Download as PDF, PPTX






































































The document provides a comprehensive overview of database management systems (DBMS), discussing key concepts such as types of databases, data models, and the differences between file management systems and DBMS. It highlights the importance of data integrity, operations, and various models including hierarchical, network, and relational models. Additionally, it addresses the applications, advantages, and disadvantages of DBMS, as well as data warehousing and its significance in integrating and analyzing data for decision-making.
Overview of the course unit on Database Management Systems including key topics such as data types, DBMS basics, advantages, and applications.
Defining data, its types (primary, secondary, qualitative, quantitative) and characteristics of a database, emphasizing organization and relationships.
Common database operations like insertion, selection, updation, and deletion, along with an introduction to database models and their components.
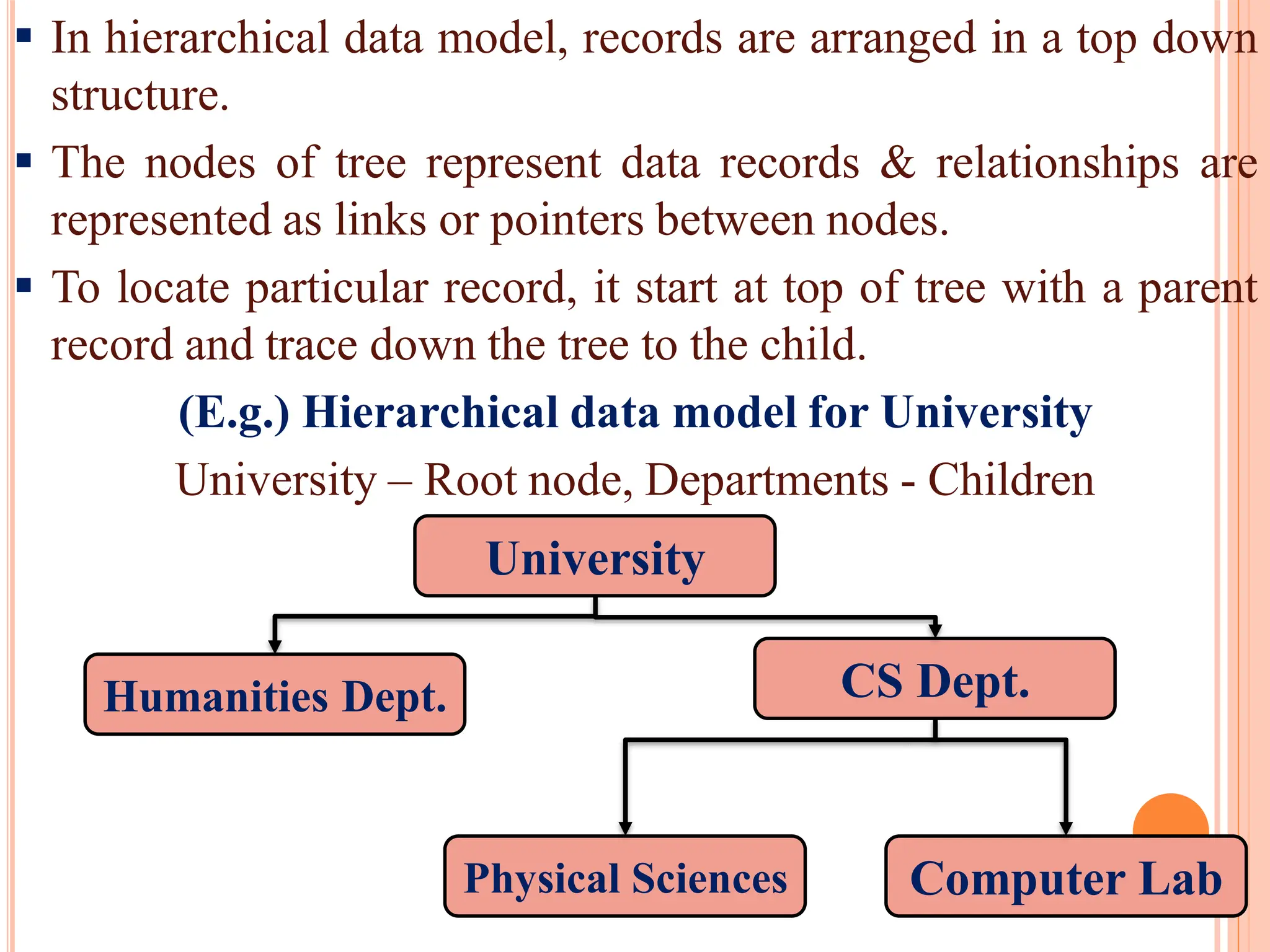
Importance and characteristics of data models, including their roles in structuring, relationships, and integrity rules within databases.
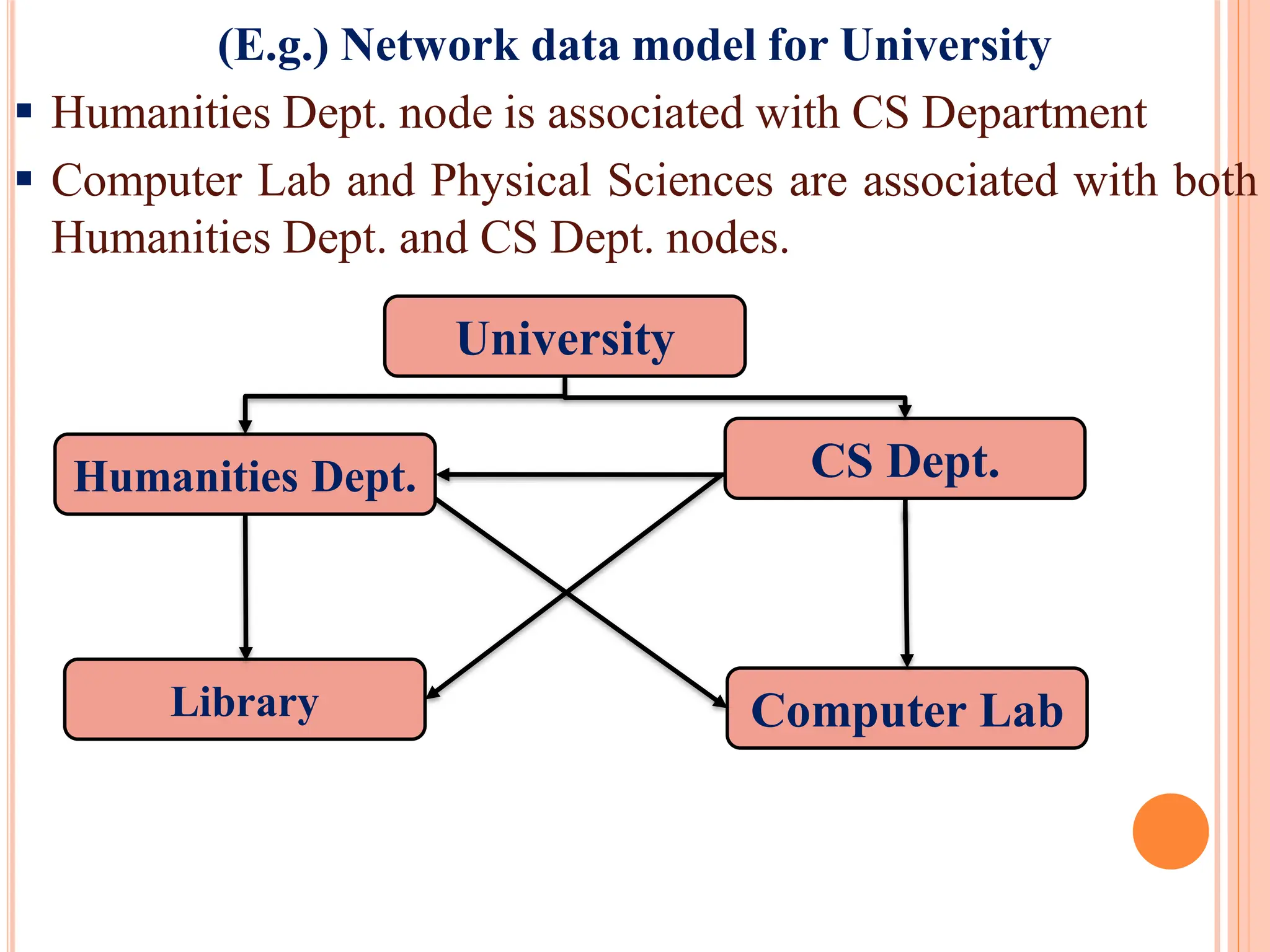
Transition from hierarchical models to network models, explaining their structures and examples, emphasizing relationships between nodes.
Advantages and drawbacks of the network model compared to hierarchical models, including complexity and operational issues.
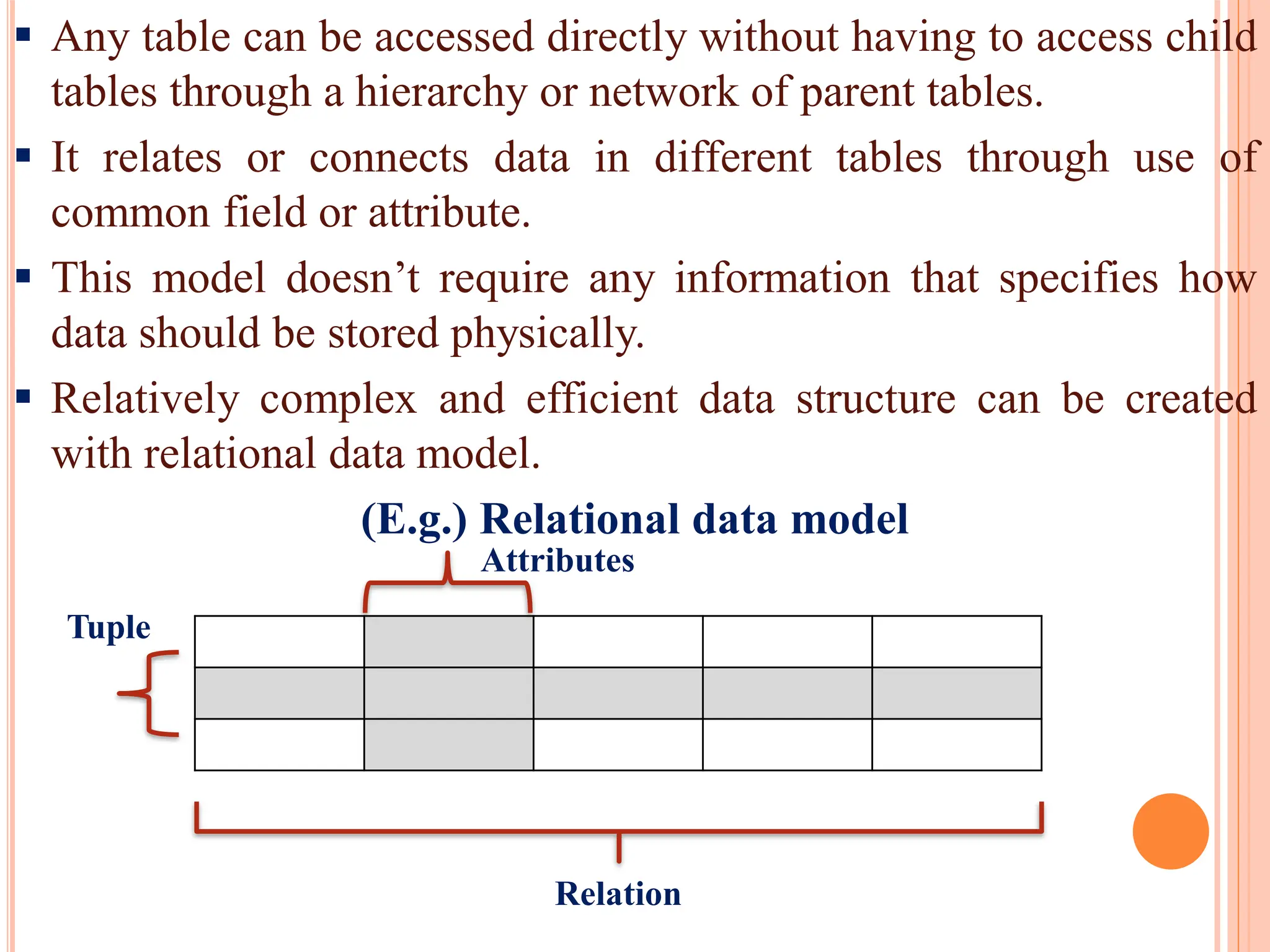
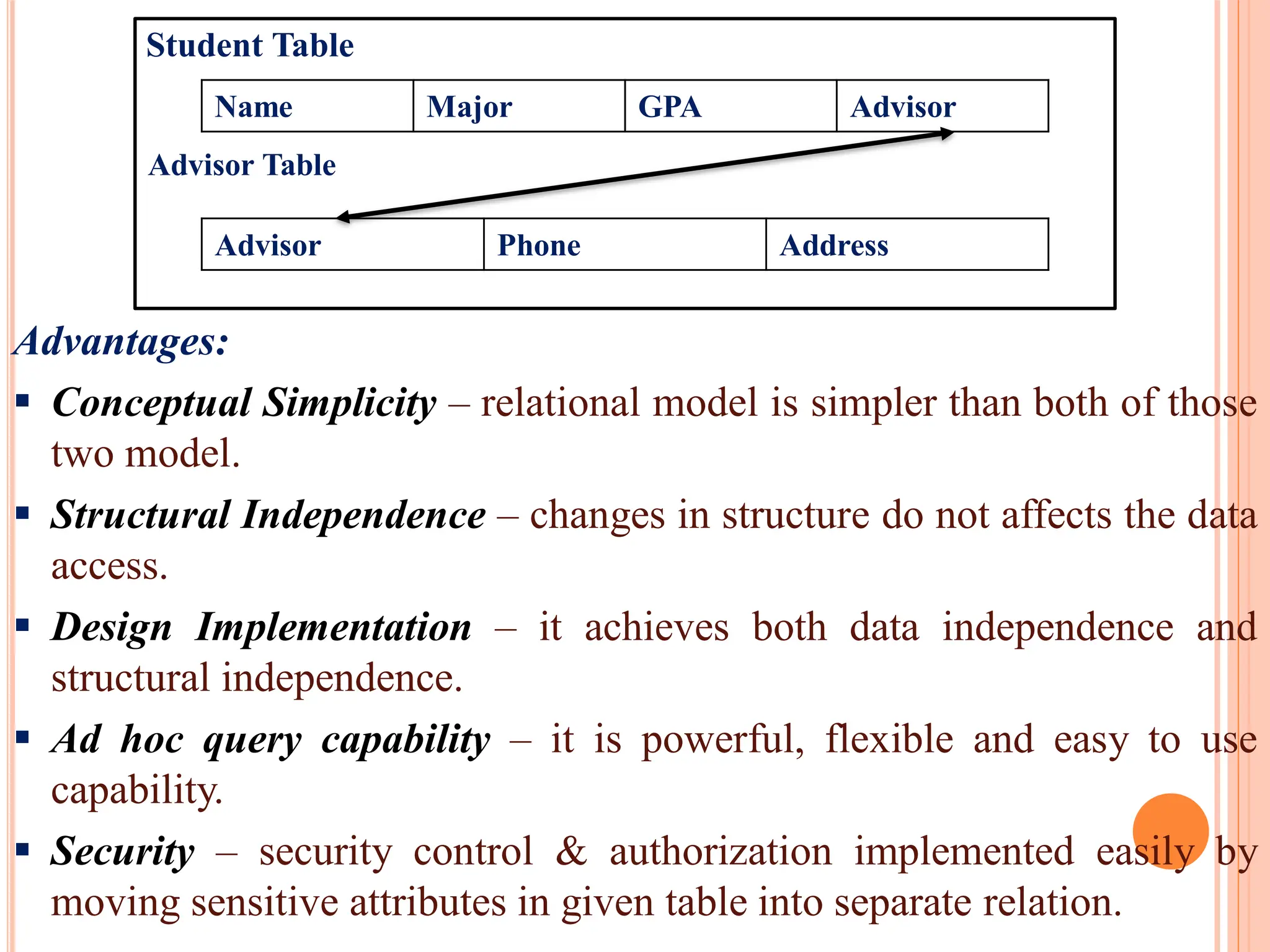
Introduction to the relational model, its structure of rows and columns, and advantages like simplicity, independence, and ad hoc querying.
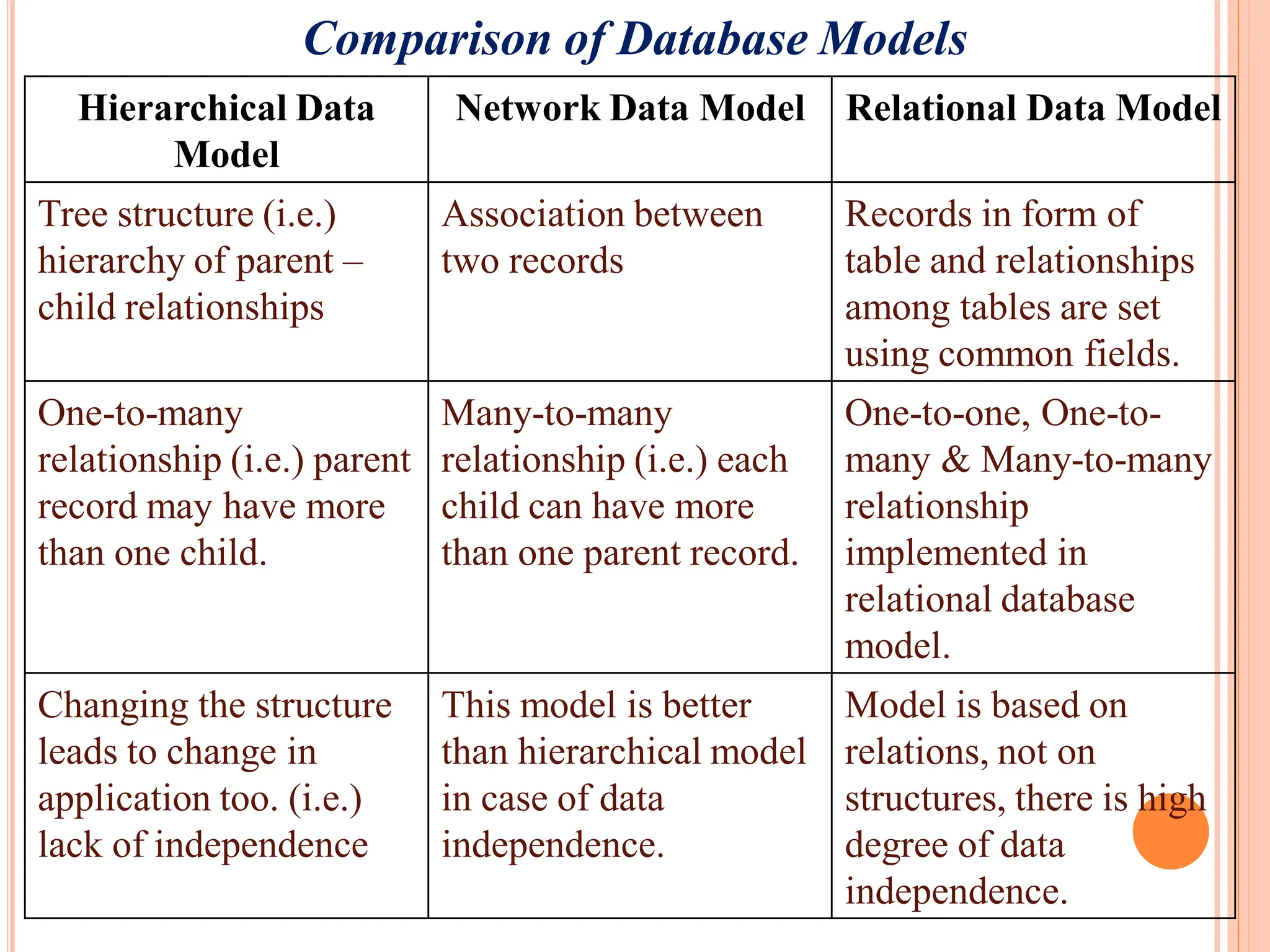
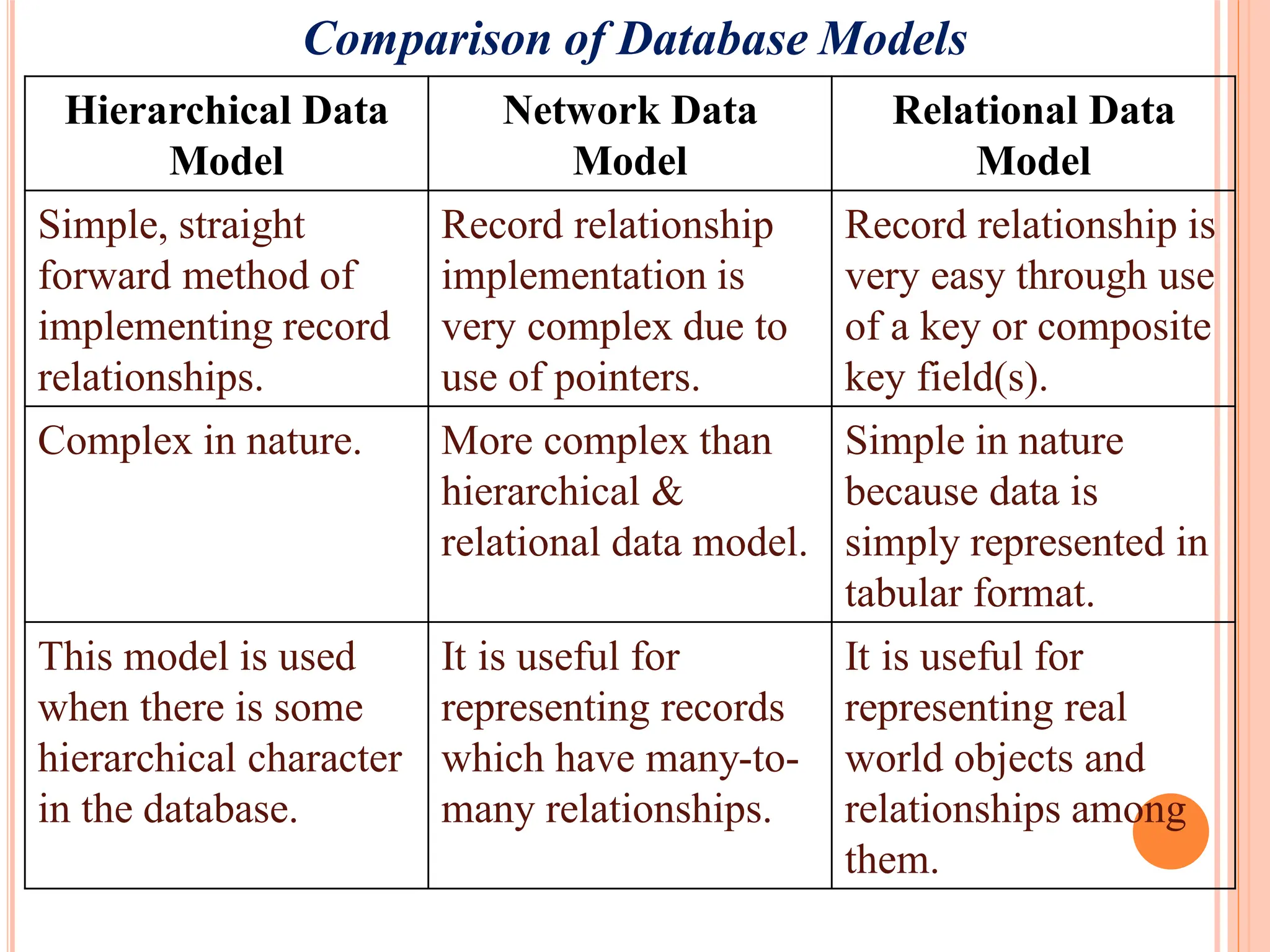
Comparison of hierarchical, network, and relational database models focusing on structure, relationships, ease of use, and challenges.
Definition and functions of DBMS including data definition, retrieval, updating, and user administration for efficient data management.
Key features of DBMS such as data organization, access, security, and backup capabilities supporting complex data relationships.
Comparison of File Management Systems with DBMS in terms of efficiency, data redundancy, cost, and security solutions.
Diverse applications of DBMS in sectors like banking, finance, airlines, and its advantages like decision support and data consistency.
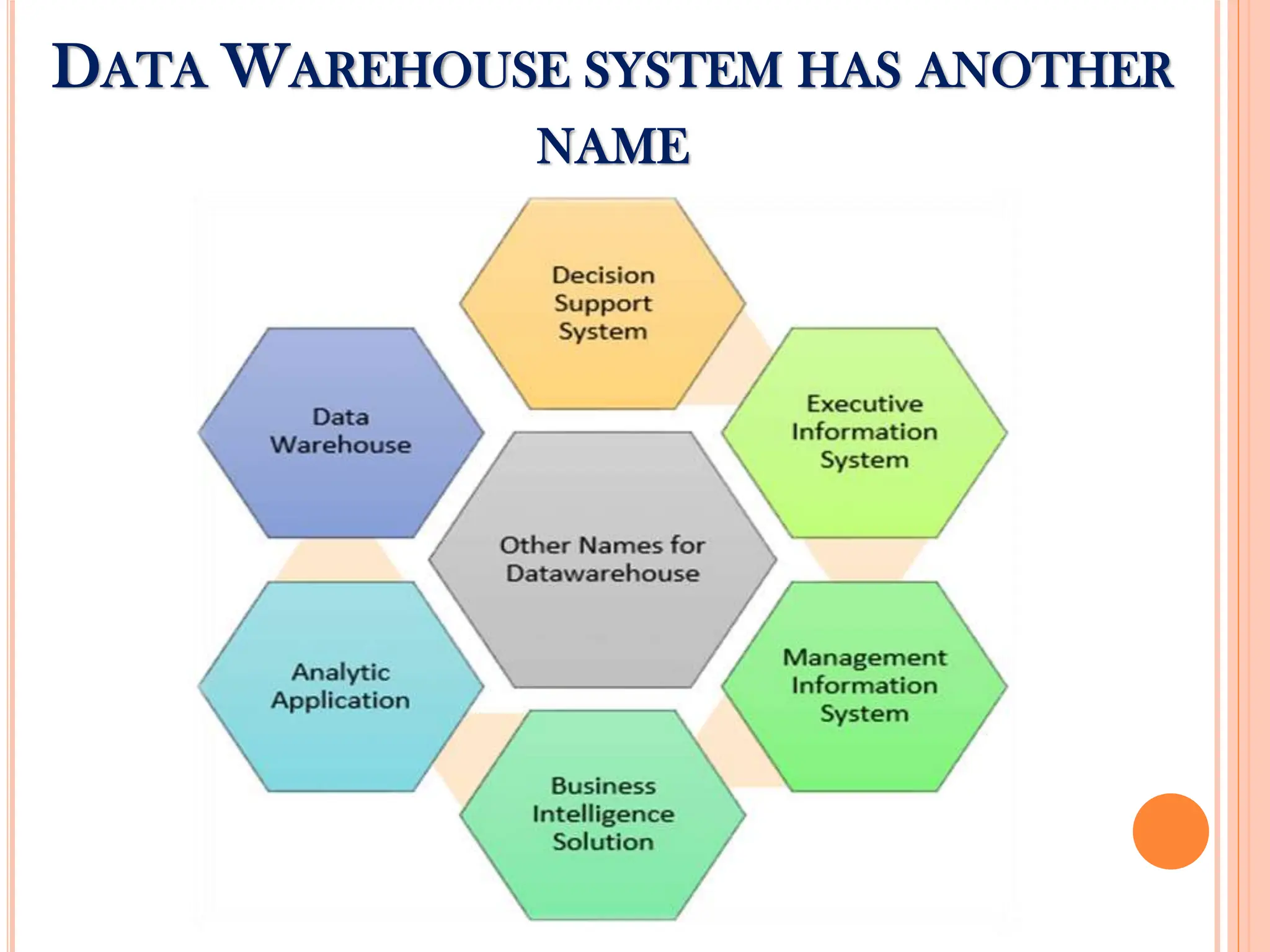
Introduction to data warehousing concepts and purpose, focusing on integration of scattered data for effective business strategies.
Key characteristics of data warehouses like subject-oriented and integrated data storage, along with examples from various industries.
Definitions and working principles of data warehouses as comprehensive data stores and their impact on decision making processes.
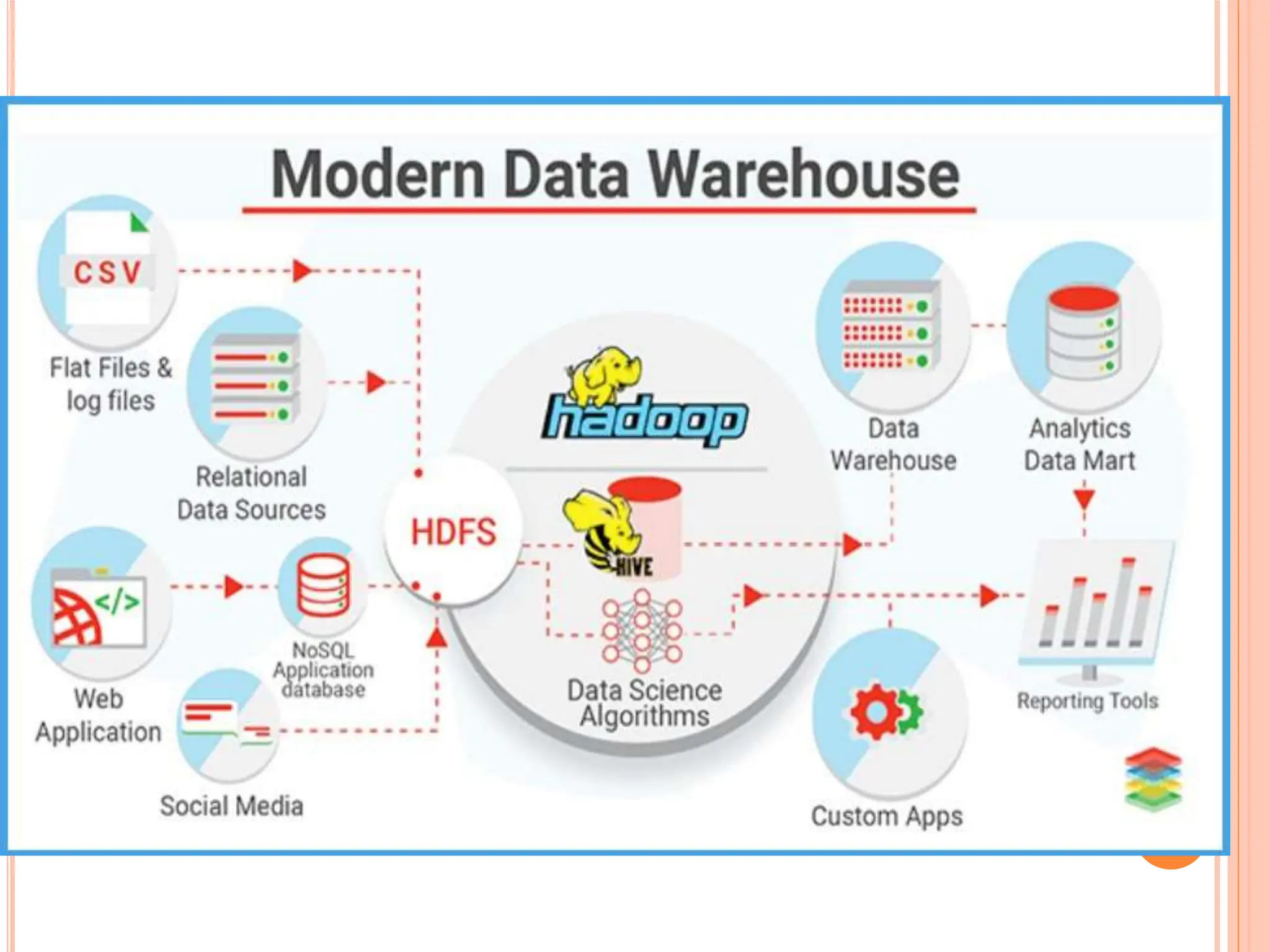
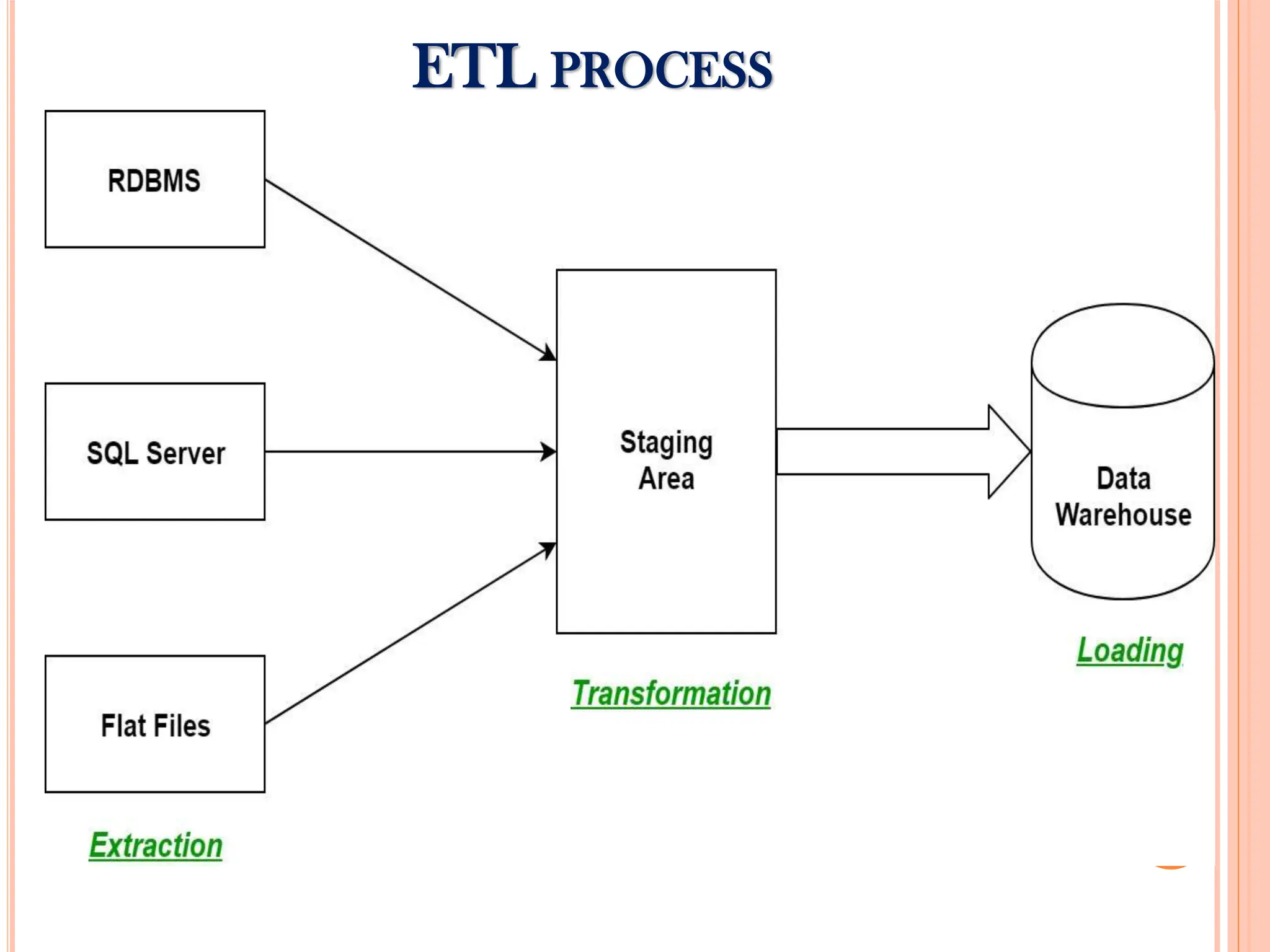
Different types of data warehouses (EDW, ODS, Data Mart) and core components, including ETL processes for data management.
Detailed steps of the ETL process: extraction, transformation, and loading data into warehouses, alongside popular tools.
Benefits for end-users including consistency and improved decision-making, but also highlights potential disadvantages.
Overview of data mining as knowledge extraction from databases, its algorithms, advantages, and applications in different sectors.
Comparison between data mining and warehousing in terms of processes, techniques, and responsibilities in data management.
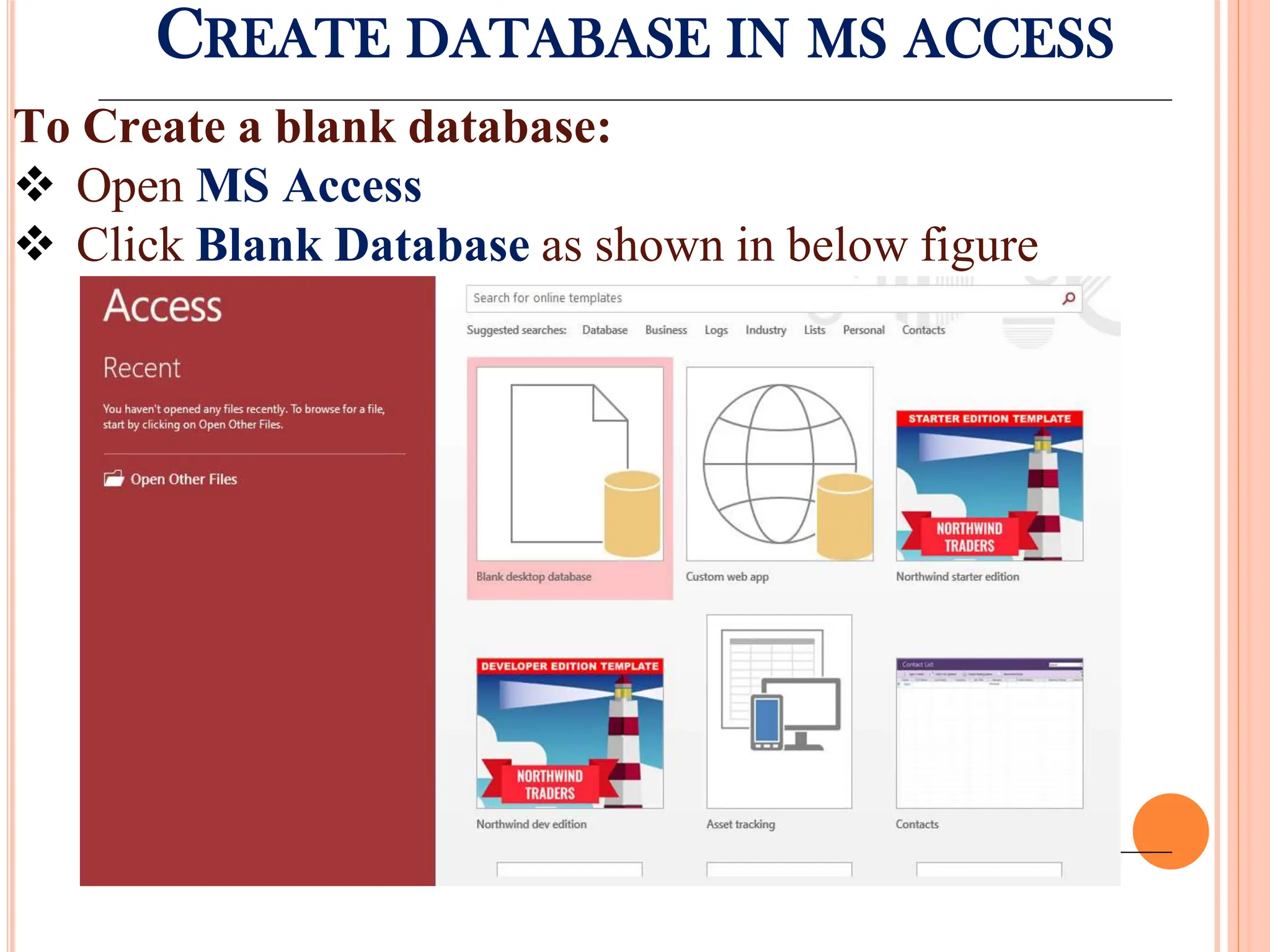
Overview of Microsoft Access as a DBMS tool for organizing and managing data with its major components and functionalities.
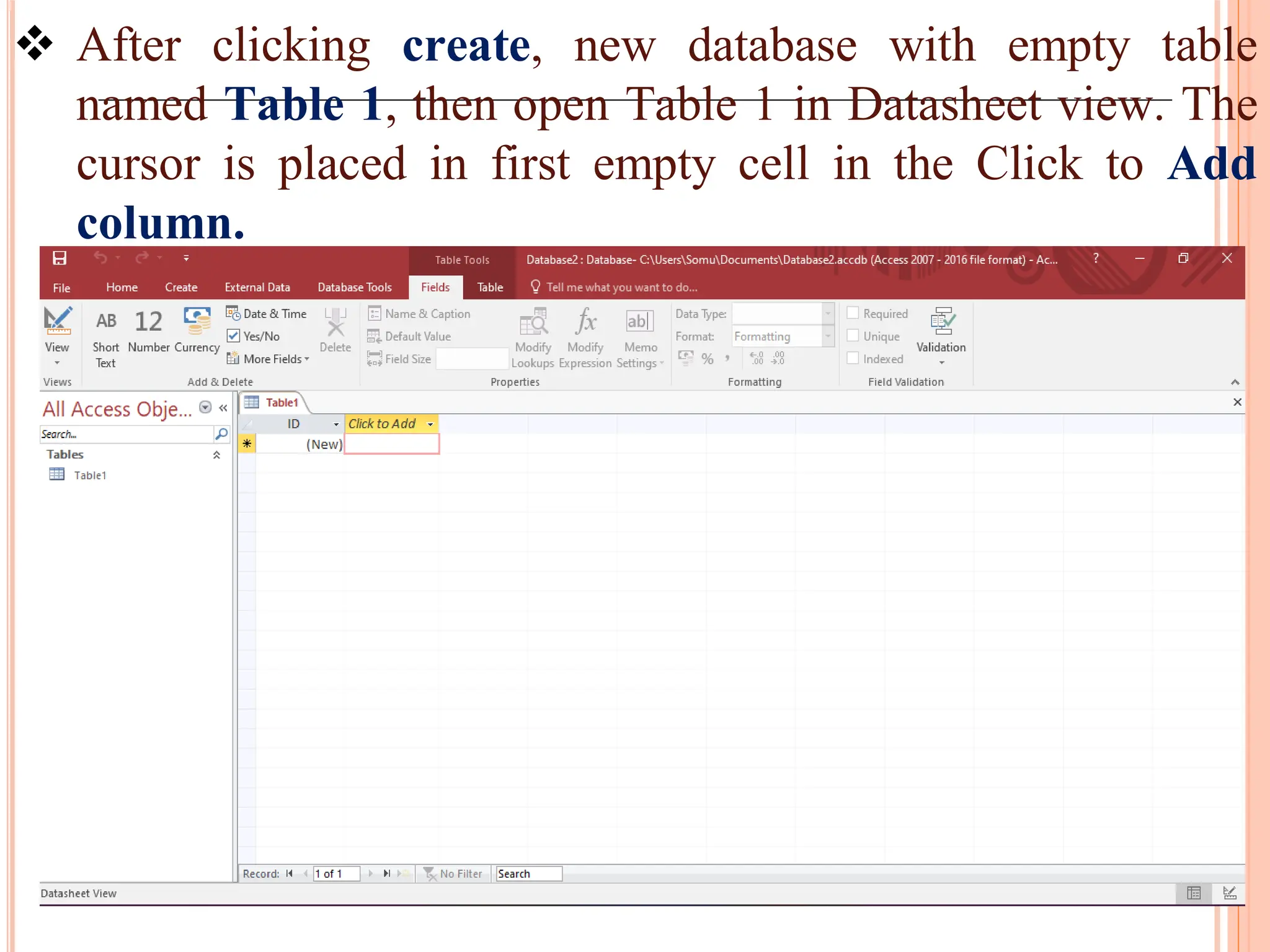
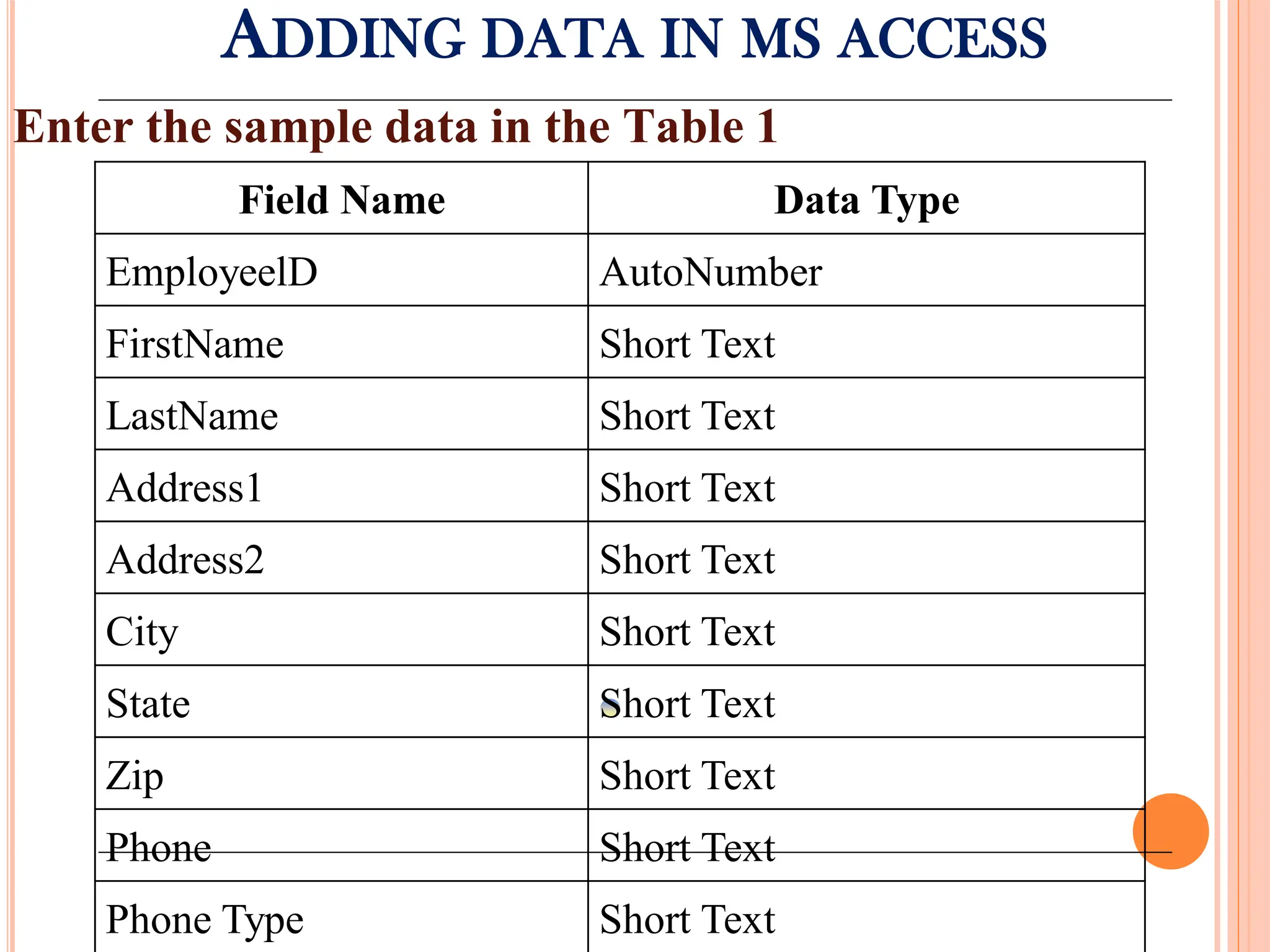
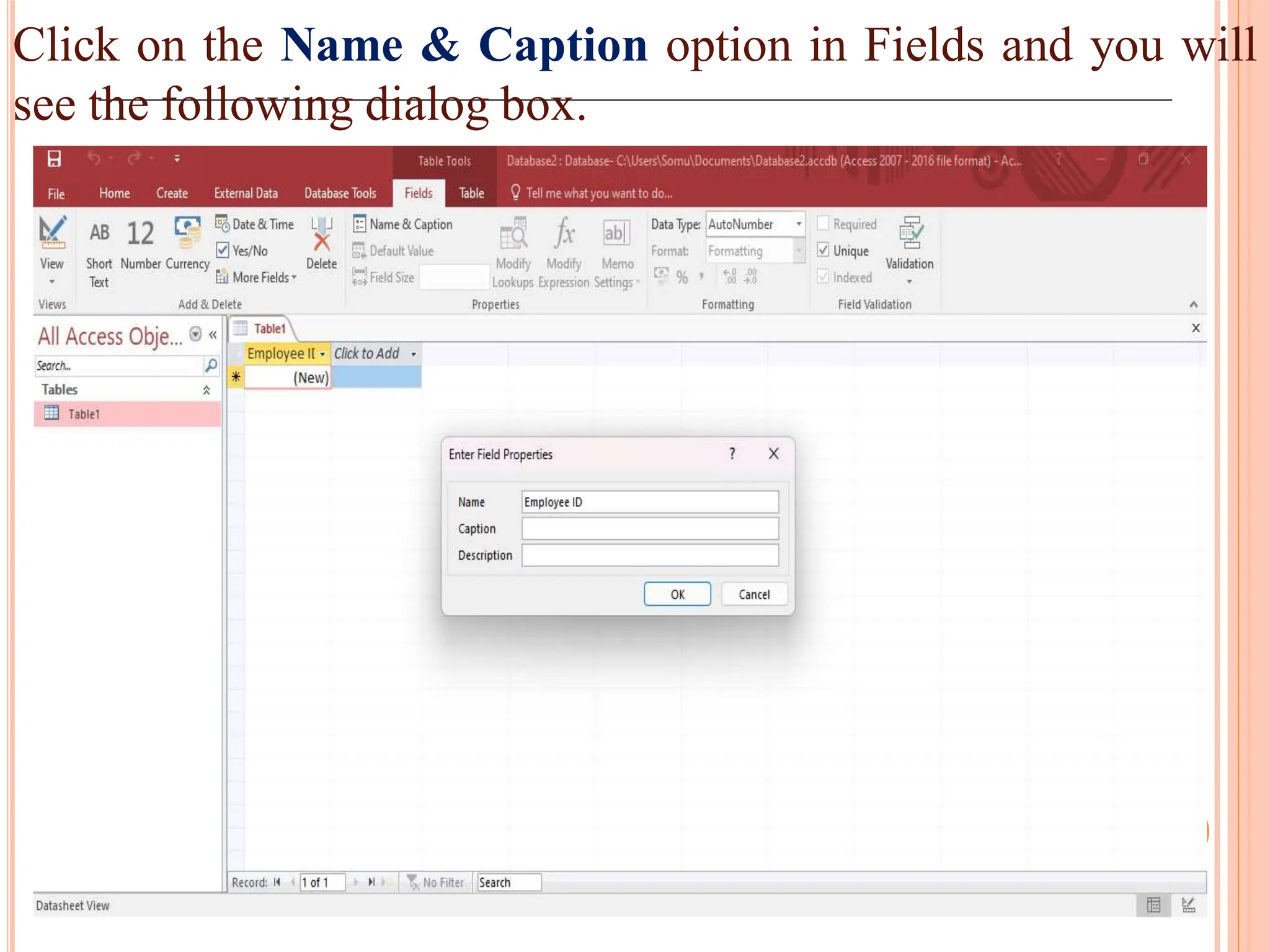
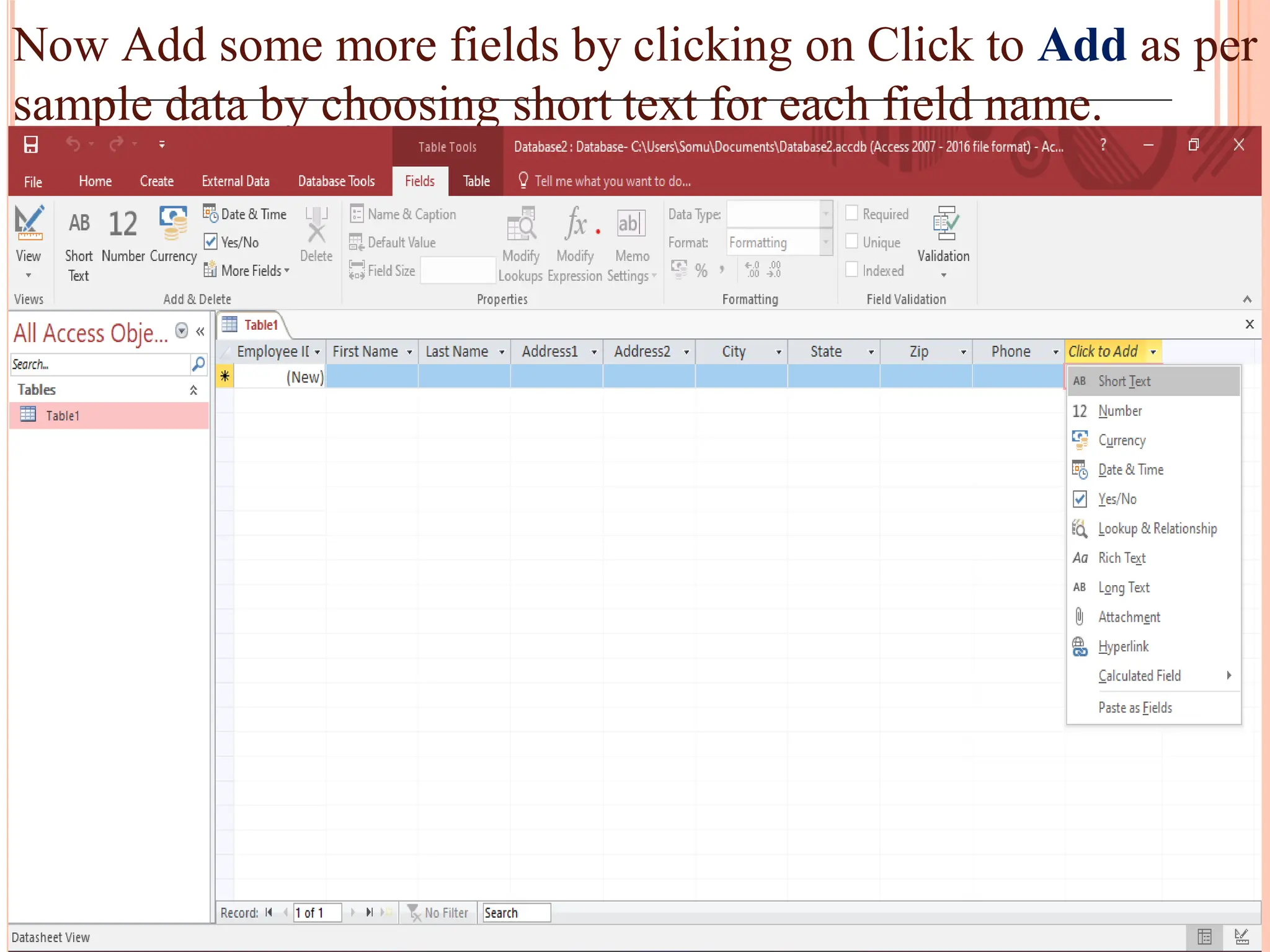
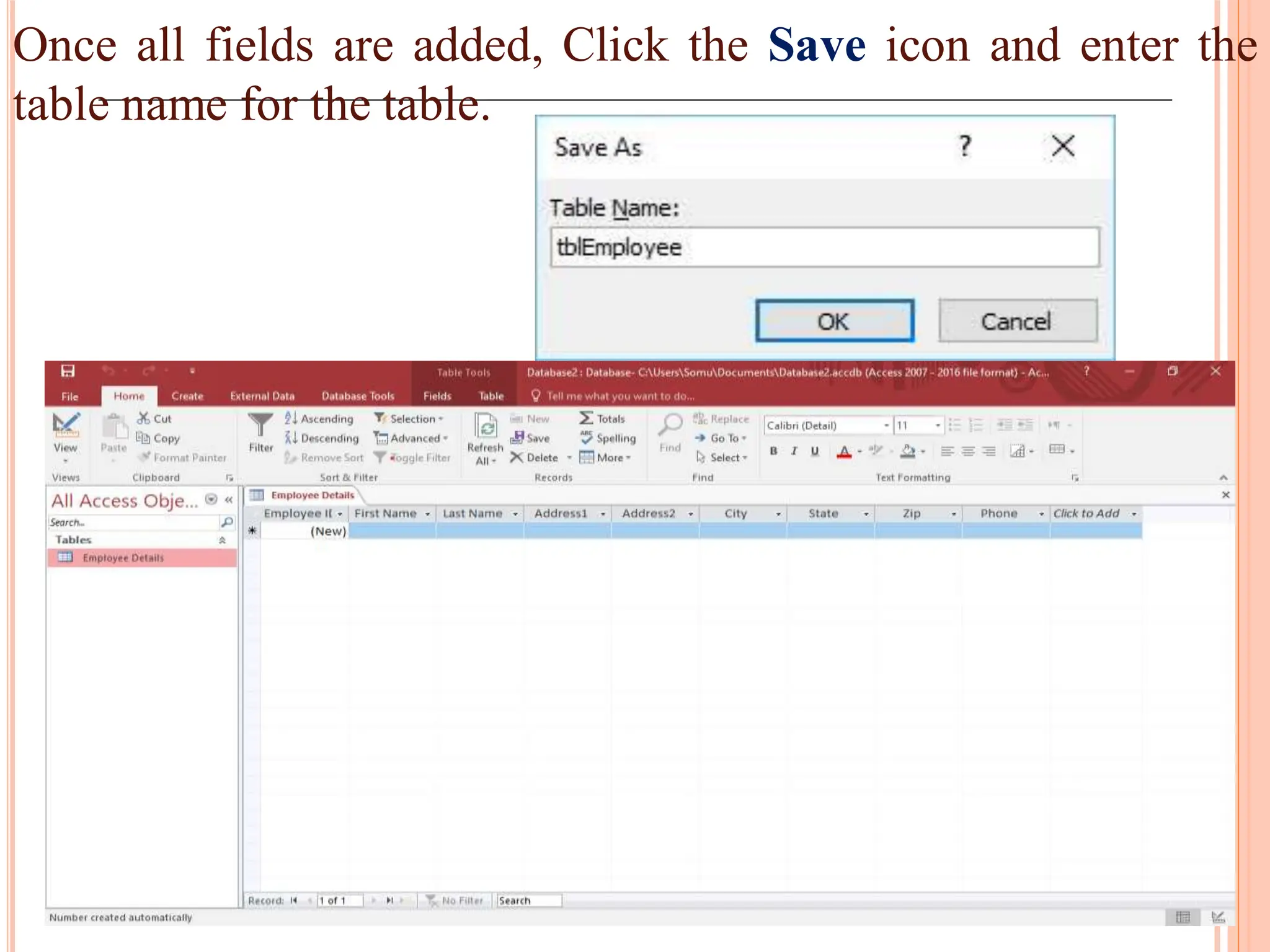
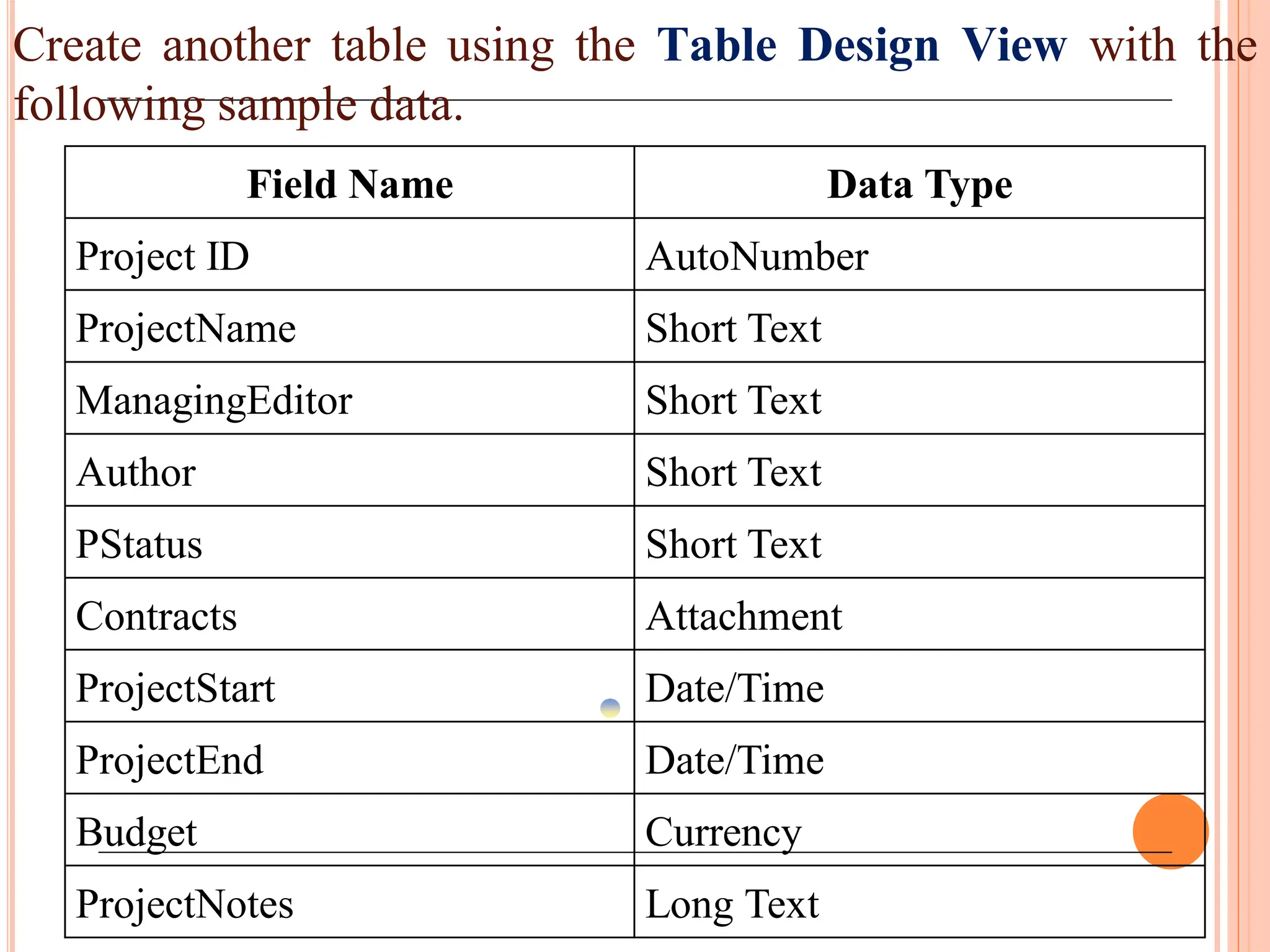
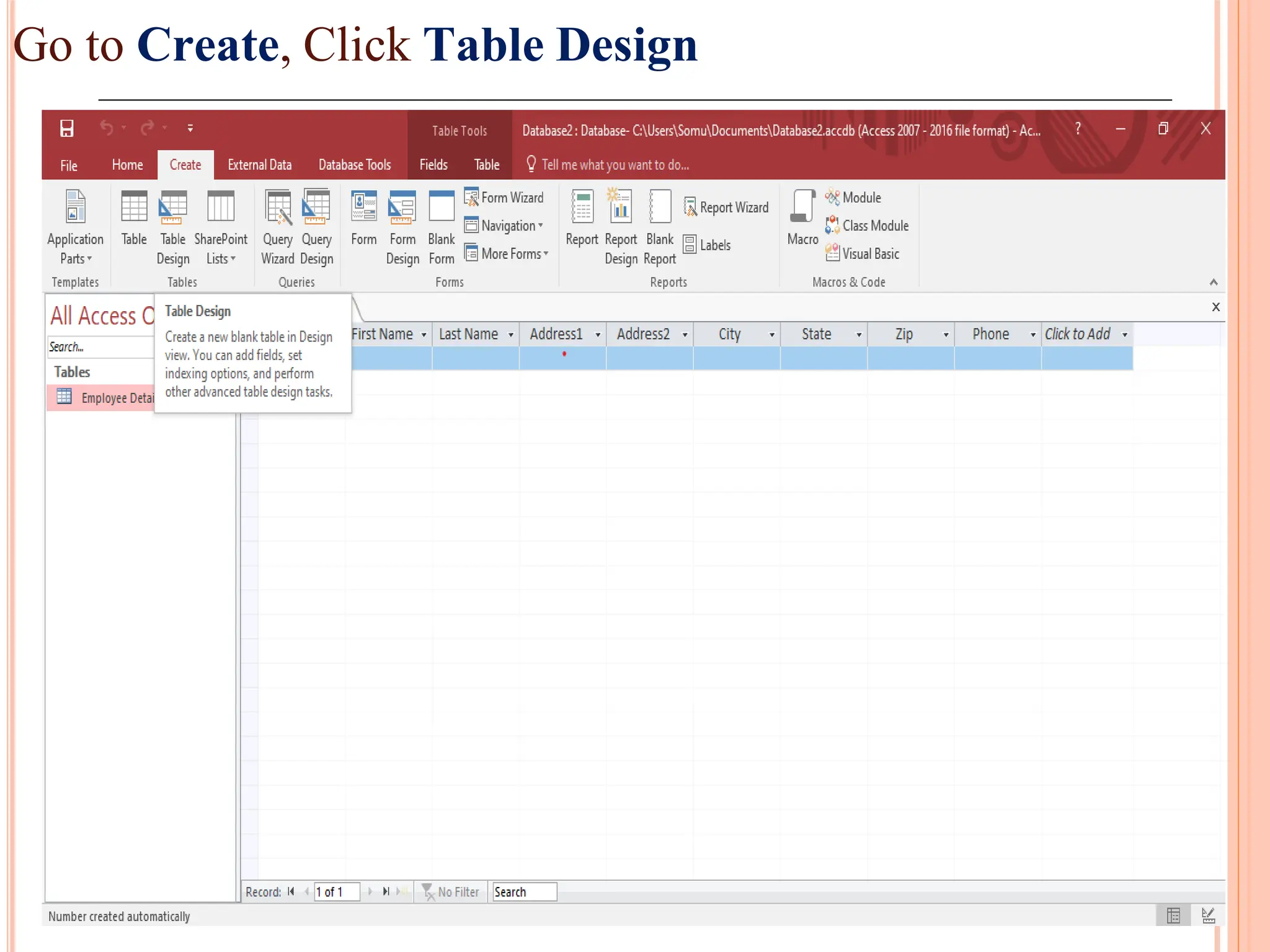
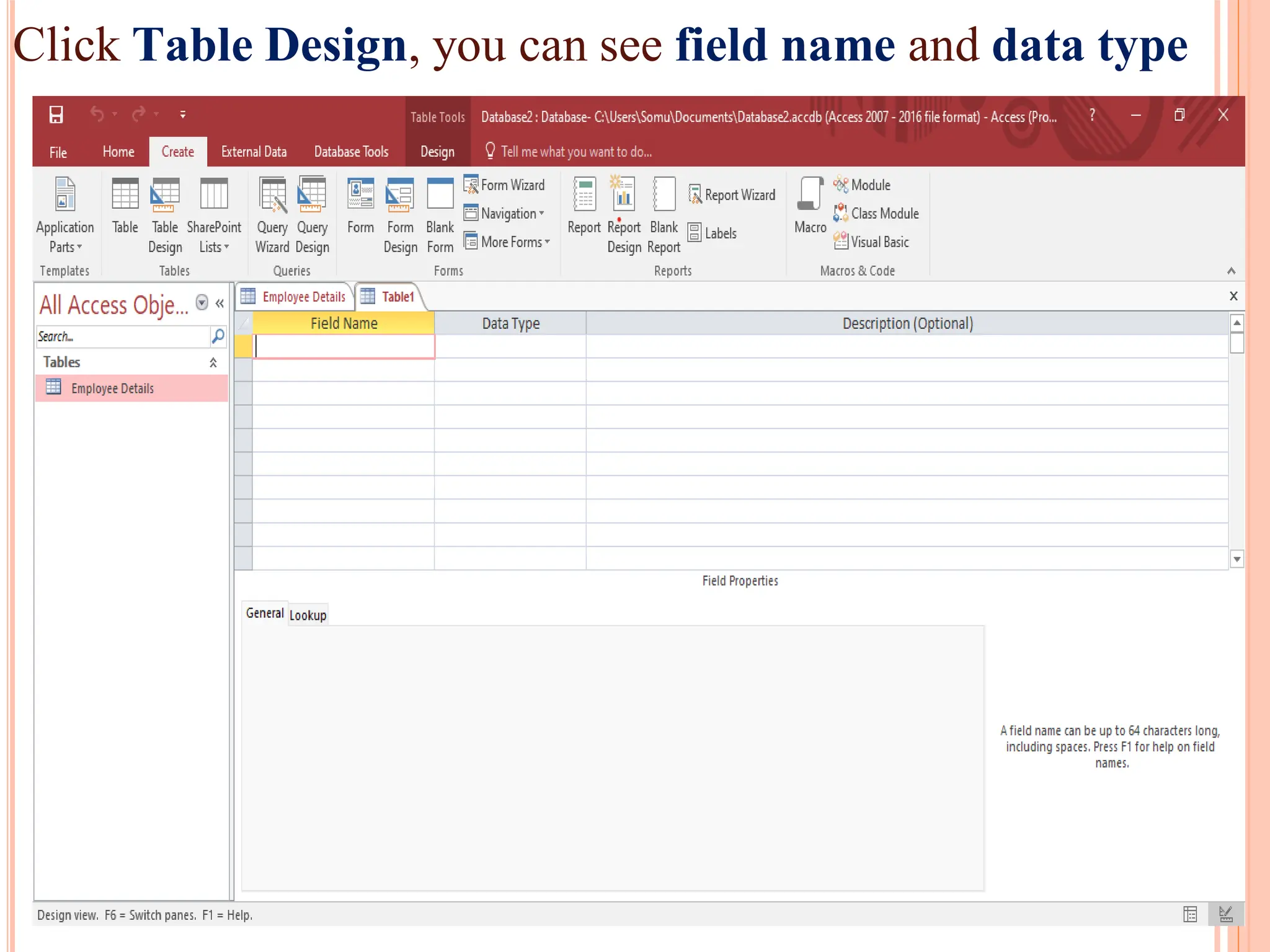
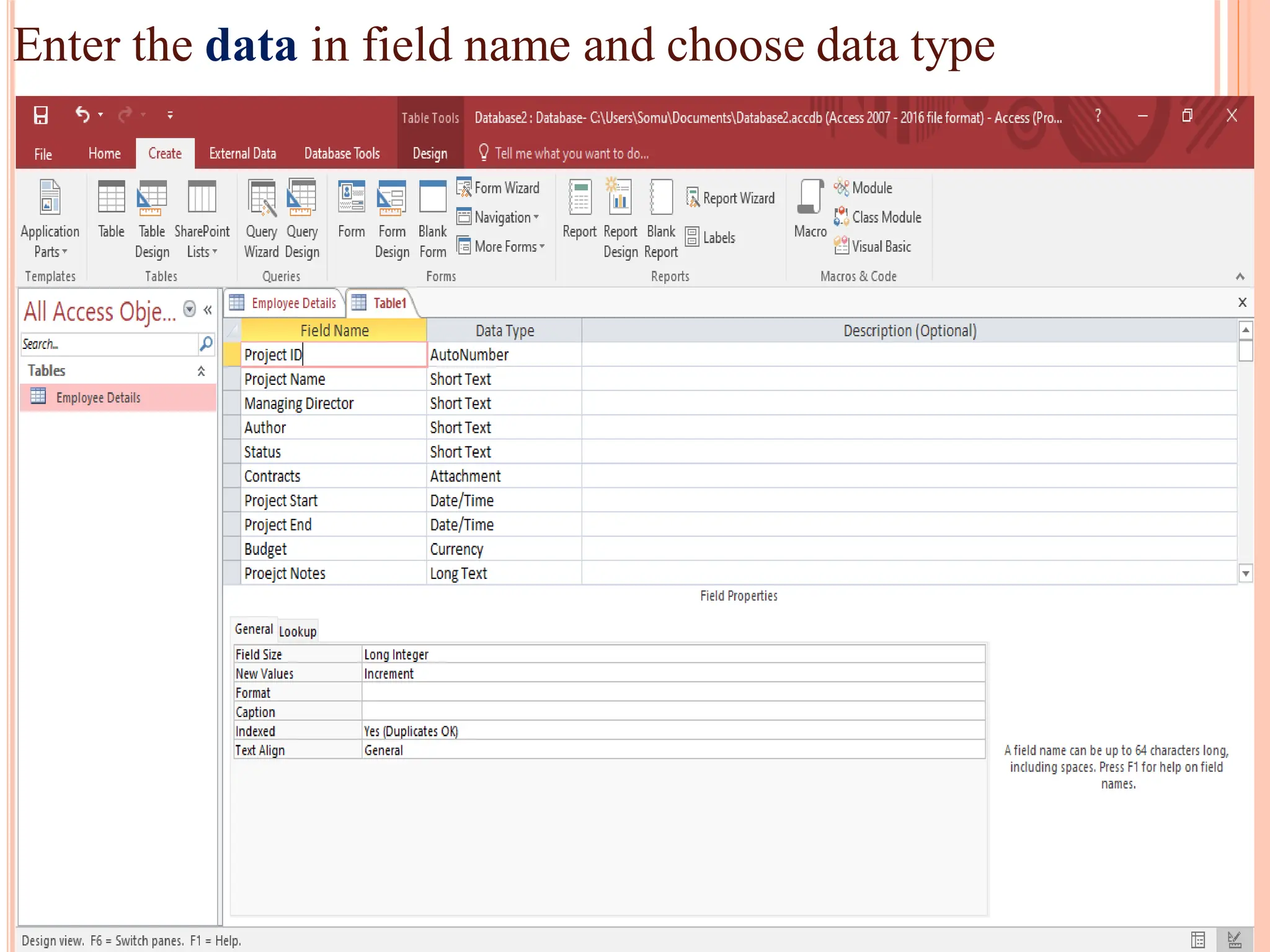
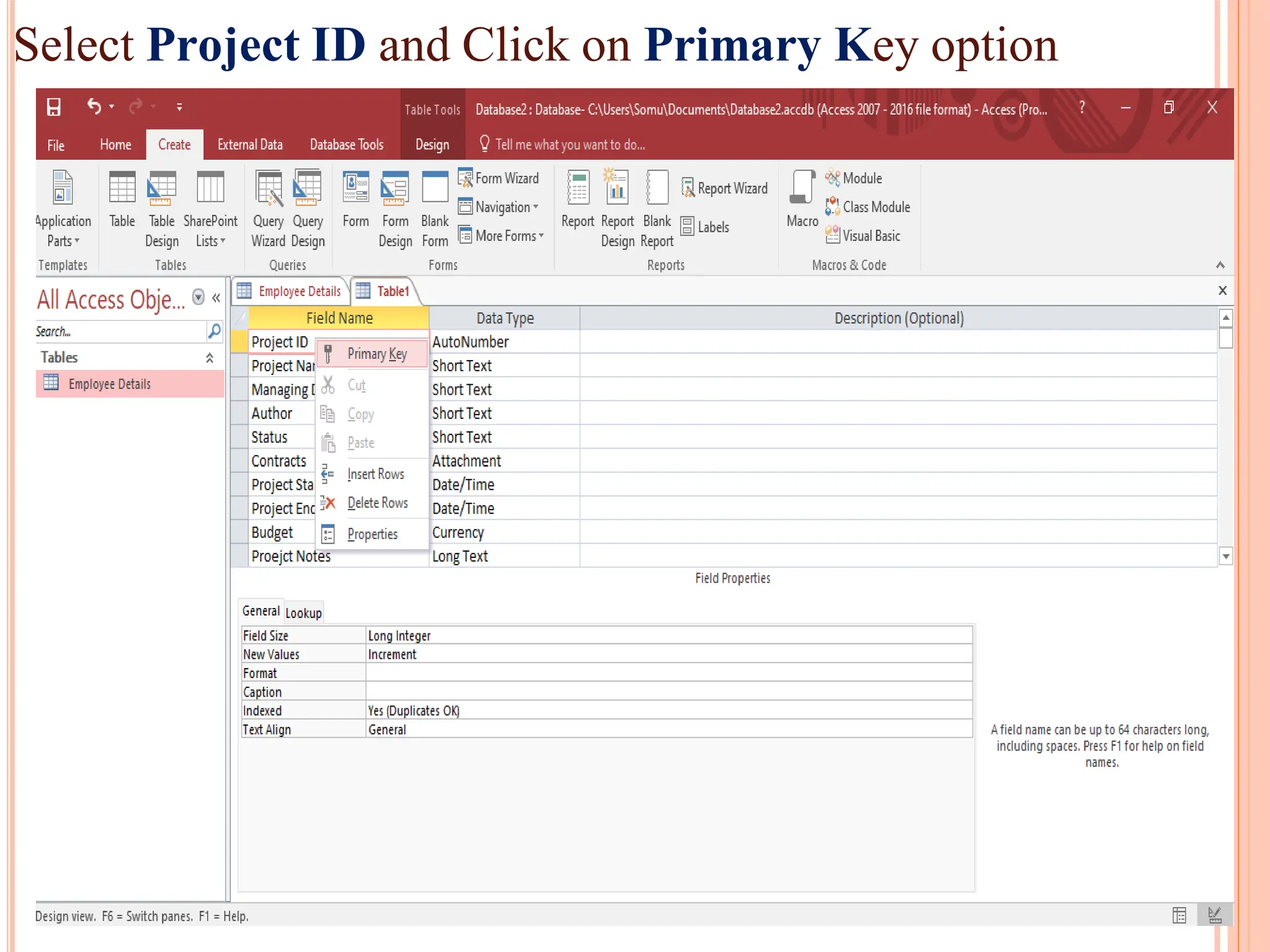
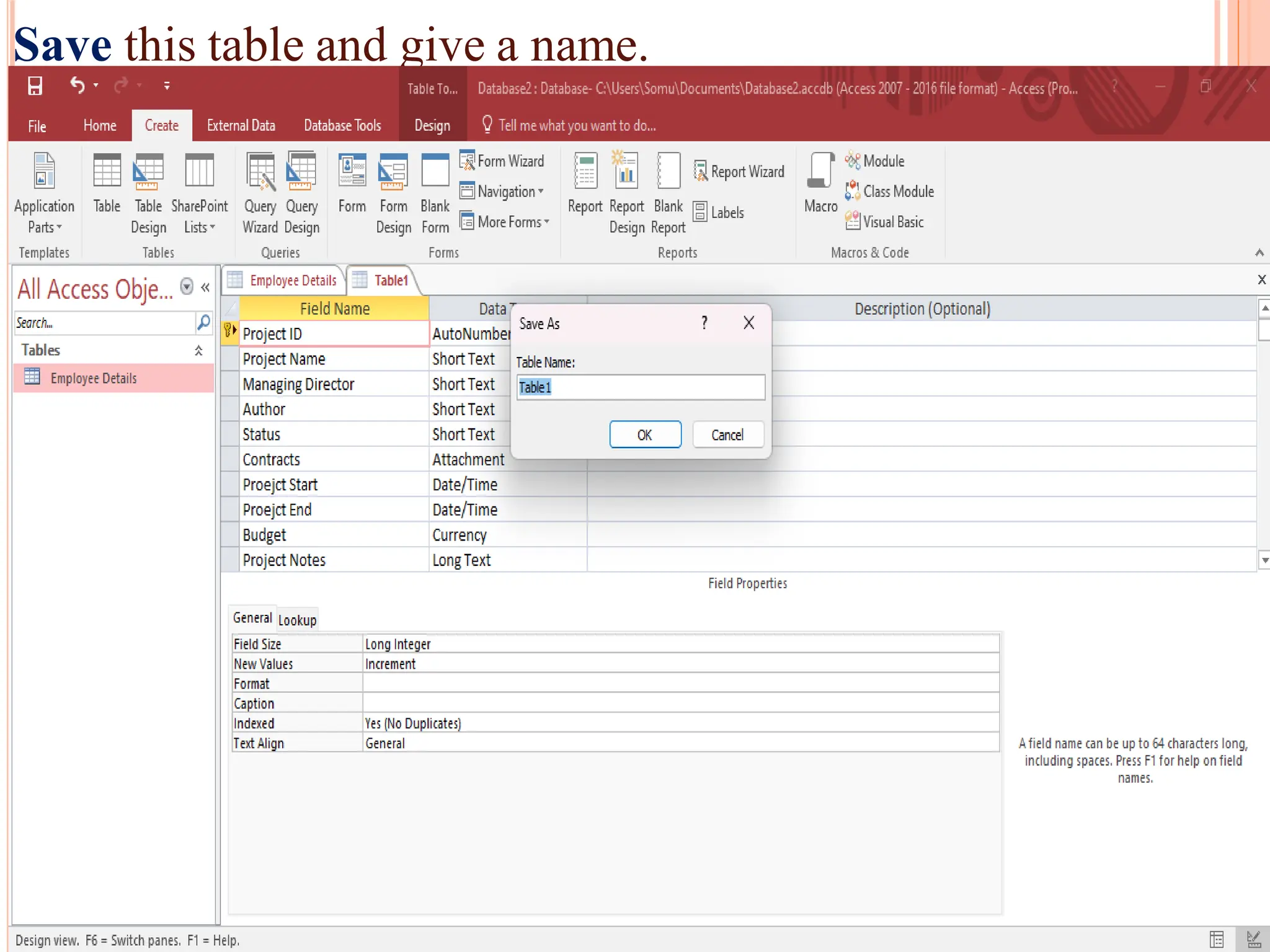
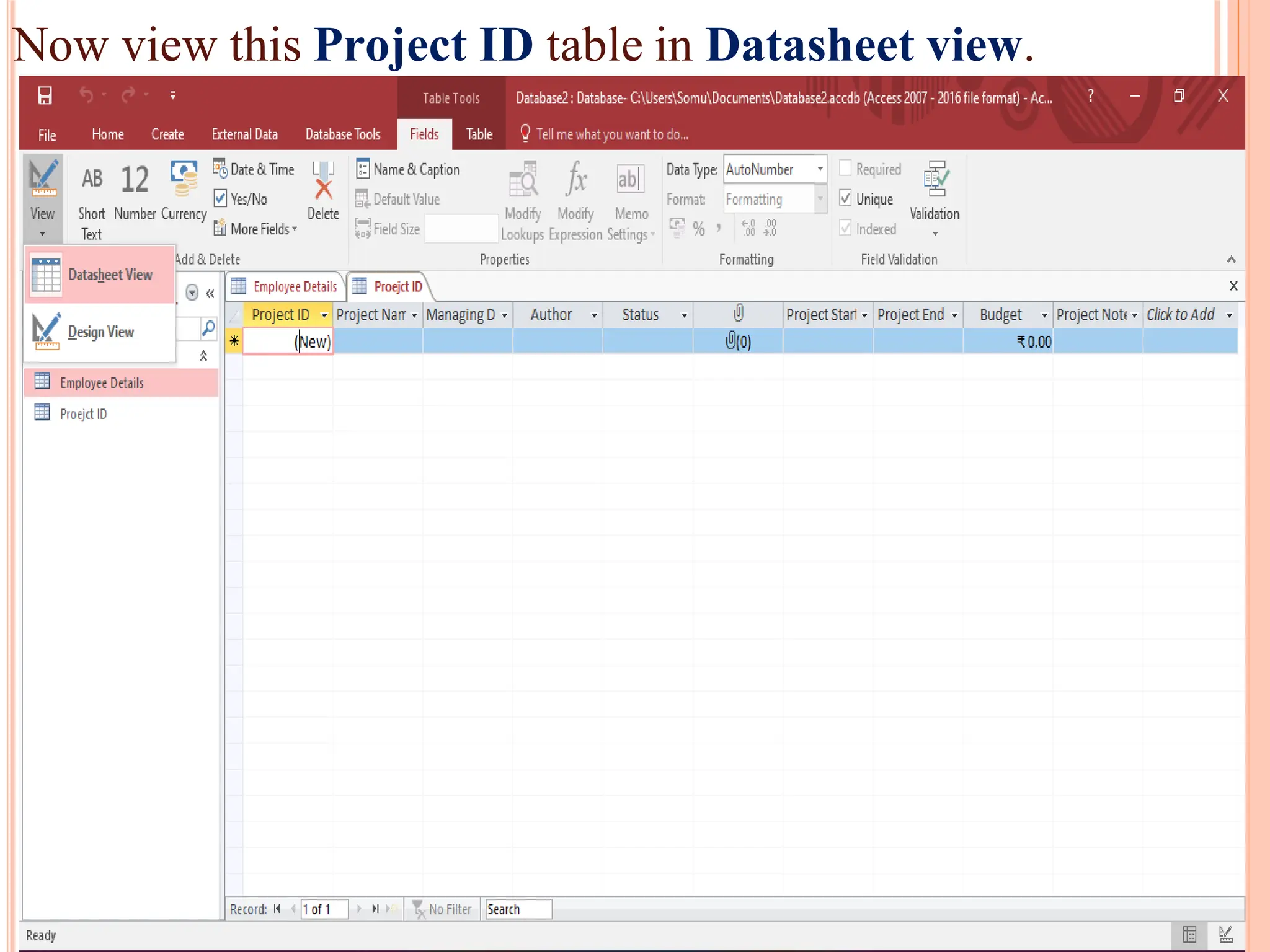
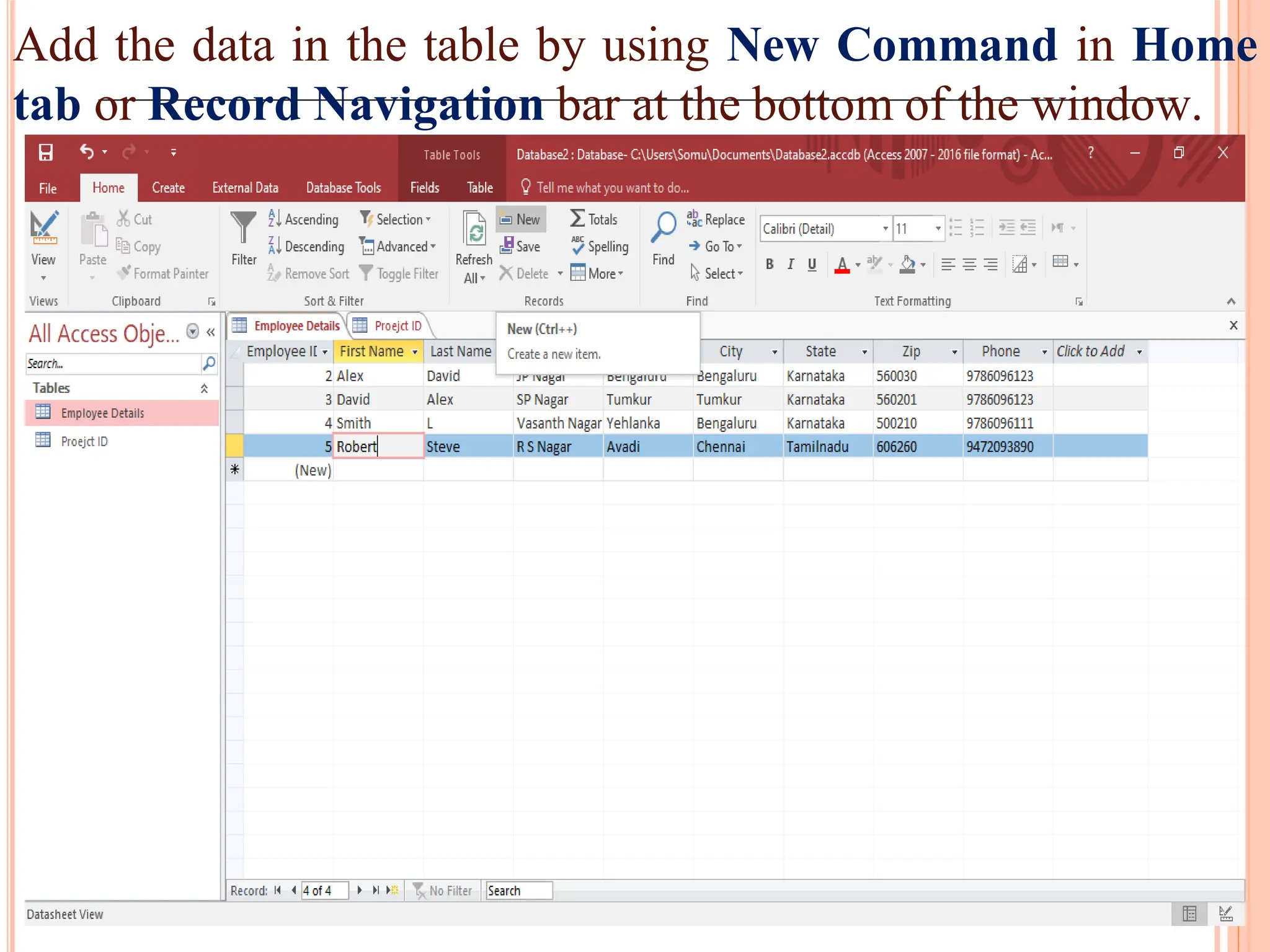
Detailed steps to create, edit, and organize tables and data within MS Access, including data type specifications.
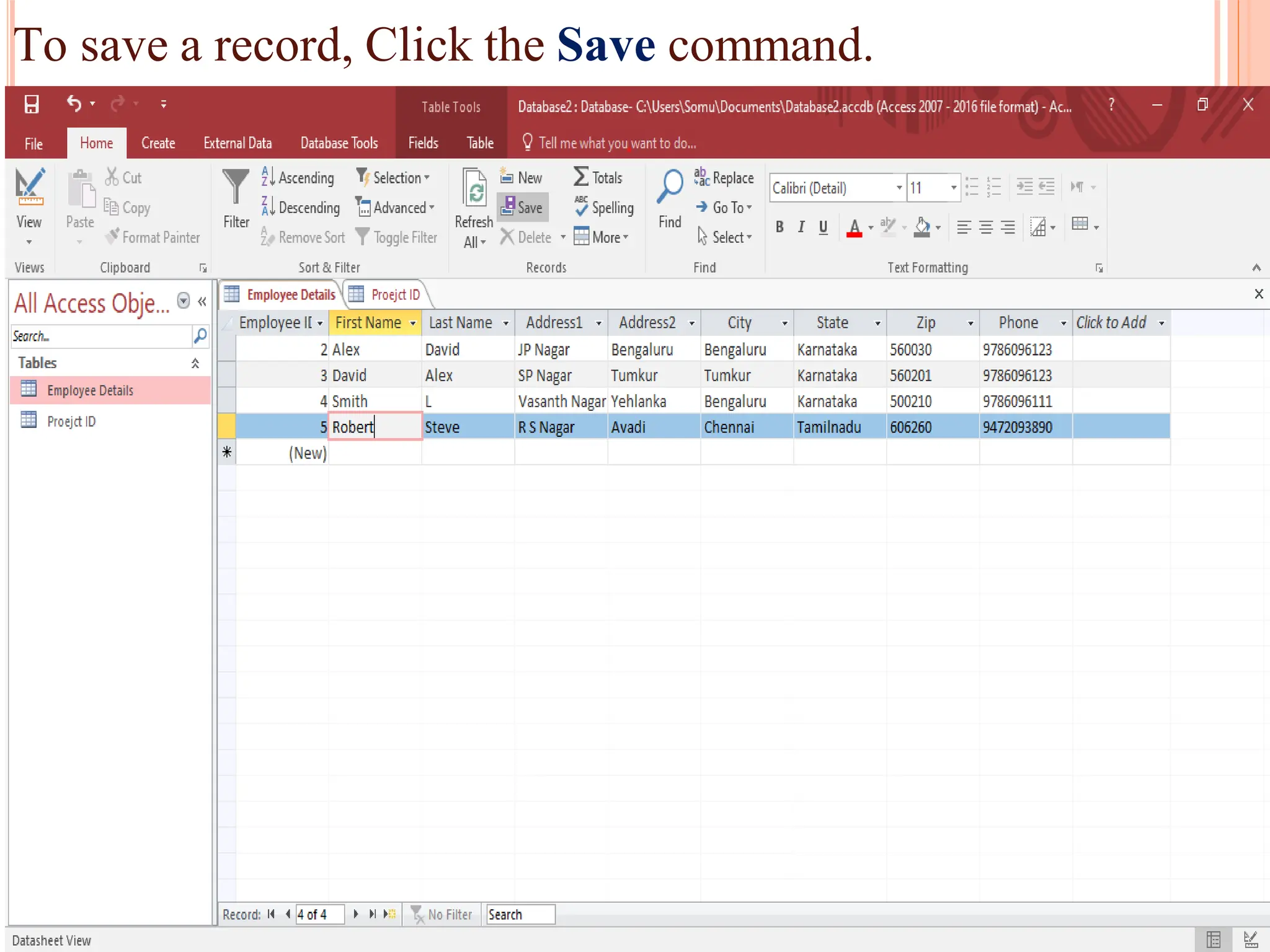
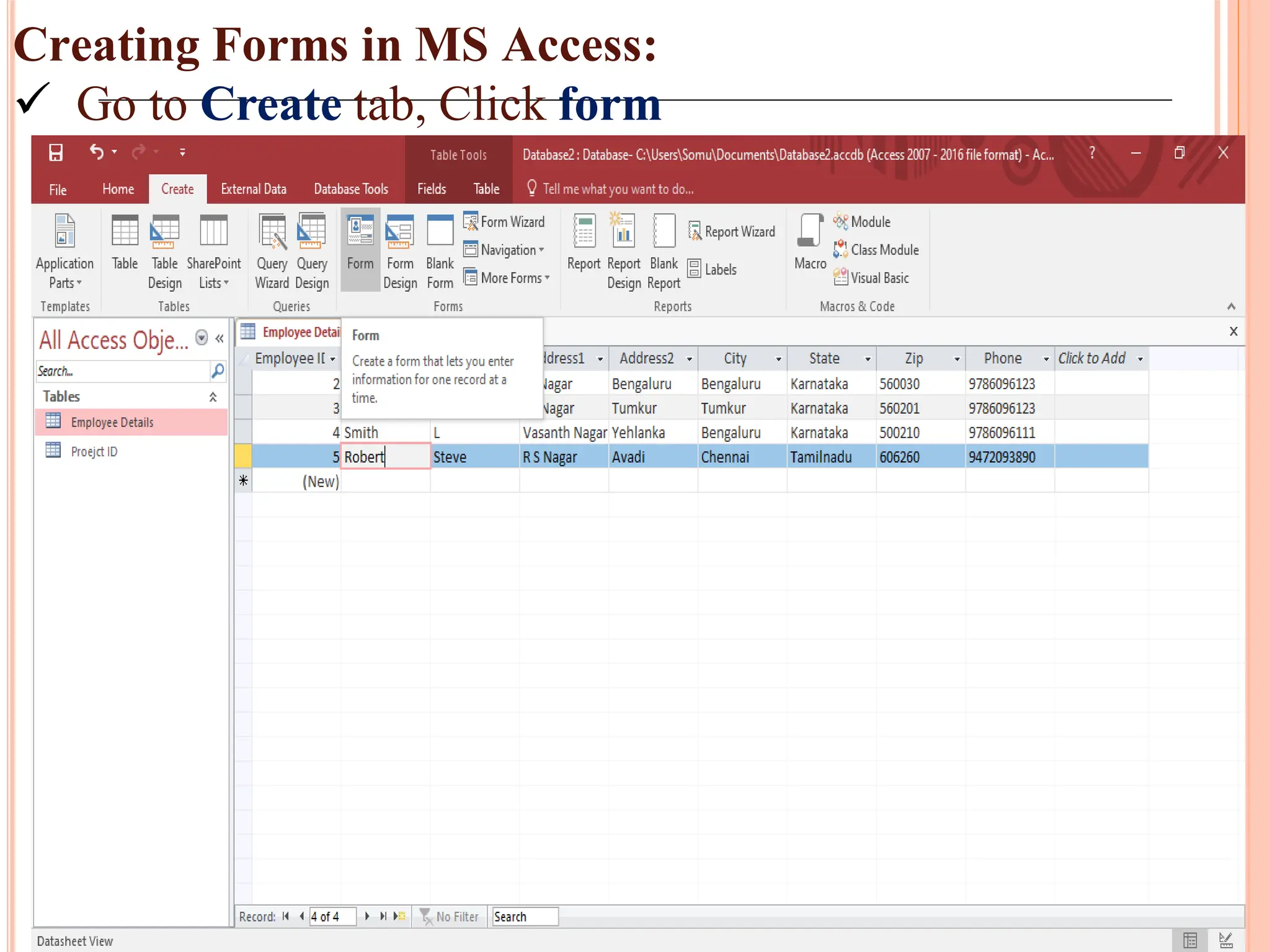
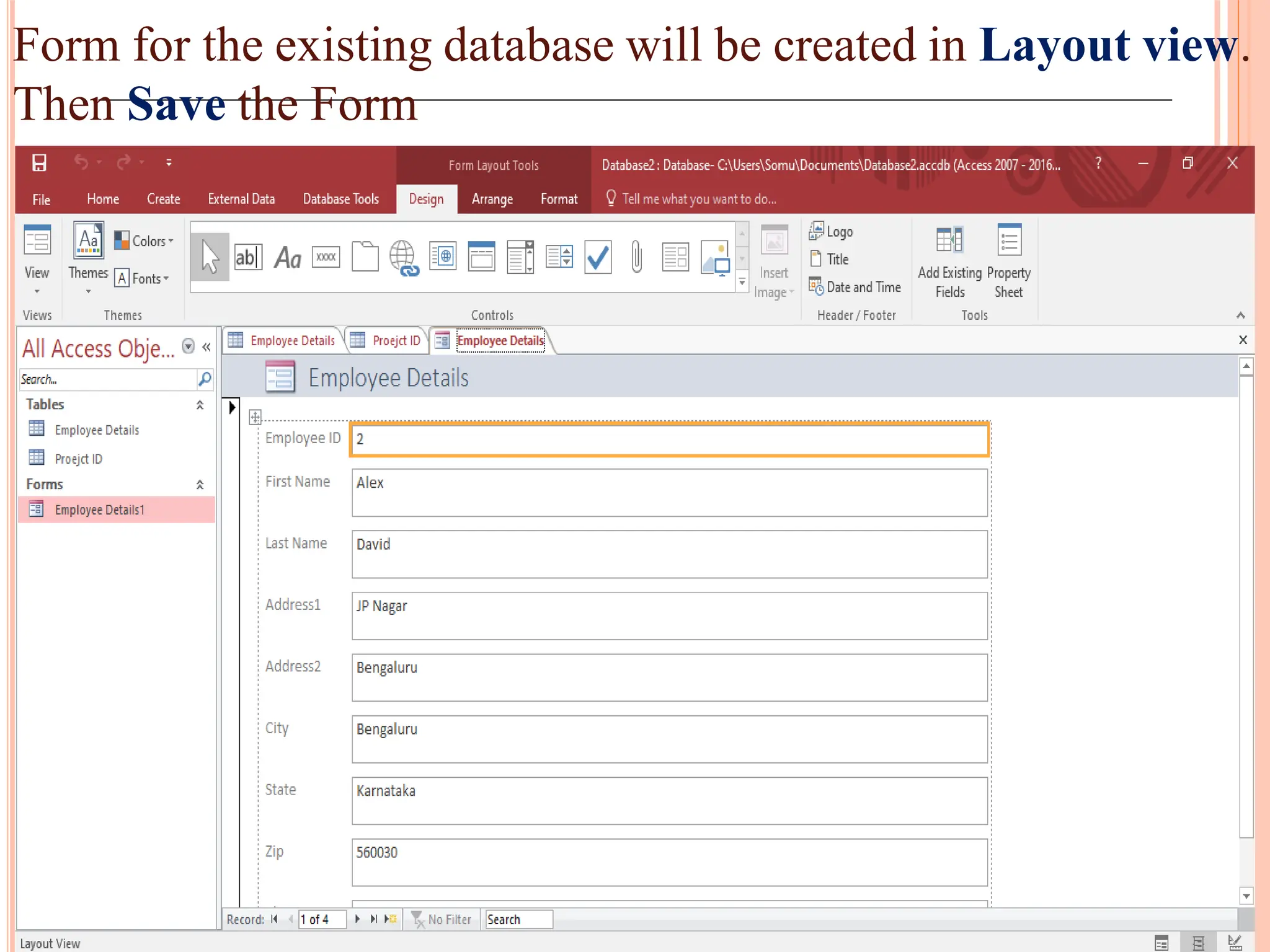
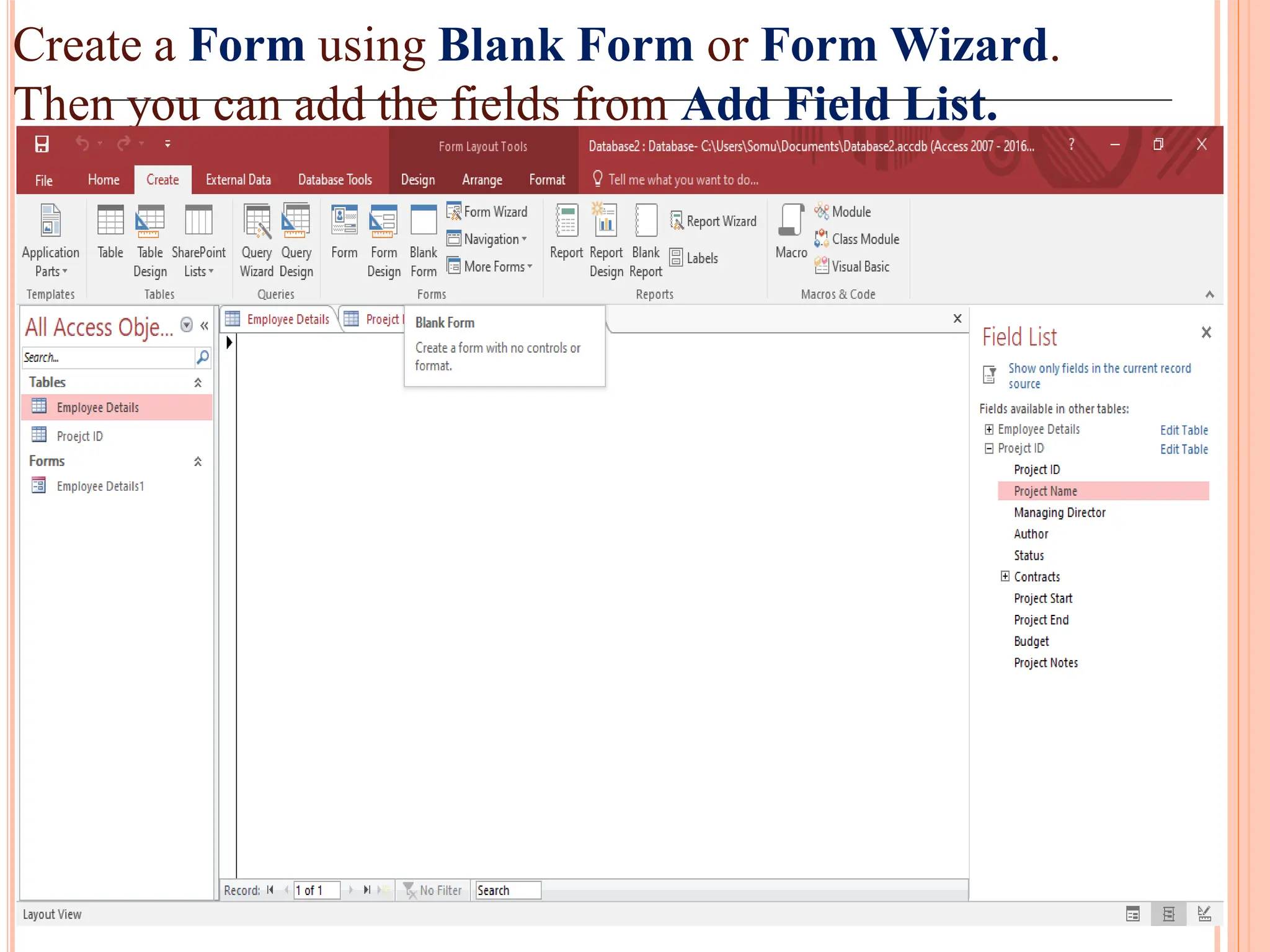
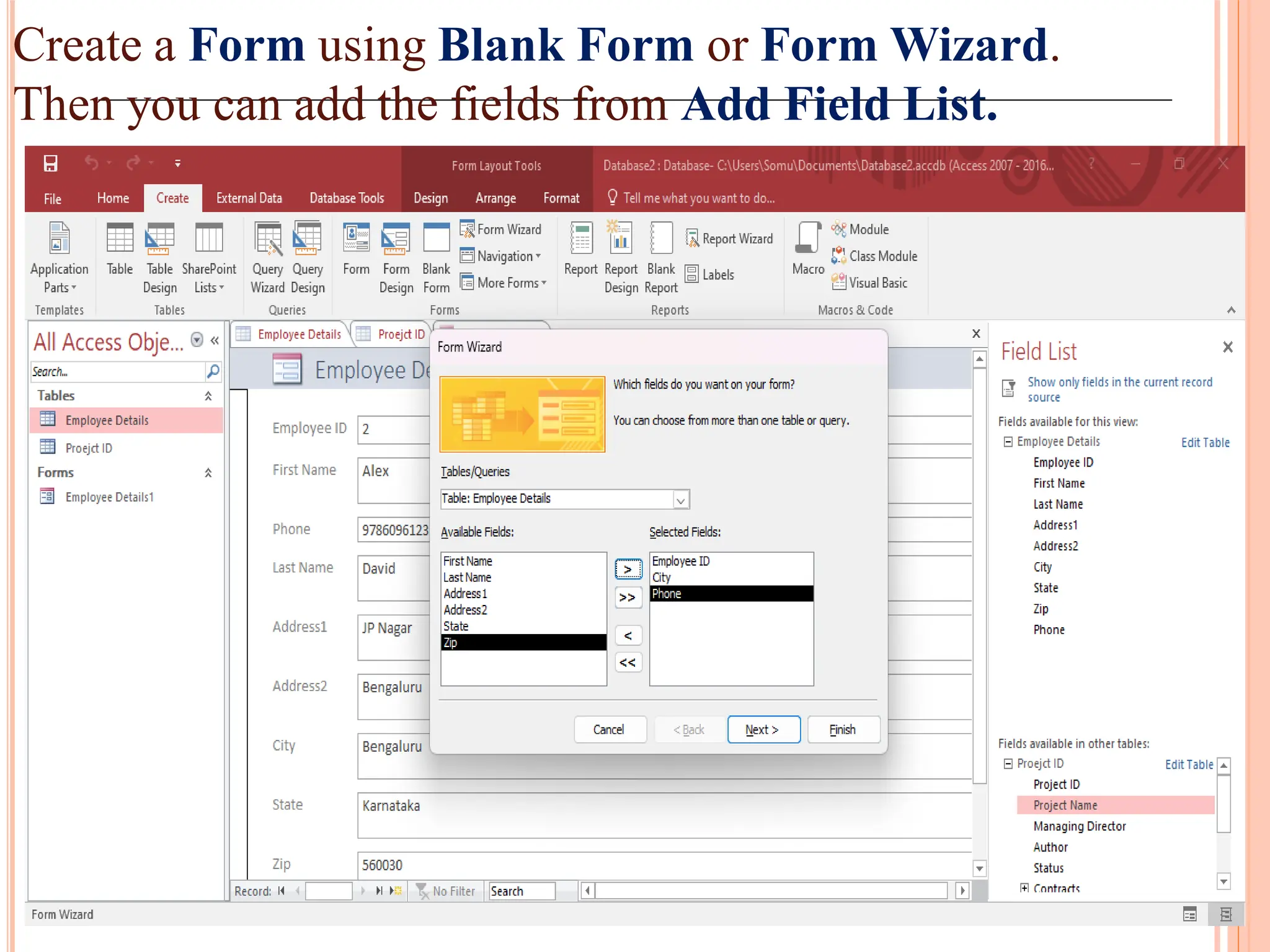
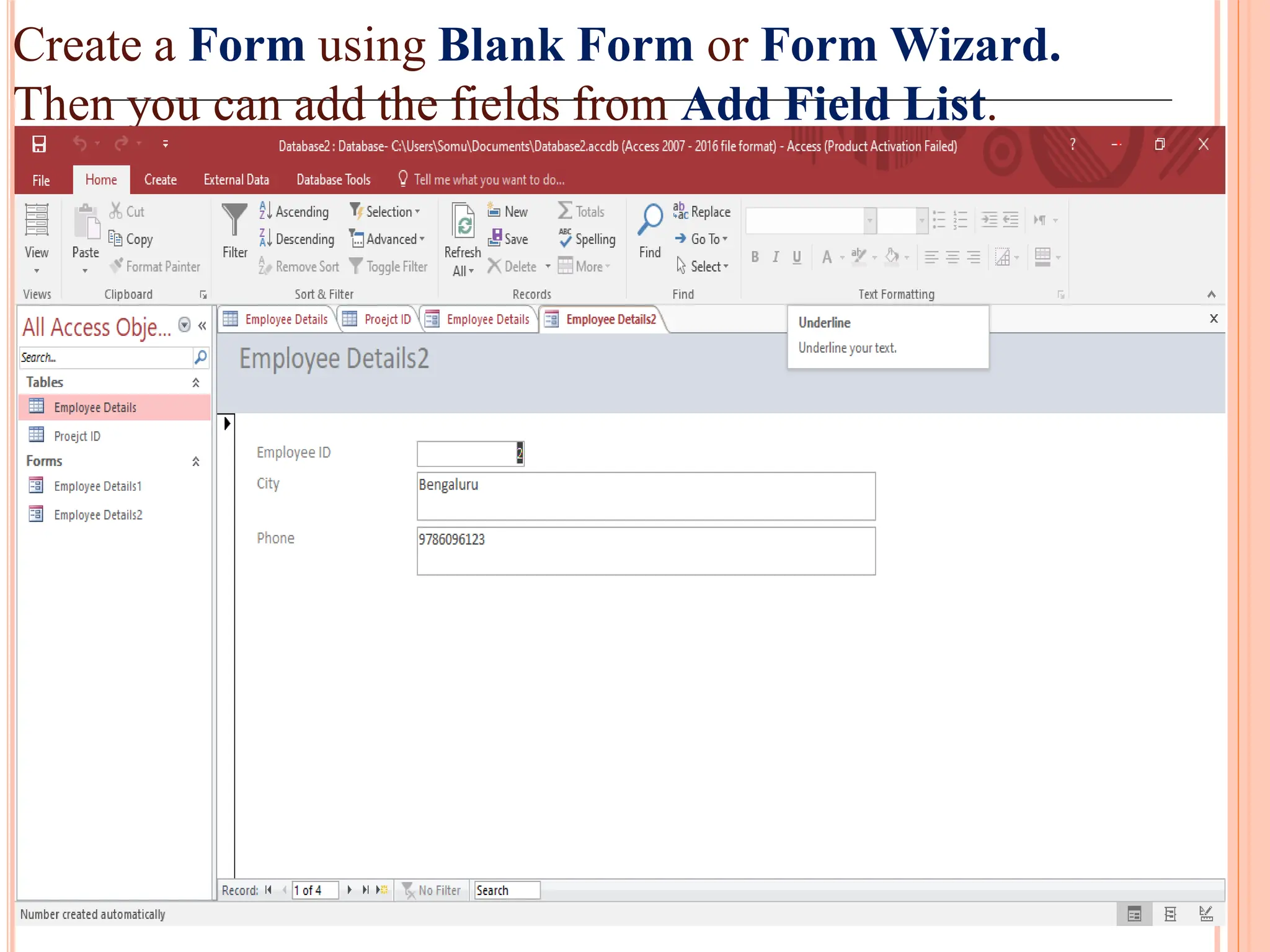
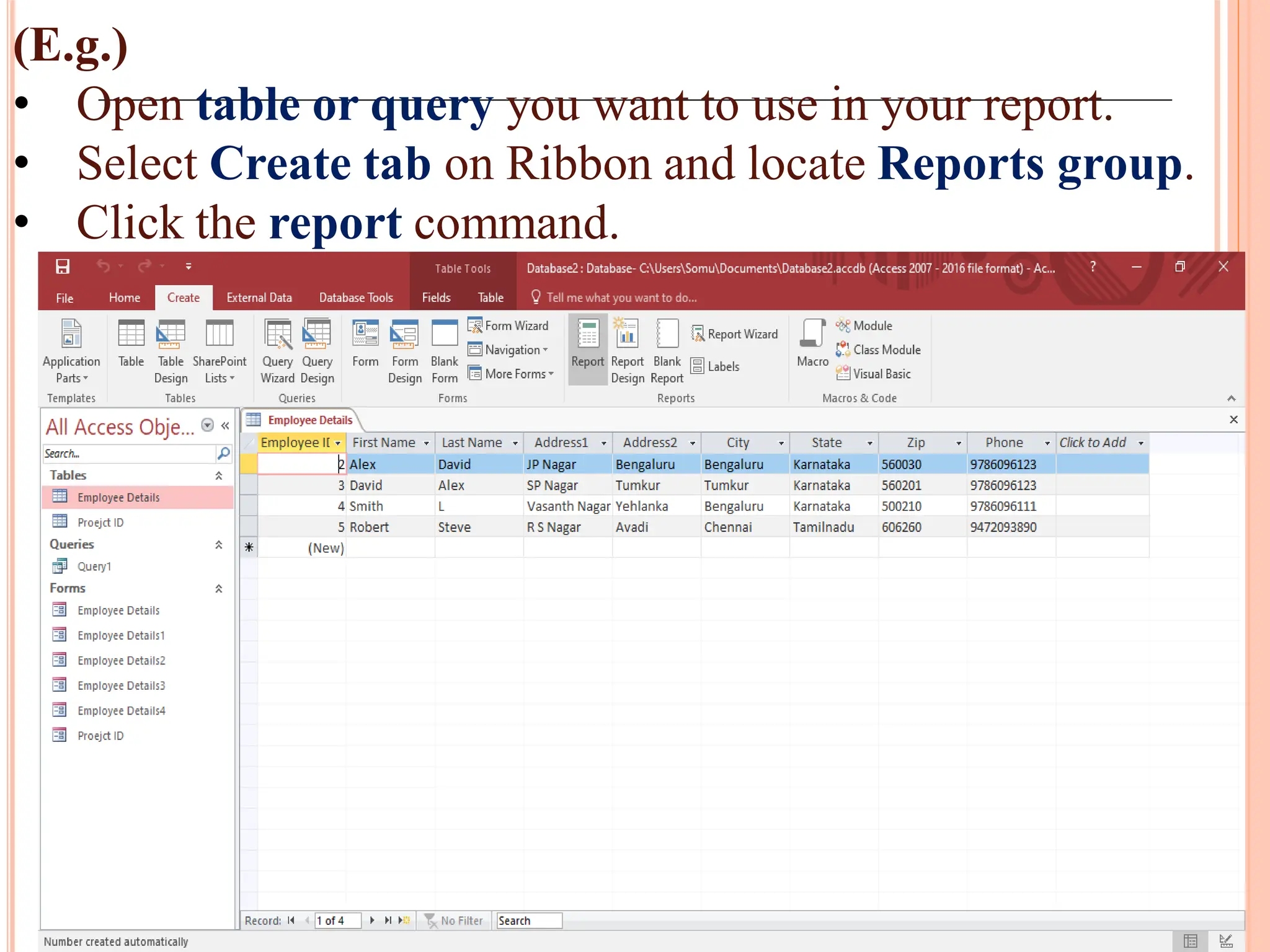
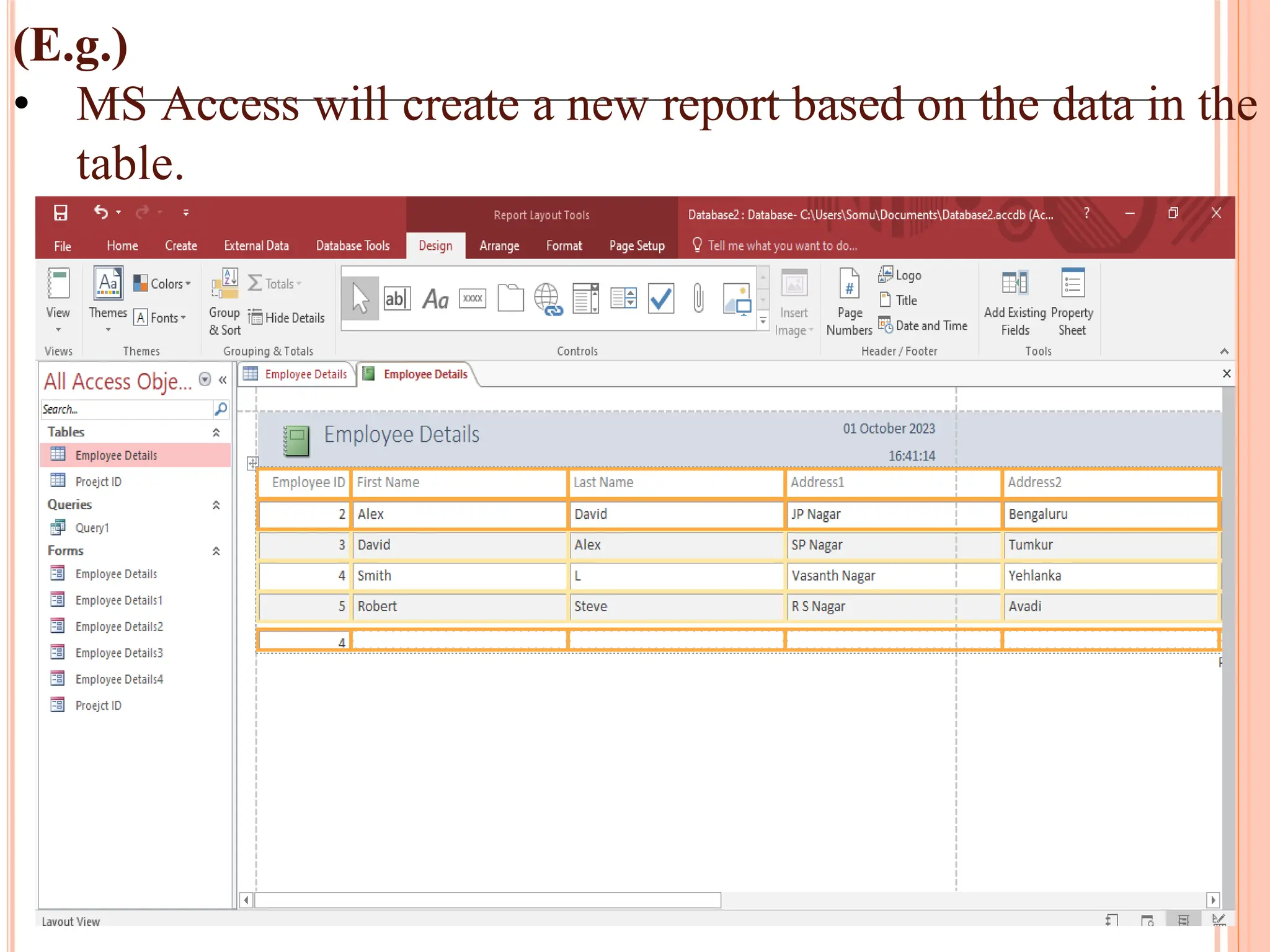
Creation and use of forms and reports in MS Access for data entry, formatting, and summarizing information for easy access.
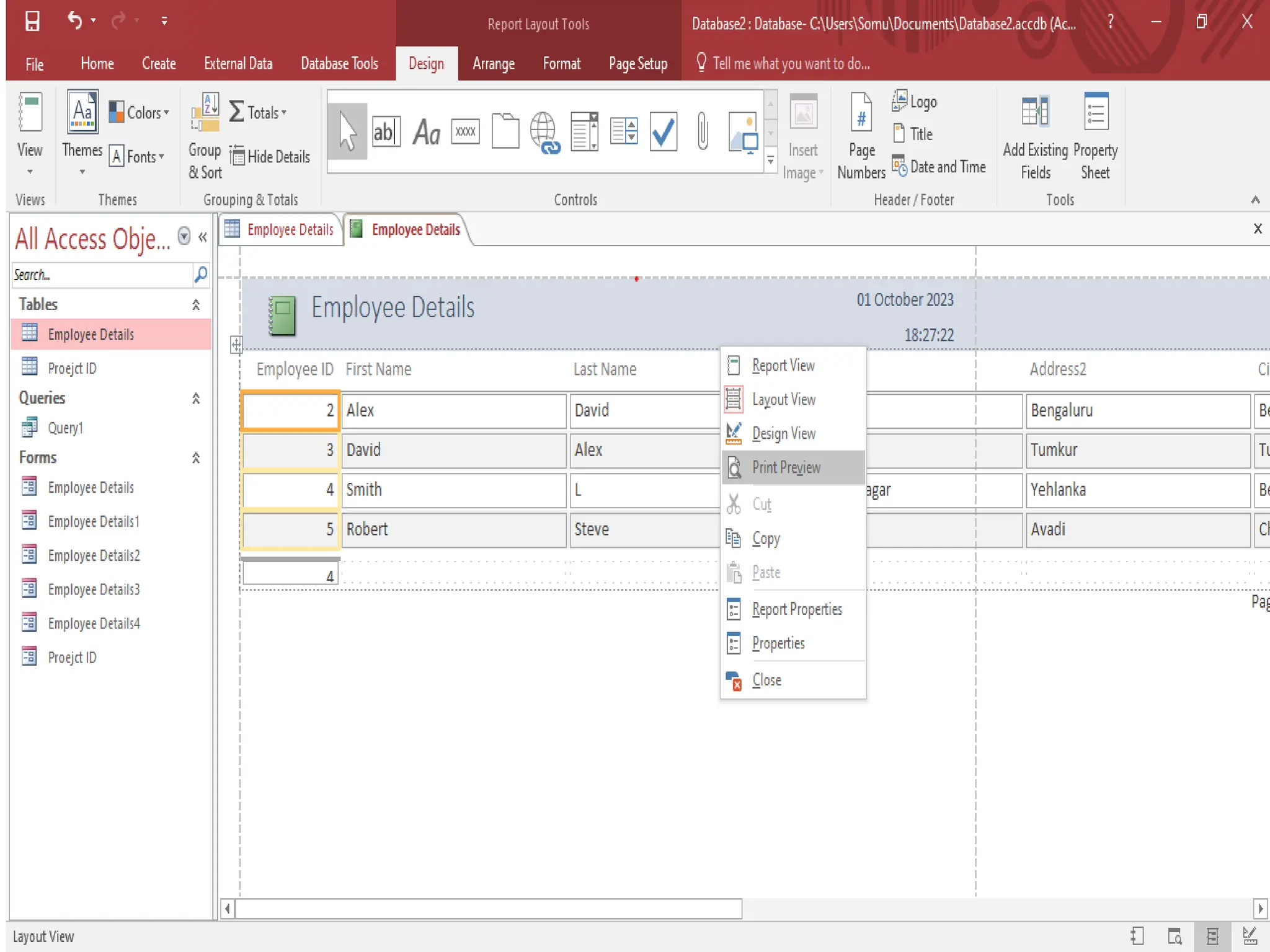
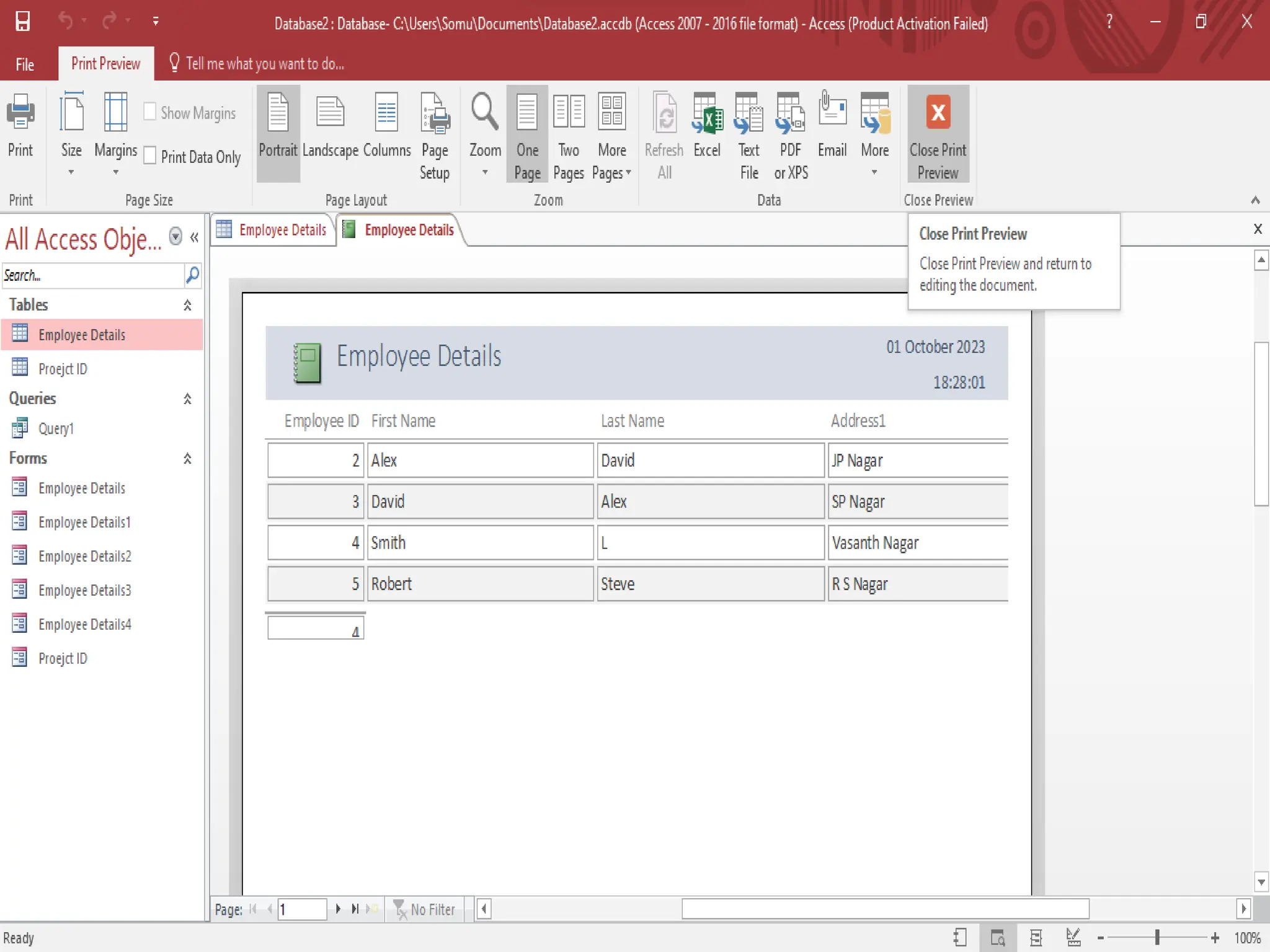
Procedure for previewing and printing reports in MS Access along with tips for formatting and utilizing reports effectively.

























![Basic Concept Of Database Management System (DBMS) [Presentation Slide]](https://cdn.slidesharecdn.com/ss_thumbnails/dbms-presentation-slide-170418193036-thumbnail.jpg?width=640&height=640&fit=bounds)









![Database System Concepts AND architecture [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/databasesystemconceptsandarchitectureautosaved-230817173311-be7f8590-thumbnail.jpg?width=640&height=640&fit=bounds)



















































