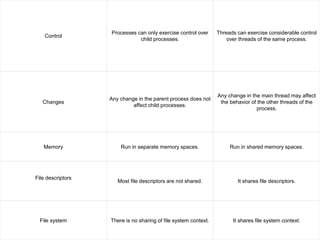
The document discusses distribution transparency in distributed databases, emphasizing that users remain unaware of the underlying distribution methods such as location, fragmentation, and replication transparency. It also explains distributed transactions, highlighting the four key properties: atomicity, consistency, isolation, and durability. Additionally, it compares processes and threads, detailing their characteristics and the management differences between user-level and kernel-level threads.