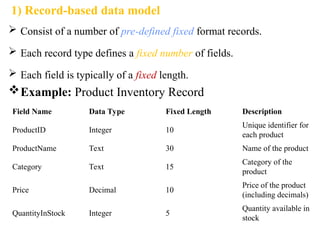
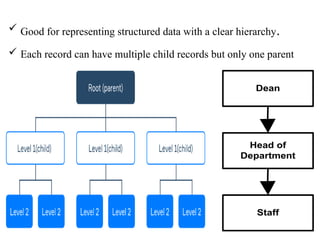
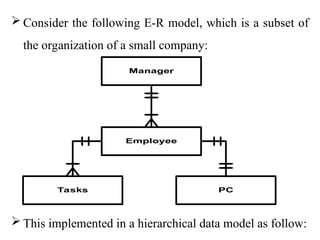
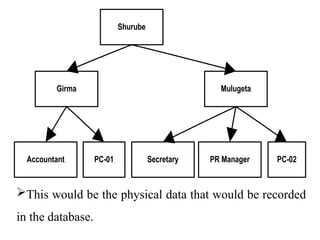
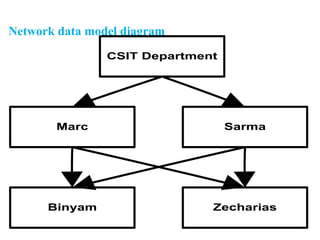
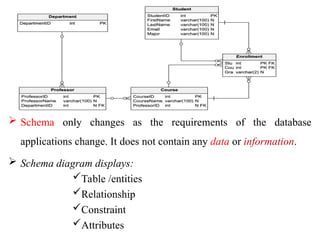
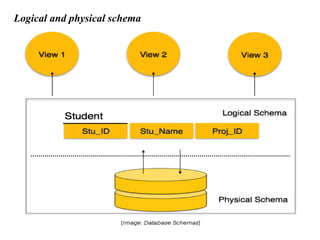
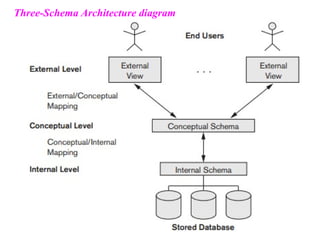
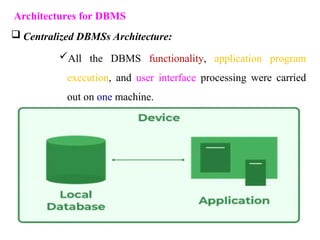
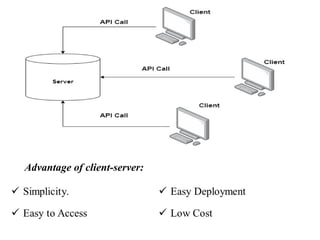
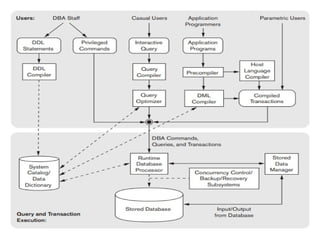
Chapter 2 provides an overview of database system architecture, focusing on data models, schemas, and instances, with detailed explanations of hierarchical, network, and relational data models. It explains how data is organized, the constraints applied, and the importance of data independence within different database architectures. Additionally, it addresses database languages and interfaces, highlighting the roles of Data Definition Language (DDL), Data Manipulation Language (DML), and Transaction Control Language (TCL).


























































![Database System Concepts AND architecture [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/databasesystemconceptsandarchitectureautosaved-230817173311-be7f8590-thumbnail.jpg?width=640&height=640&fit=bounds)












![chapter 2-DATABASE SYSTEM CONCEPTS AND architecture [Autosaved].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-databasesystemconceptsandarchitectureautosaved-230512145134-613f7180-thumbnail.jpg?width=640&height=640&fit=bounds)


























