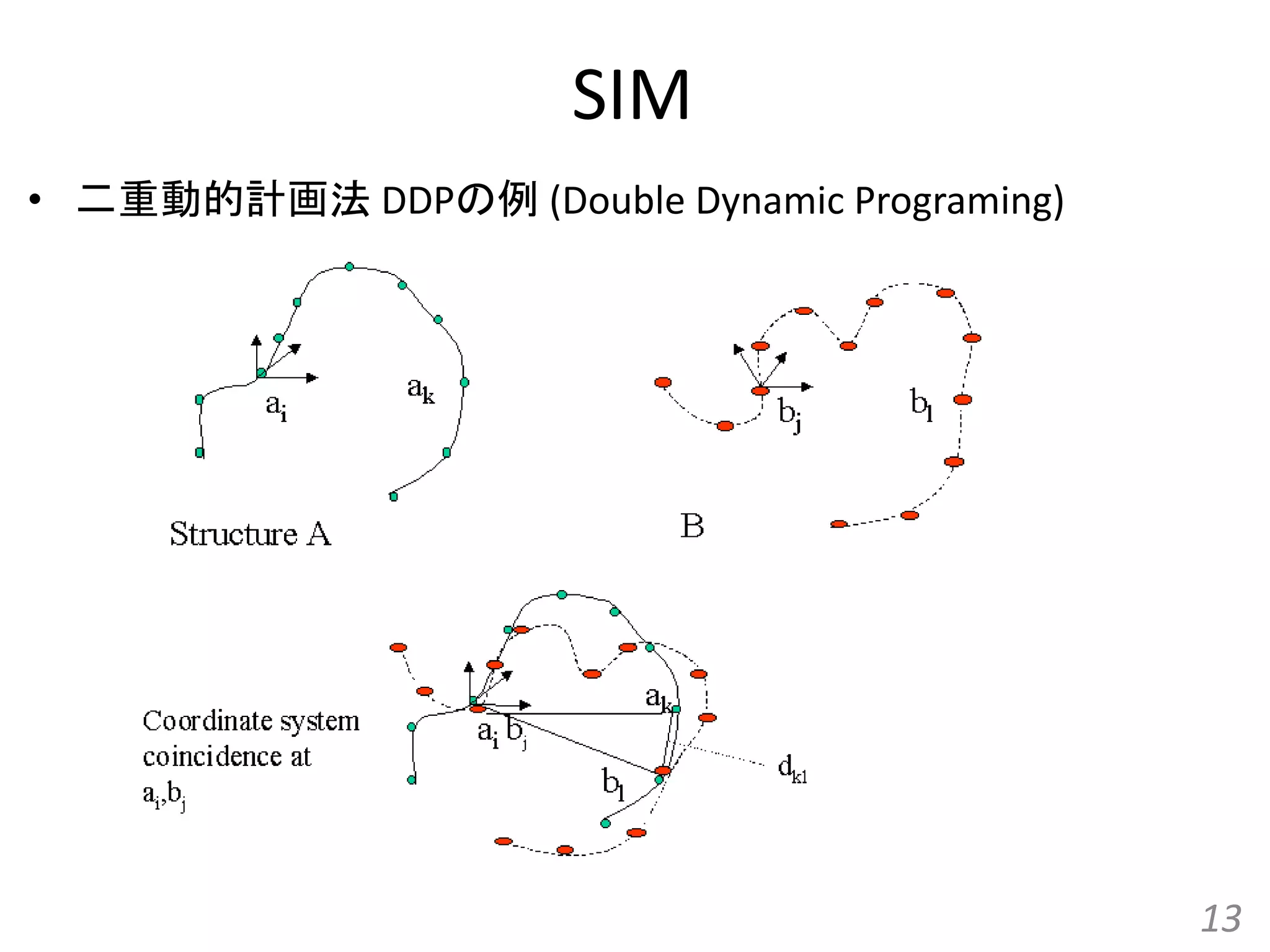
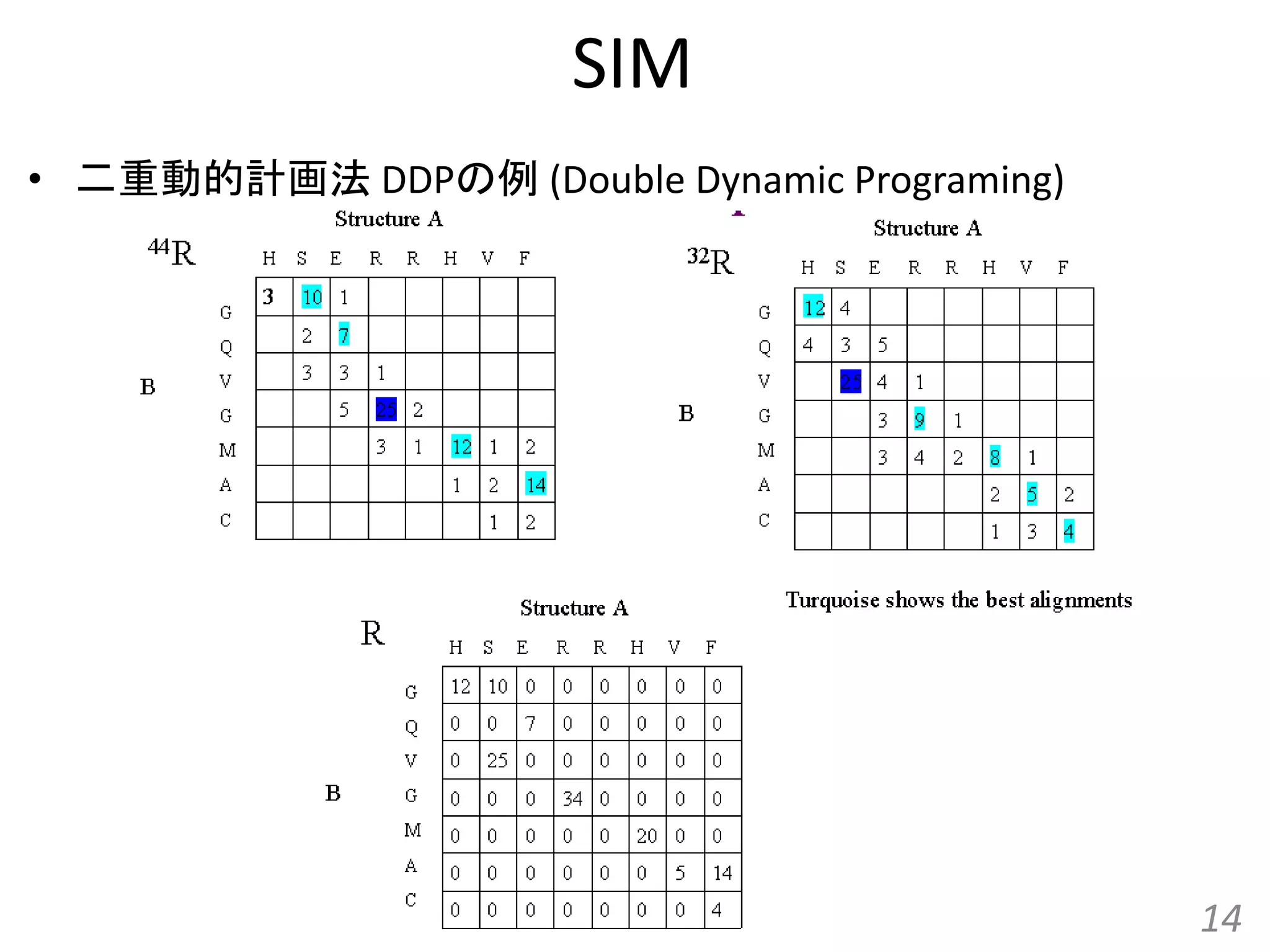
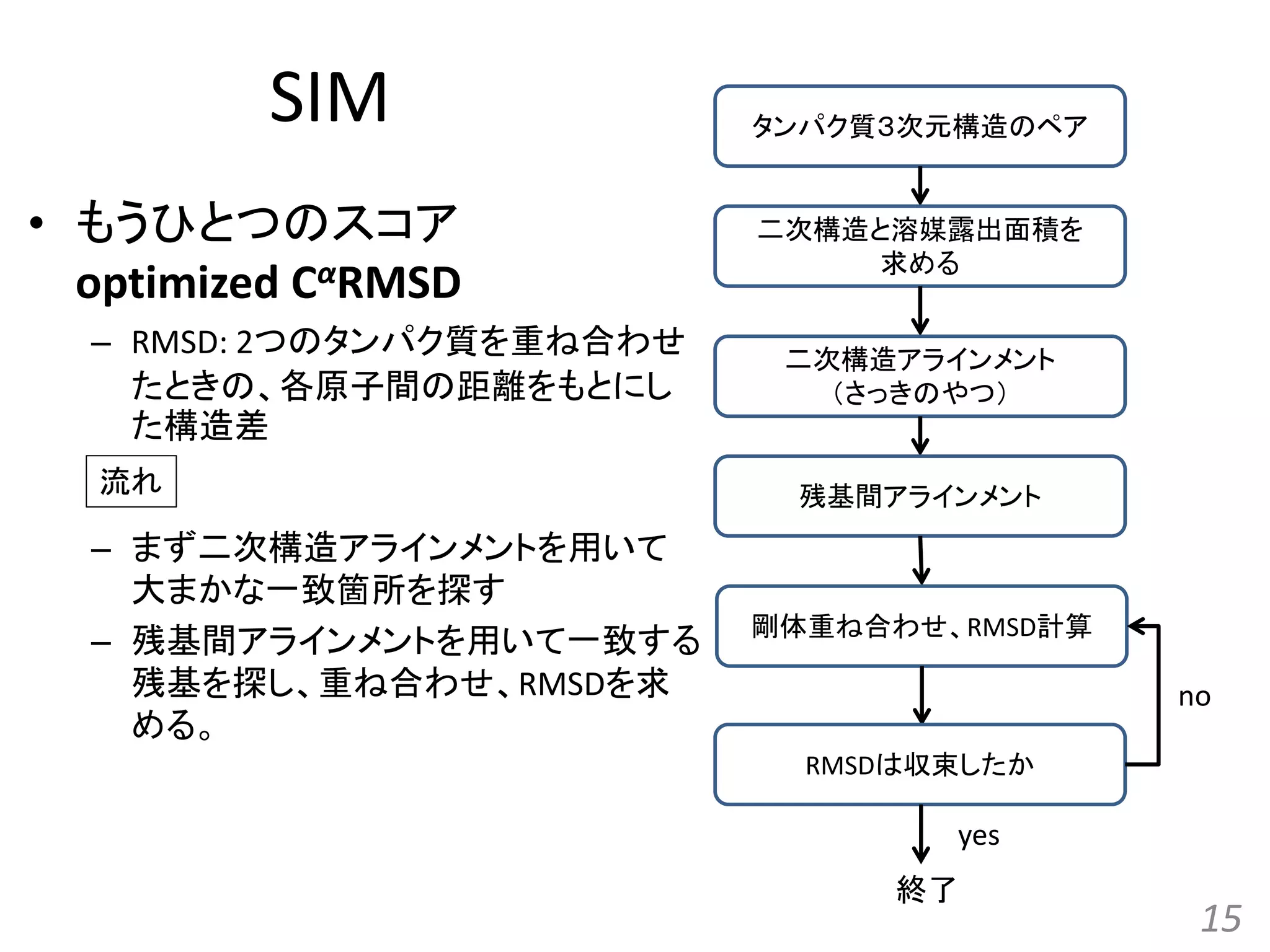
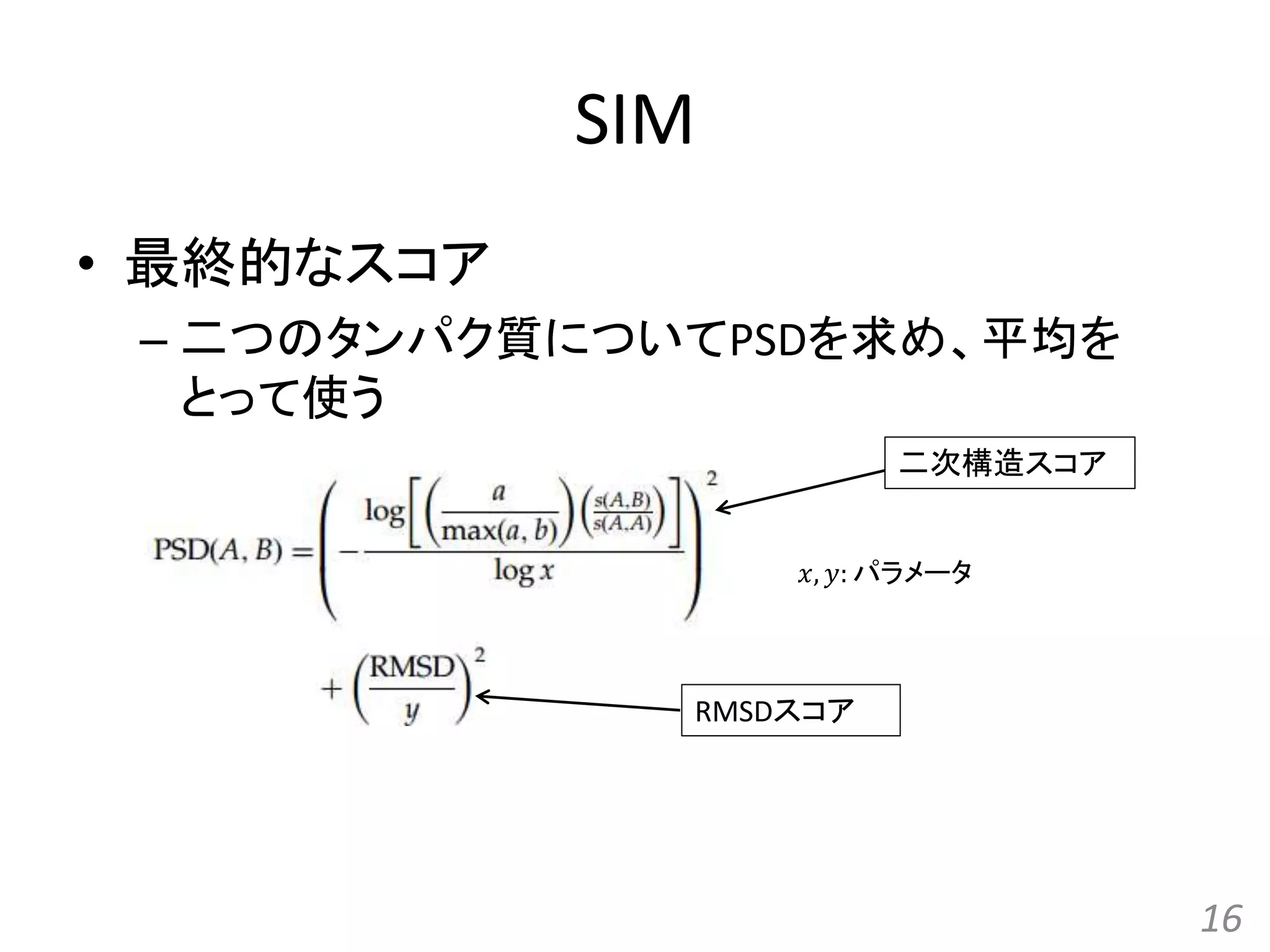
SIM
𝑃 𝐻𝐶|𝑏𝑖𝑛[𝑆𝐼𝑀 > 0.5] =0.08
𝑃 𝐻𝐶|𝑏𝑖𝑛[𝑆𝐼𝑀 ≤ 0.5] ≈0.002
𝑃 𝑁𝐶|𝑏𝑖𝑛[𝑆𝐼𝑀 > 0.5] =0.92
𝑃 𝑁𝐶|𝑏𝑖𝑛[𝑆𝐼𝑀 ≤ 0.5] ≈0.998
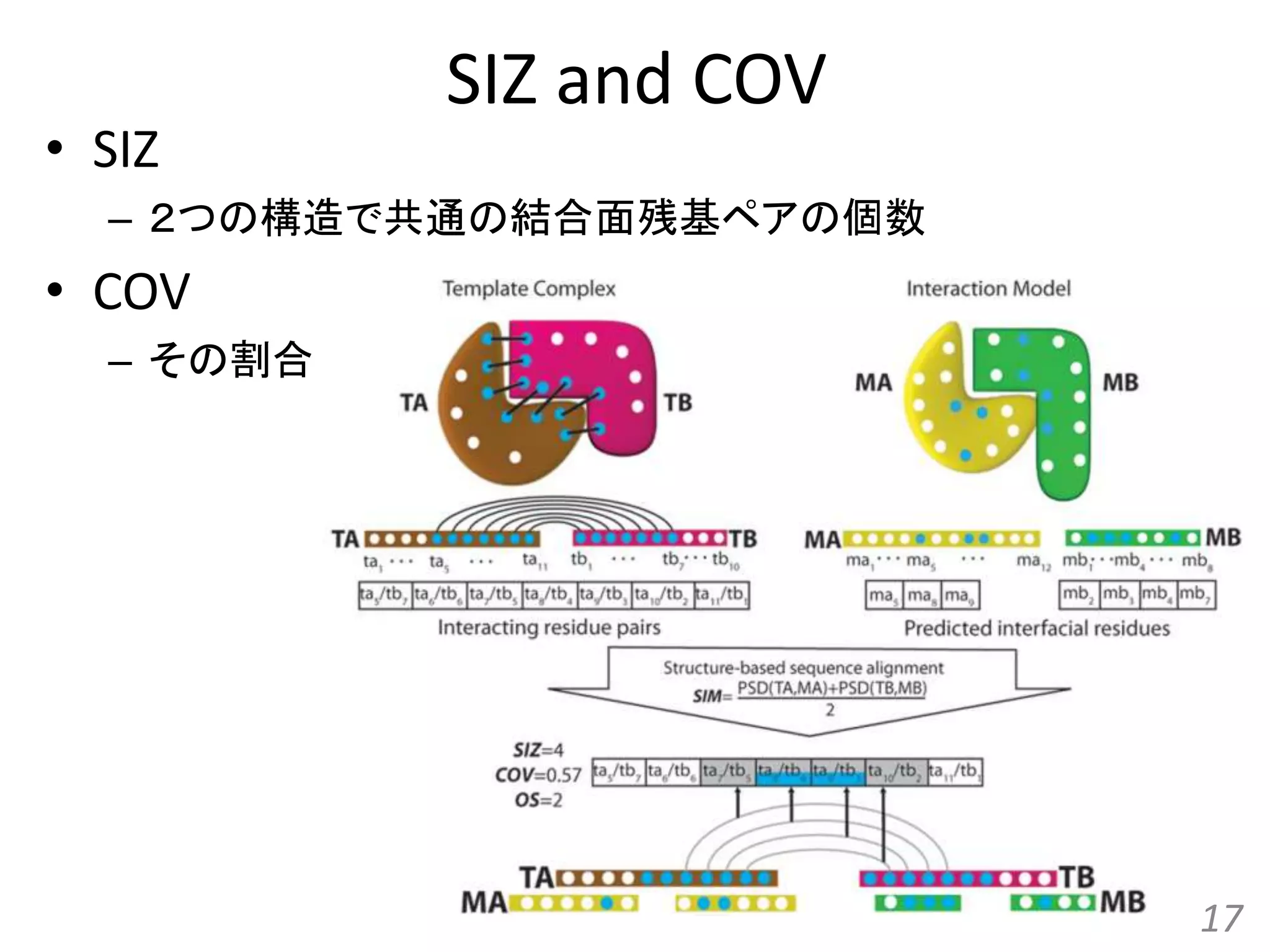
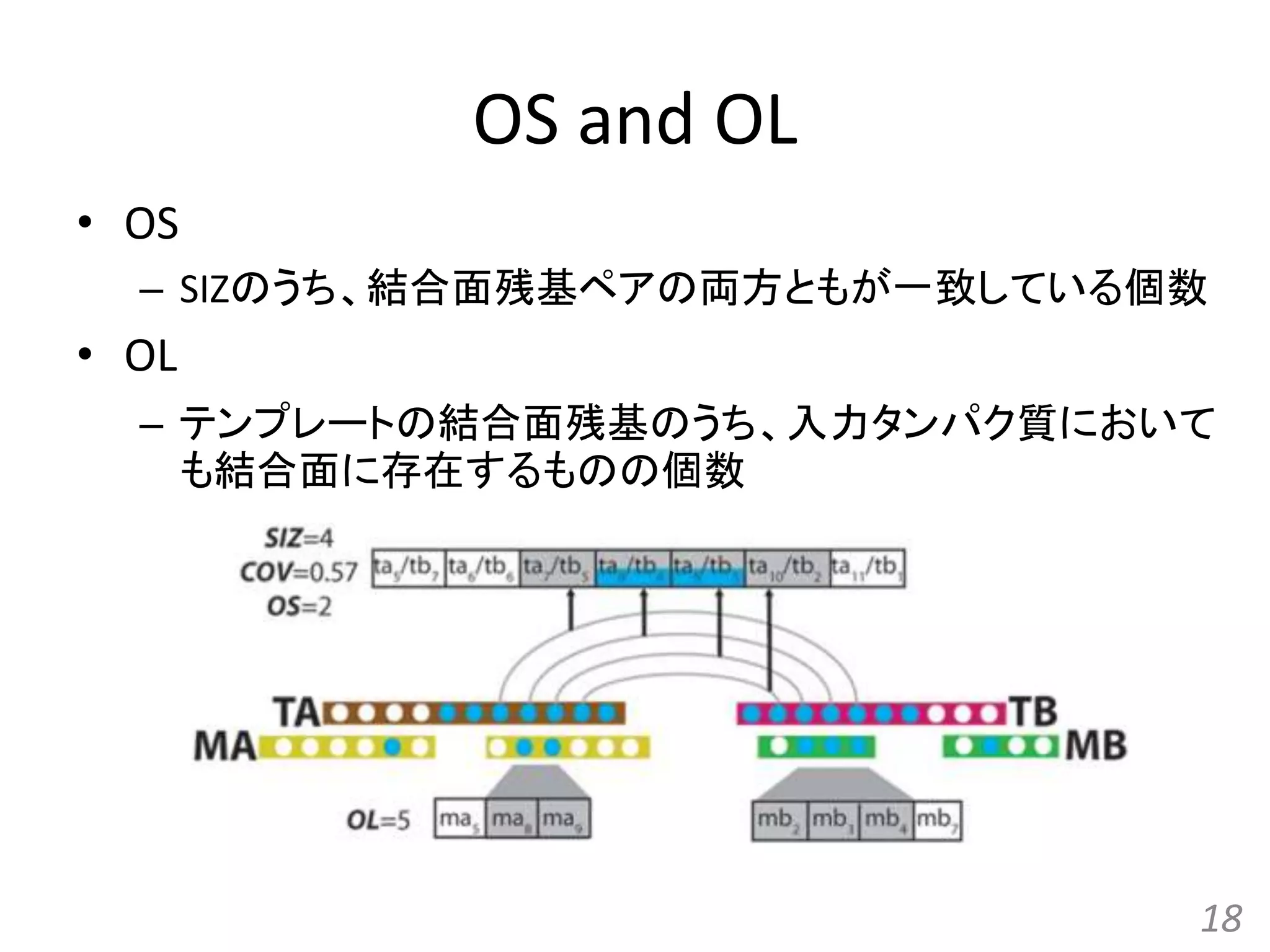
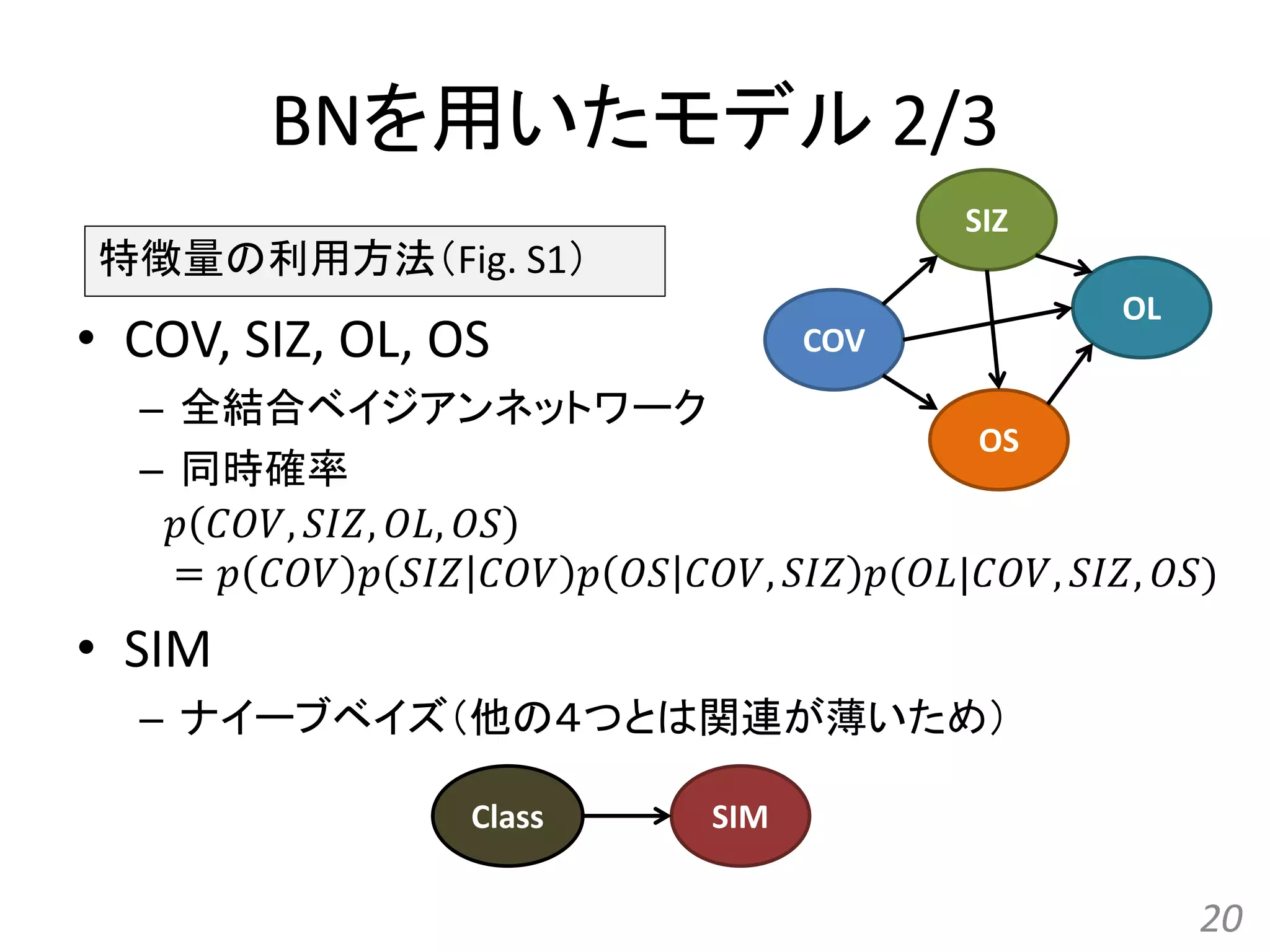
COV SIZ OS OL
4< 0.6< 3< 5<
HC:7 N:93
4≧ 0.6≧ 3≧ 5≧
HC:3 N:897
𝑃 𝐻𝐶|𝑏𝑖𝑛[𝐶𝑂𝑉 > 4, 𝑆𝐼𝑍 > 0.6, 𝑂𝑆 > 3, 𝑂𝐿 > 5] =0.07
𝑃 𝐻𝐶|𝑏𝑖𝑛[𝐶𝑂𝑉 ≤ 4, 𝑆𝐼𝑍 ≤ 0.6, 𝑂𝑆 ≤ 3, 𝑂𝐿 ≤ 5] ≈0.003
𝑃 𝑁|𝑏𝑖𝑛[𝐶𝑂𝑉 > 4, 𝑆𝐼𝑍 > 0.6, 𝑂𝑆 > 3, 𝑂𝐿 > 5] =0.93
𝑃 𝑁|𝑏𝑖𝑛[𝐶𝑂𝑉 ≤ 4, 𝑆𝐼𝑍 ≤ 0.6, 𝑂𝑆 ≤ 3, 𝑂𝐿 ≤ 5] ≈0.997
𝑂 𝑝𝑟𝑖𝑜𝑟1
𝑂 𝑝𝑟𝑖𝑜𝑟2
簡単化のため、
クラス数をとても
減らしています
𝑂 𝑝𝑟𝑖𝑜𝑟 =
1
99](https://image.slidesharecdn.com/preppi-140704053611-phpapp02/75/PrePPI-structure-based-protein-protein-interaction-prediction-22-2048.jpg)



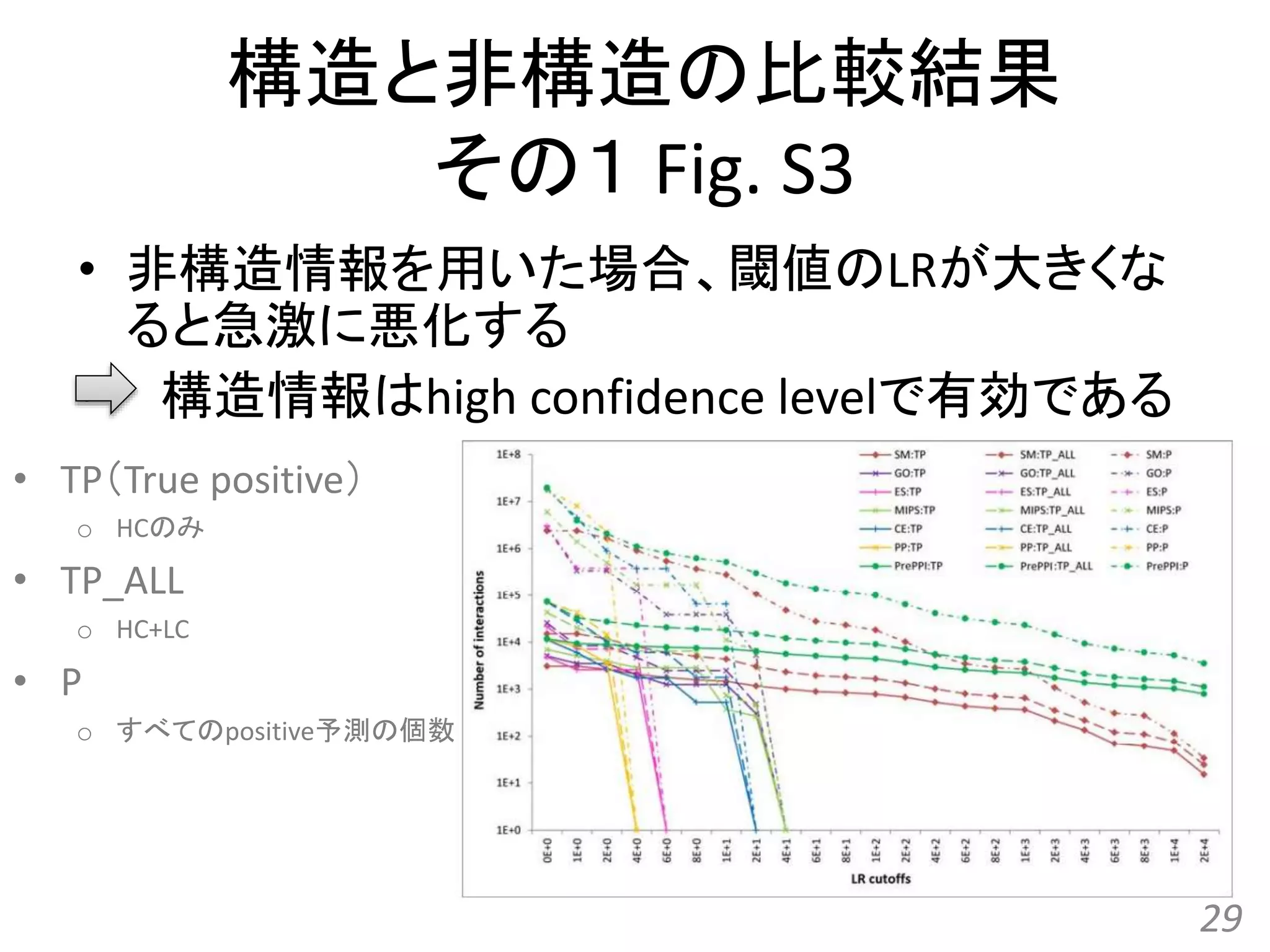
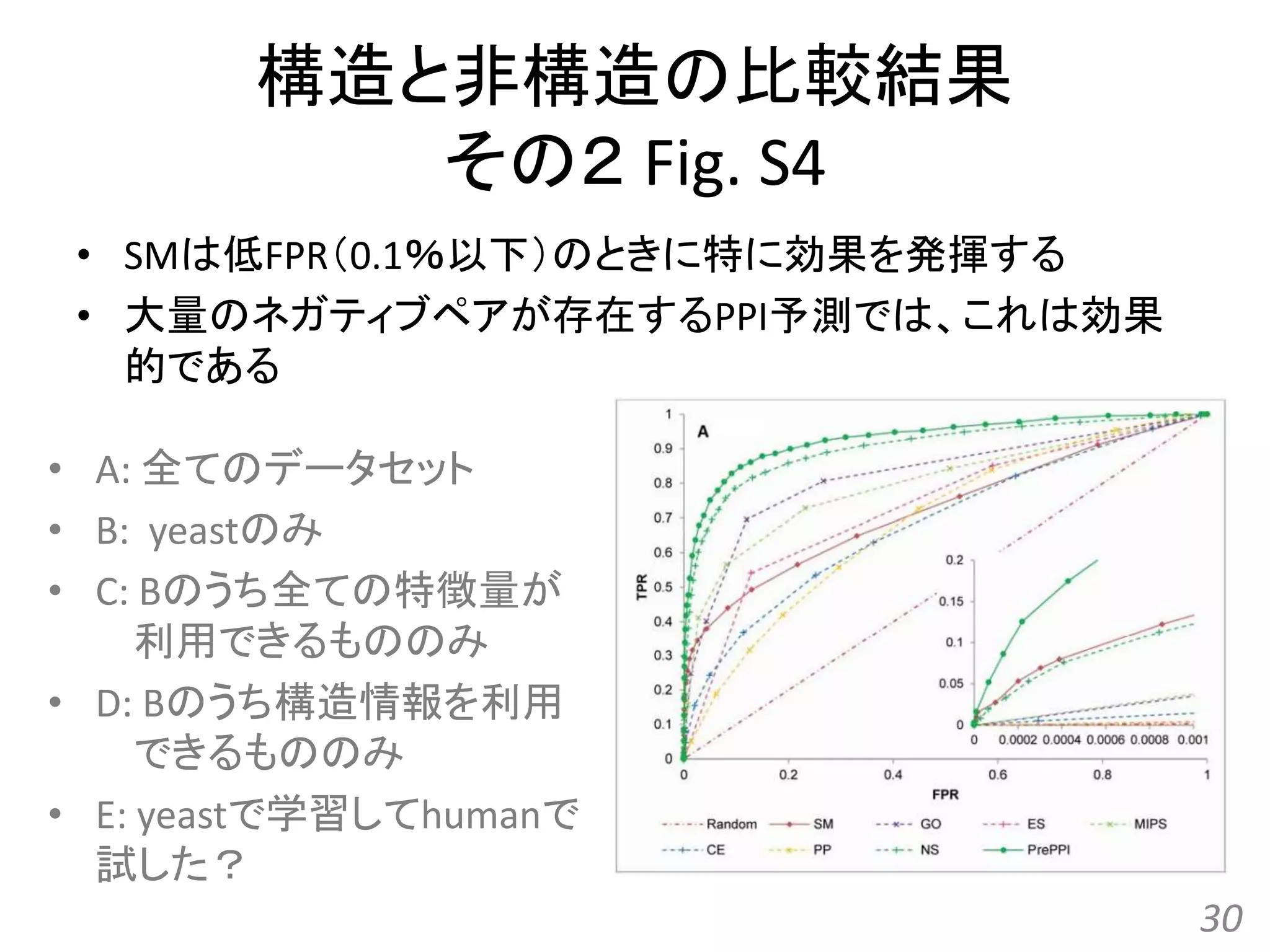
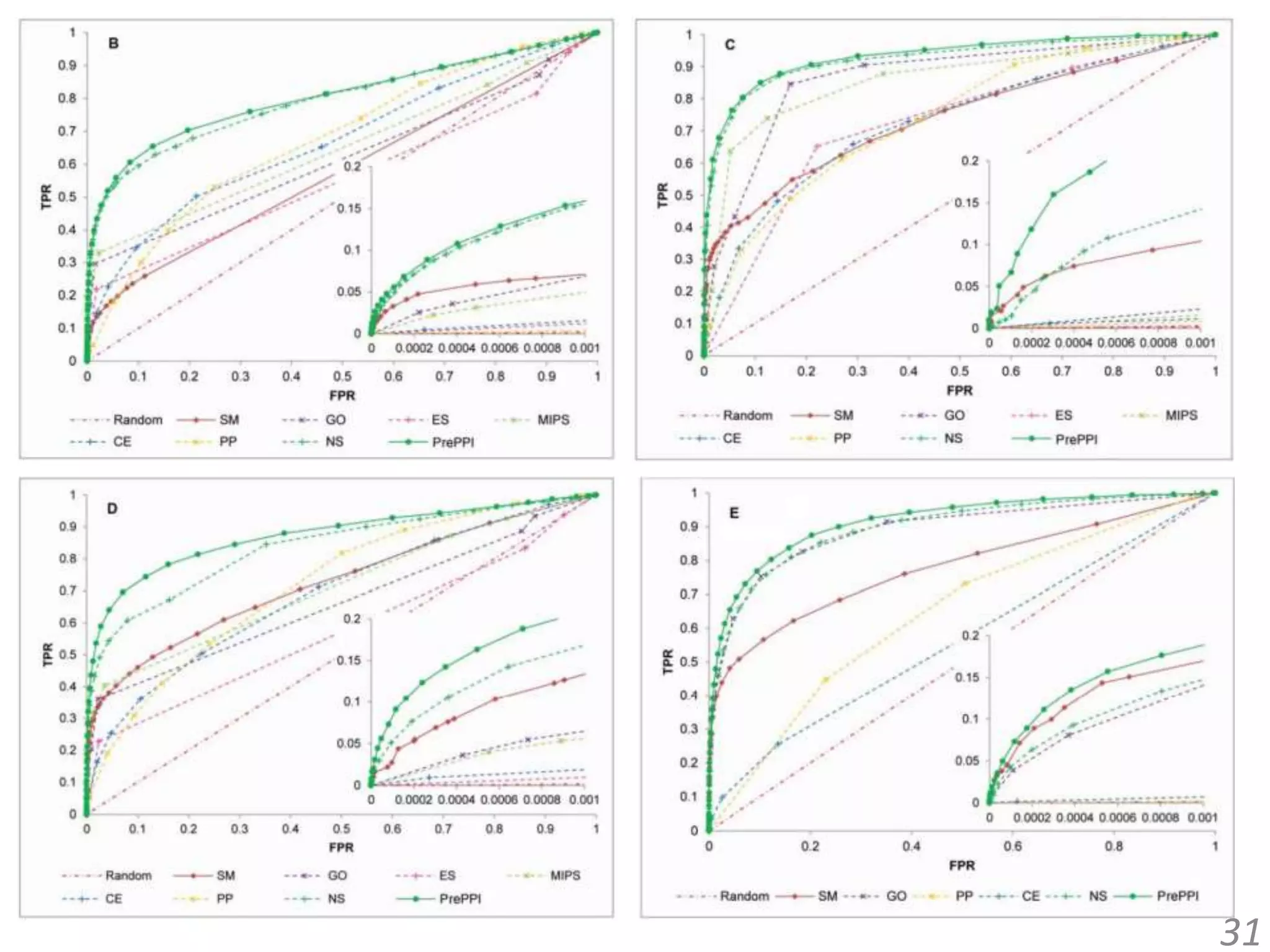
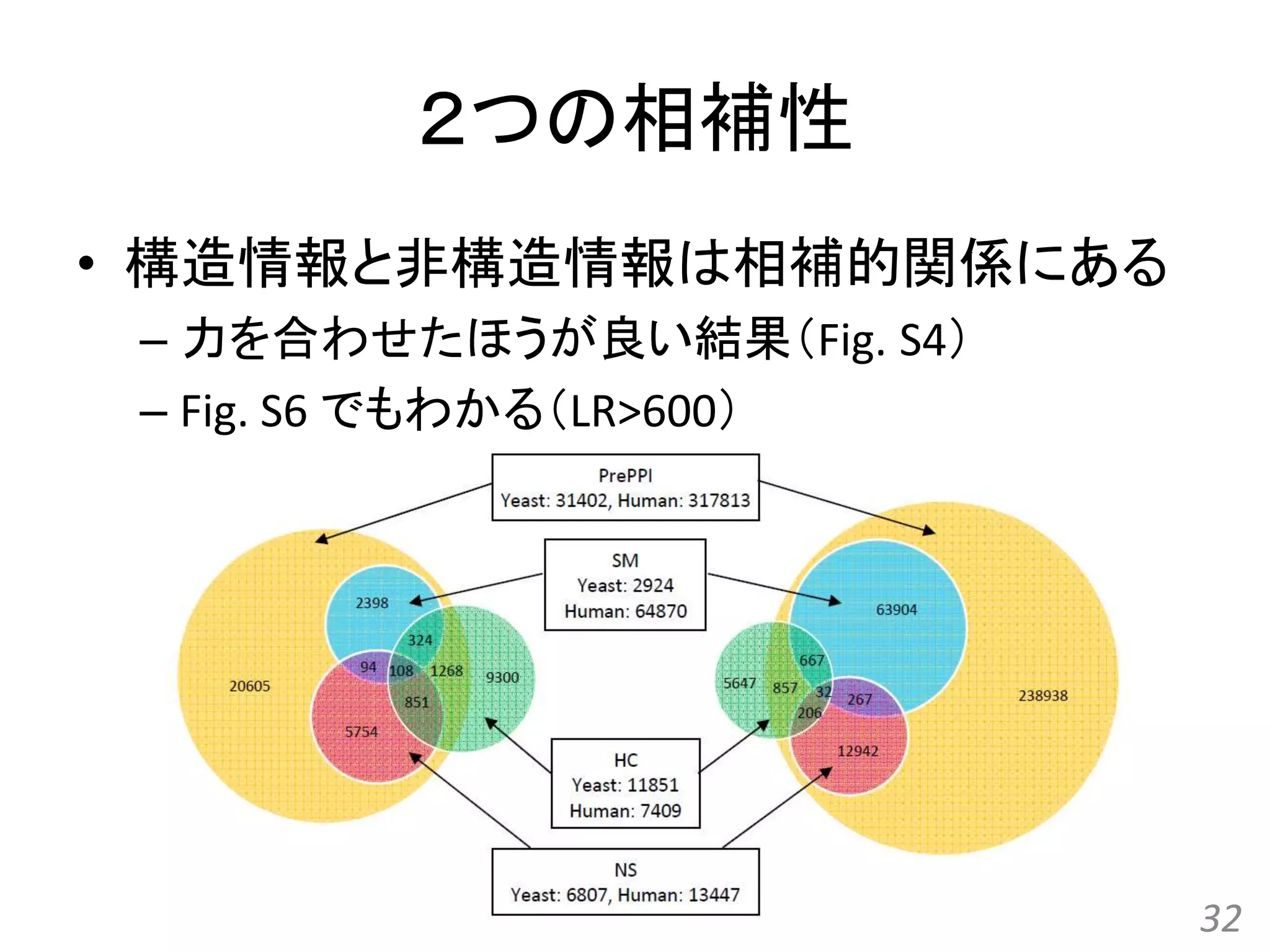
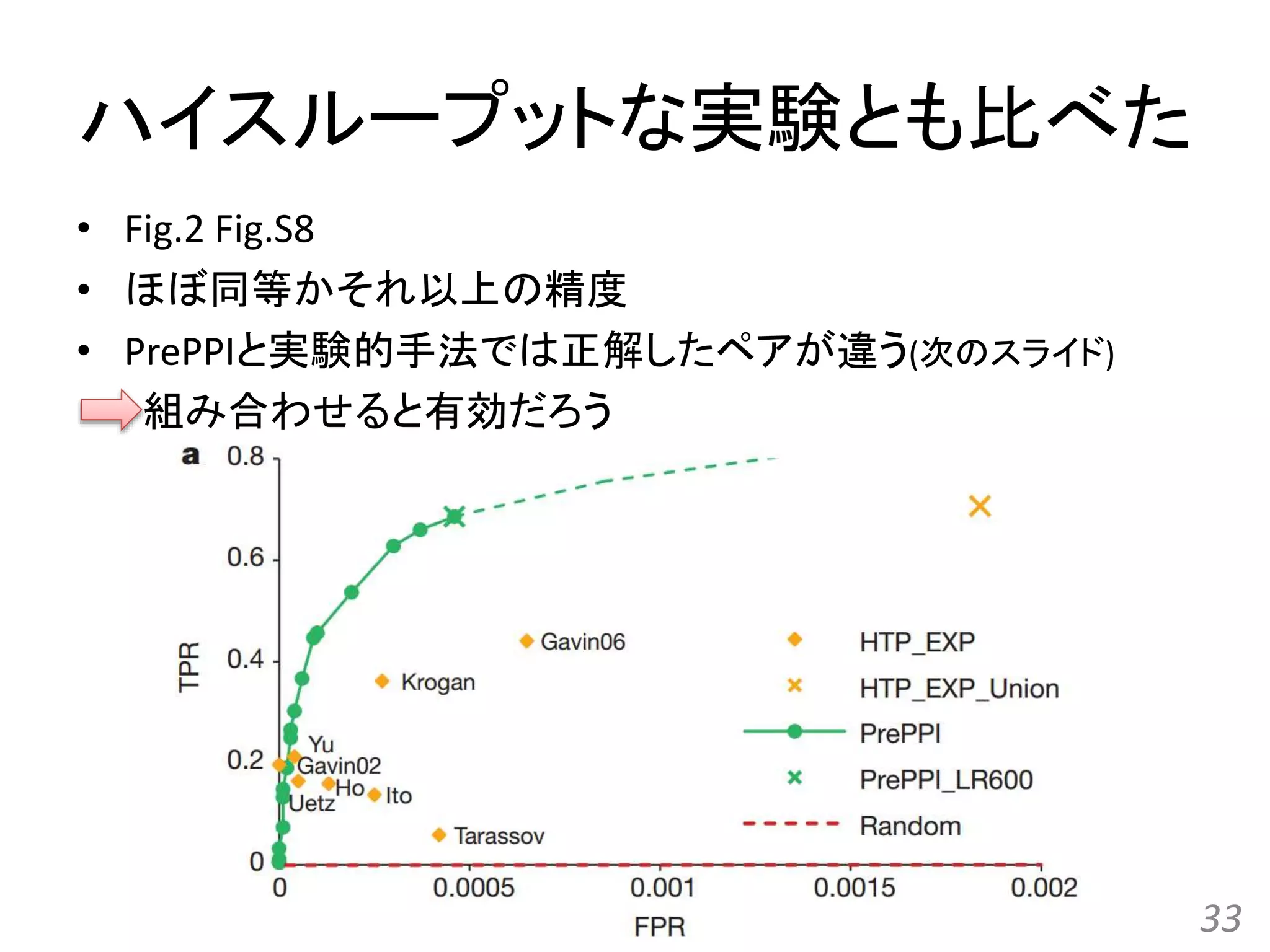
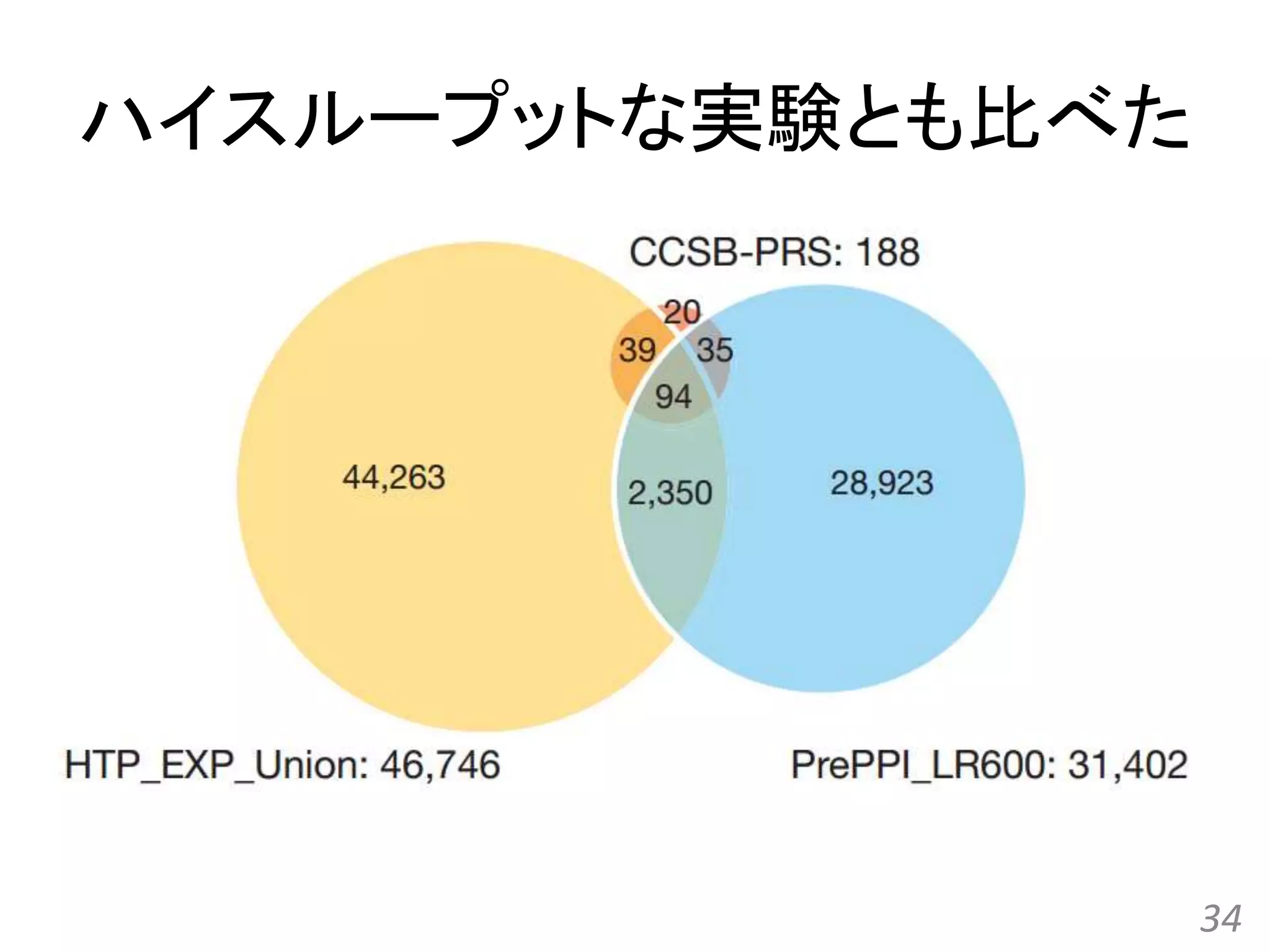
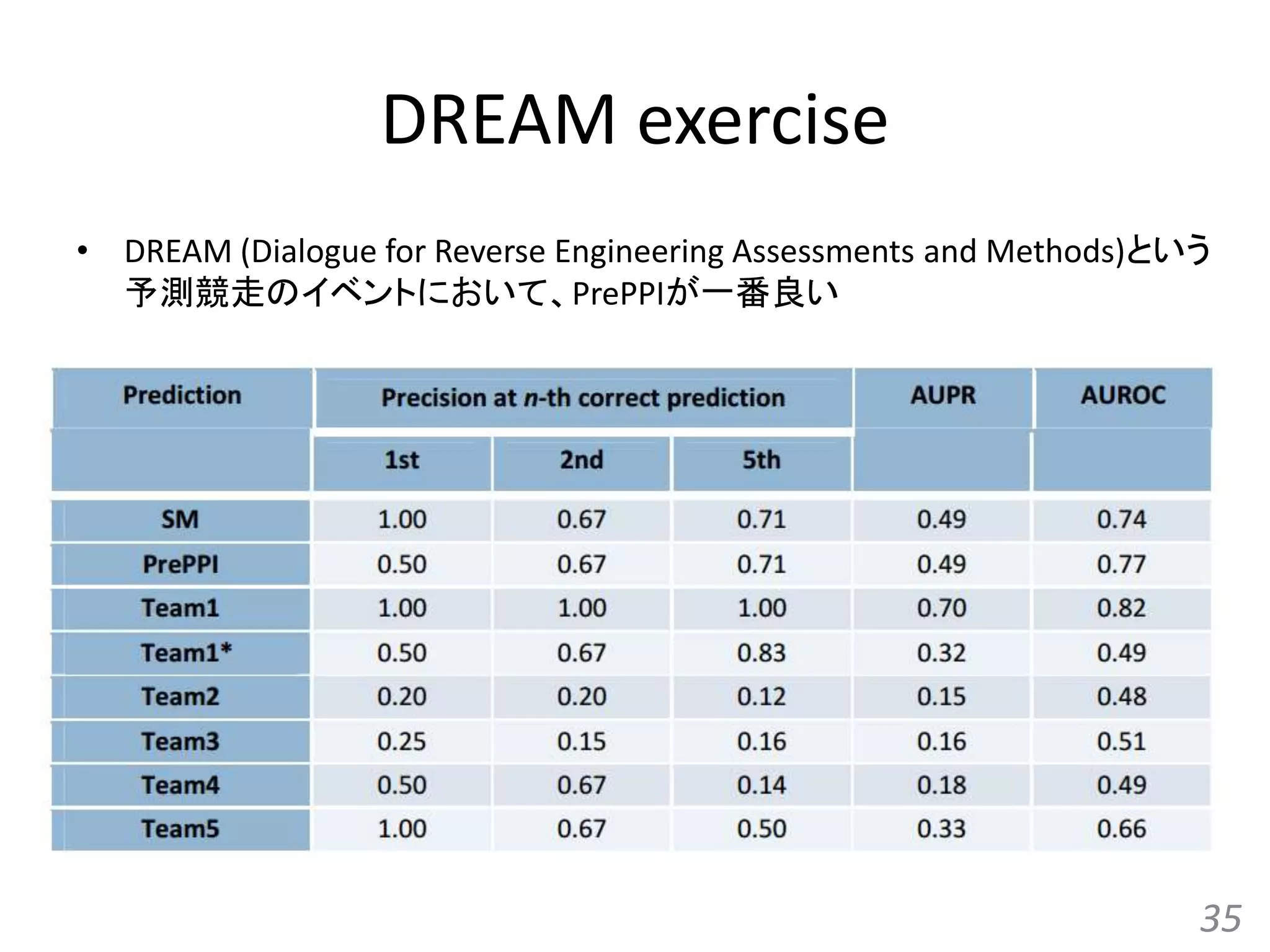
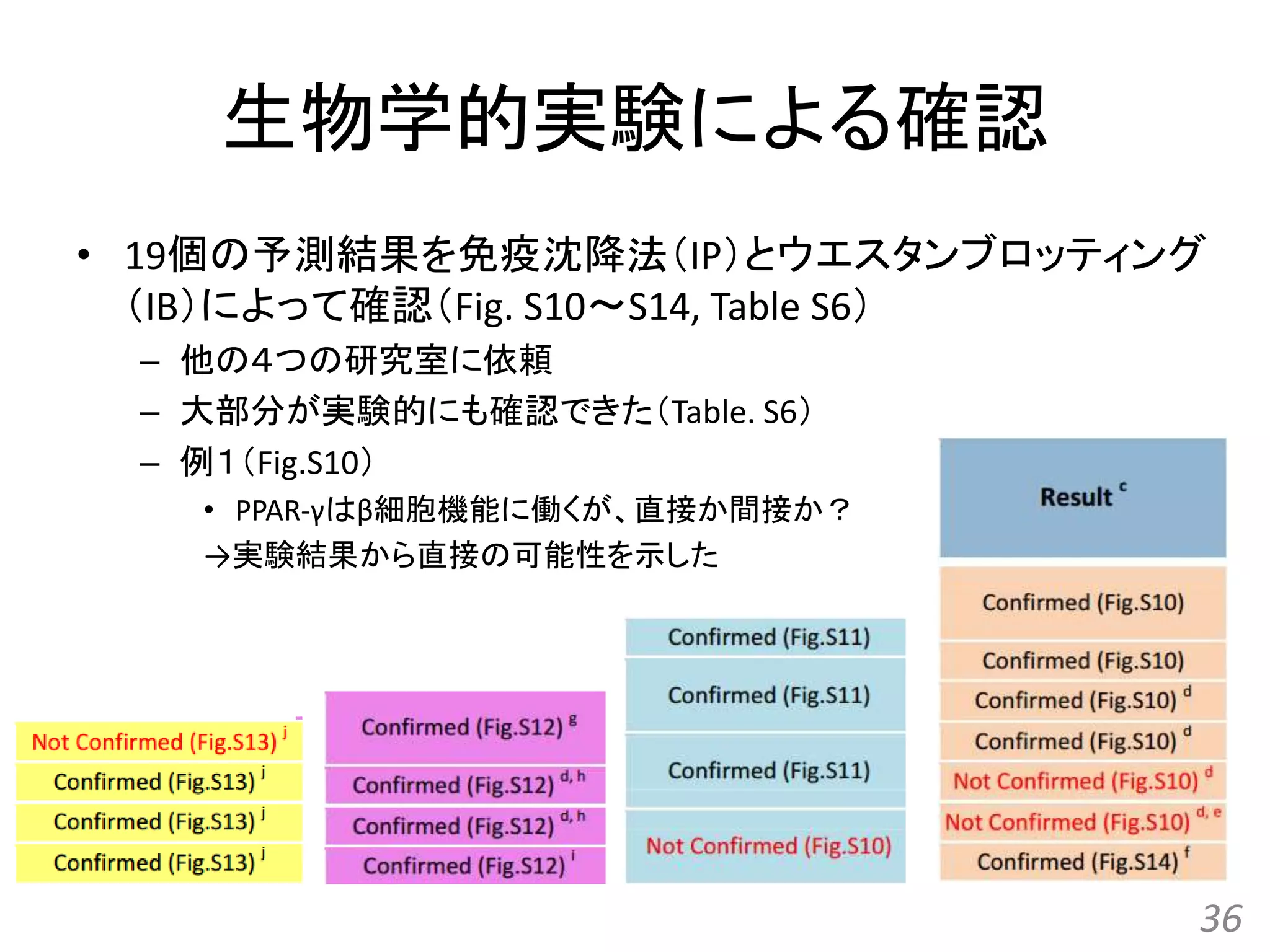



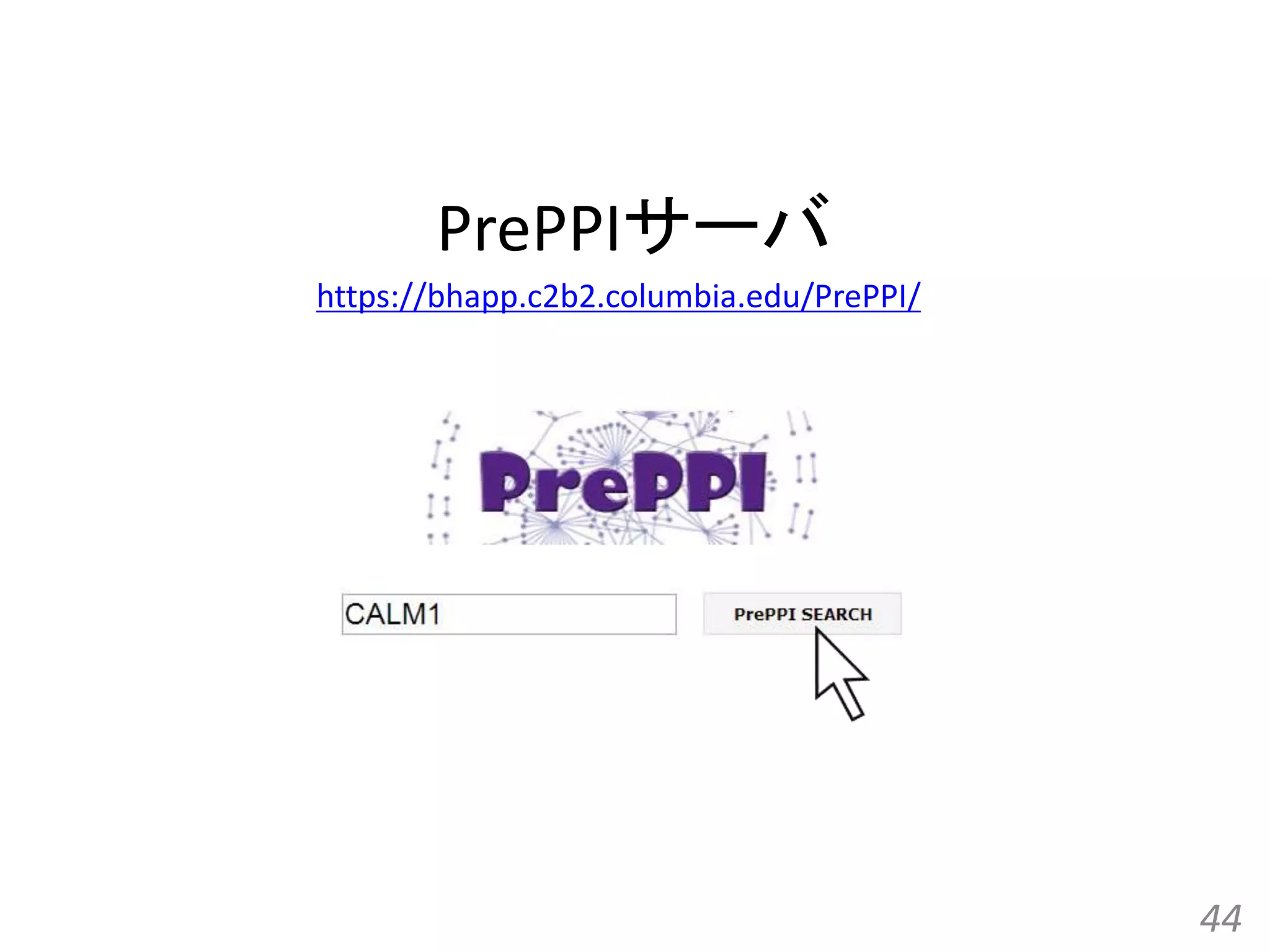
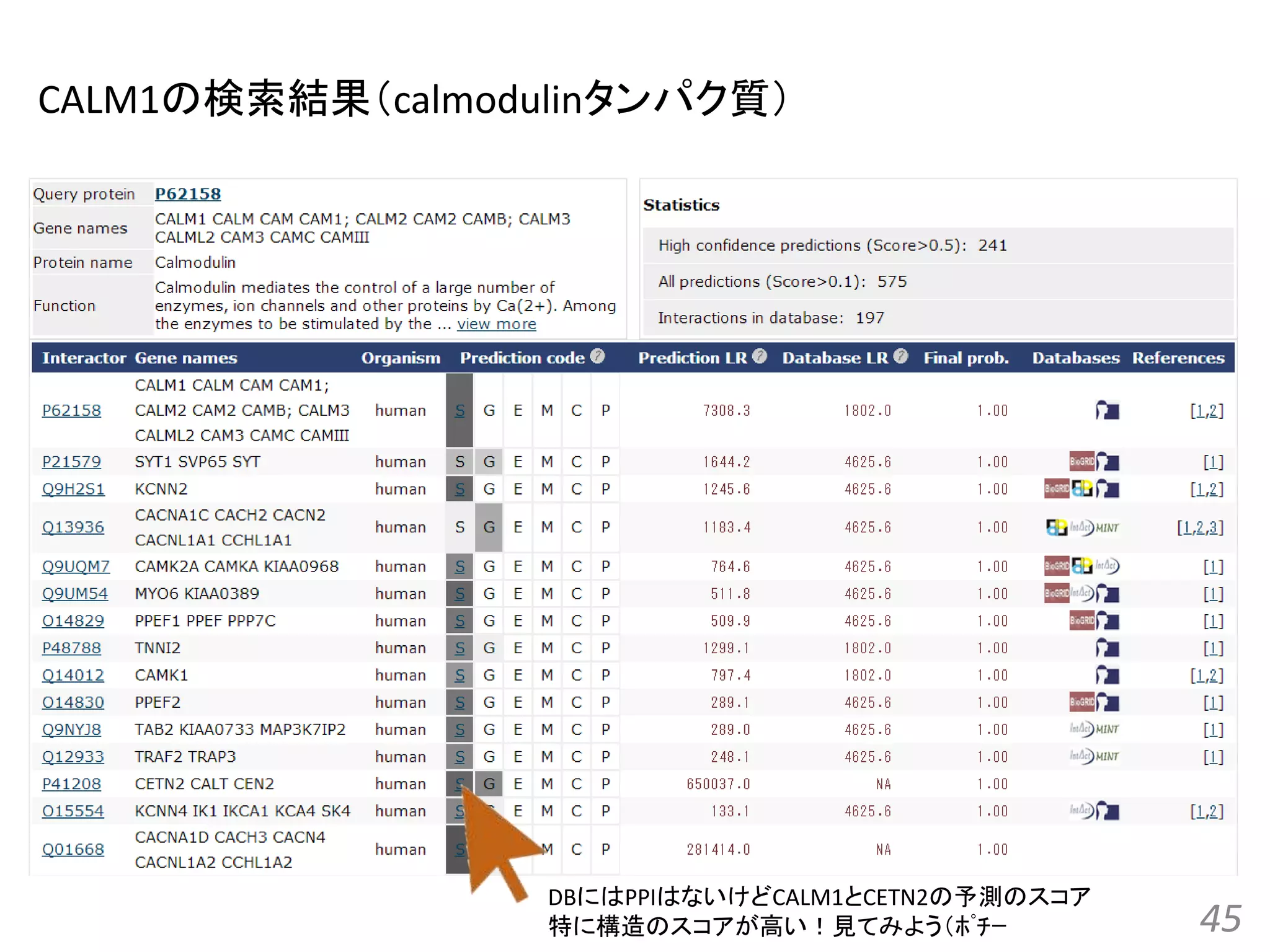











































![[All-in-one2016] ゲノム配列と蛋白質立体構造の統合的検索とモデリング](https://cdn.slidesharecdn.com/ss_thumbnails/kawabata-180109063341-thumbnail.jpg?width=640&height=640&fit=bounds)
![[All-in-one2016] 文献情報を利用したサービスの活用法](https://cdn.slidesharecdn.com/ss_thumbnails/allinone2016kawabata-180109055102-thumbnail.jpg?width=640&height=640&fit=bounds)























![学振特別研究員になるために~知っておくべき10のTips~[平成29年度申請版]](https://cdn.slidesharecdn.com/ss_thumbnails/10tips29-160403152412-thumbnail.jpg?width=640&height=640&fit=bounds)
![学振特別研究員になるために~知っておくべき10のTips~[平成28年度申請版]](https://cdn.slidesharecdn.com/ss_thumbnails/random-150226210930-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



