Downloaded 251 times








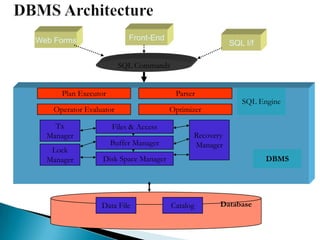












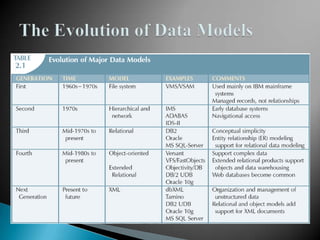

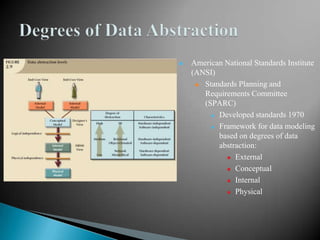
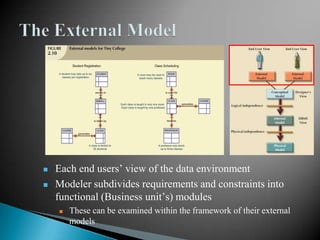

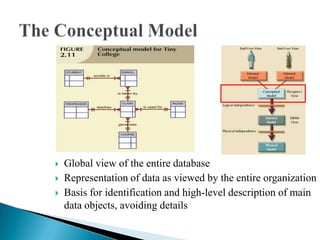
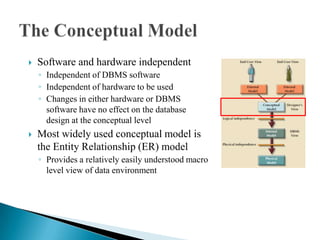
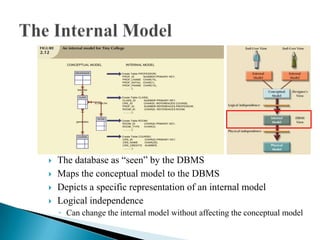
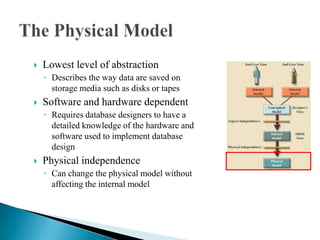


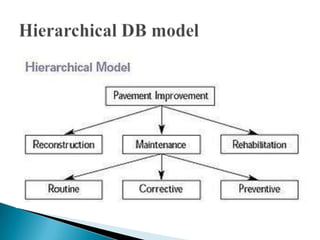
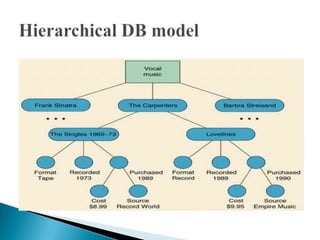
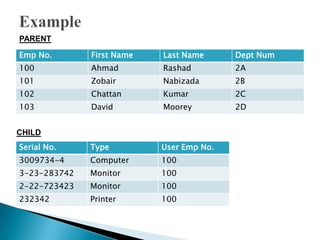





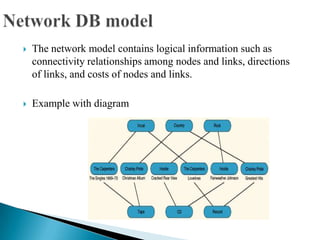









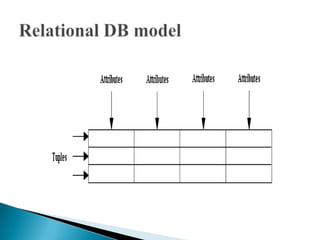






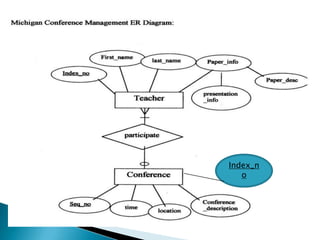





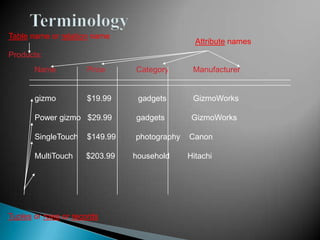





The document discusses database management systems and data modeling. It begins by defining key terms like data, databases, database management systems, and data models. It then provides a brief history of database development from the 1960s to the 1980s. The rest of the document discusses database concepts in more detail, including components of a DBMS, types of database users, database administration responsibilities, data modeling techniques, and the evolution of different data models.























































































