Download as PDF, PPTX


















































This document outlines the ETL (Extract, Transform, Load) process essential for data warehousing, detailing the stages of extraction, transformation, and loading of data, as well as data quality considerations. It describes various ETL tools, best practices, and challenges faced in ensuring data quality throughout the process. The document emphasizes the roles of different stakeholders in data quality initiatives and the adoption of data quality tools for error discovery and correction.
An overview of ETL process and its significance in data warehousing, focusing on extraction, transformation, loading, and data quality.
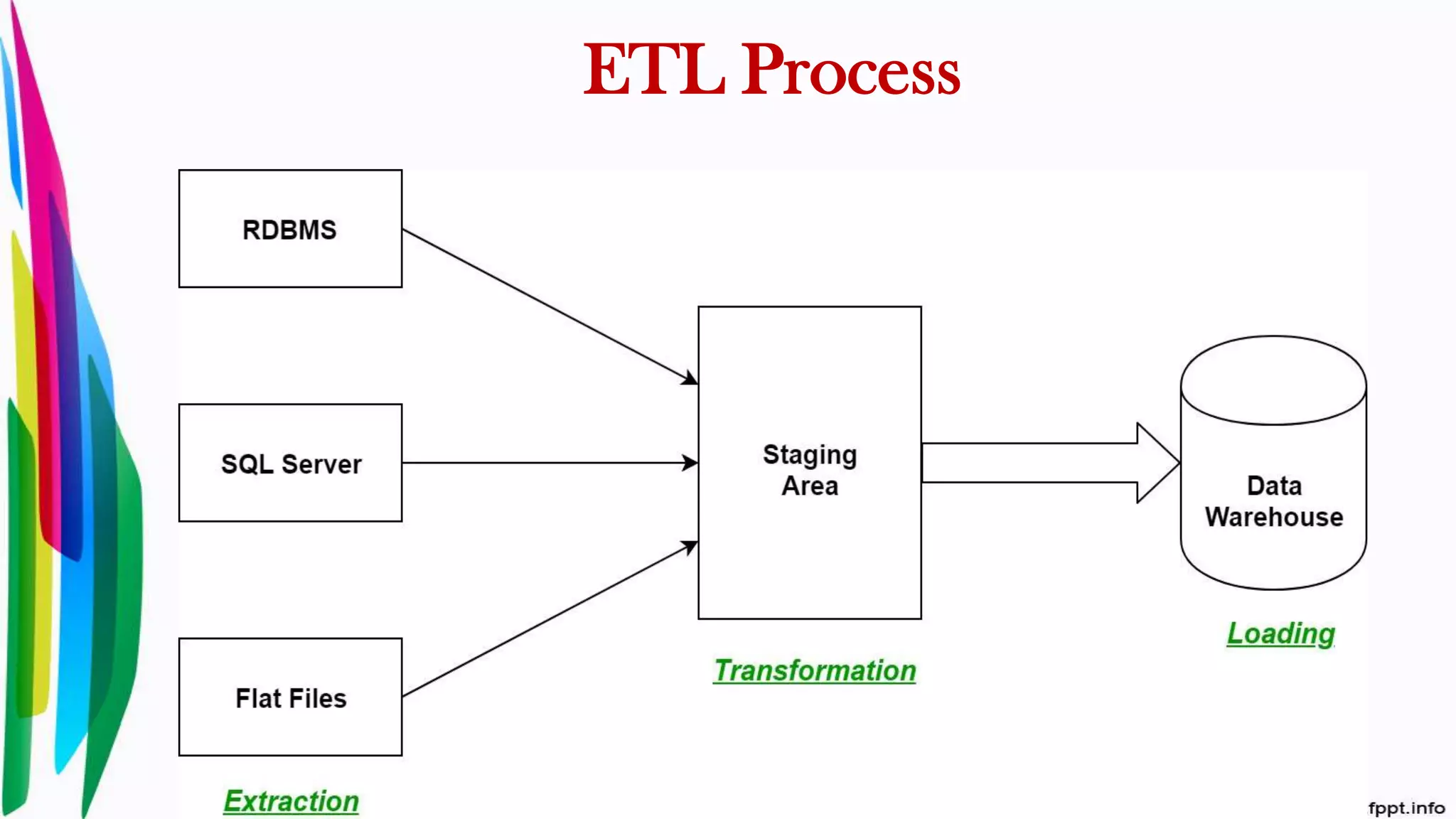
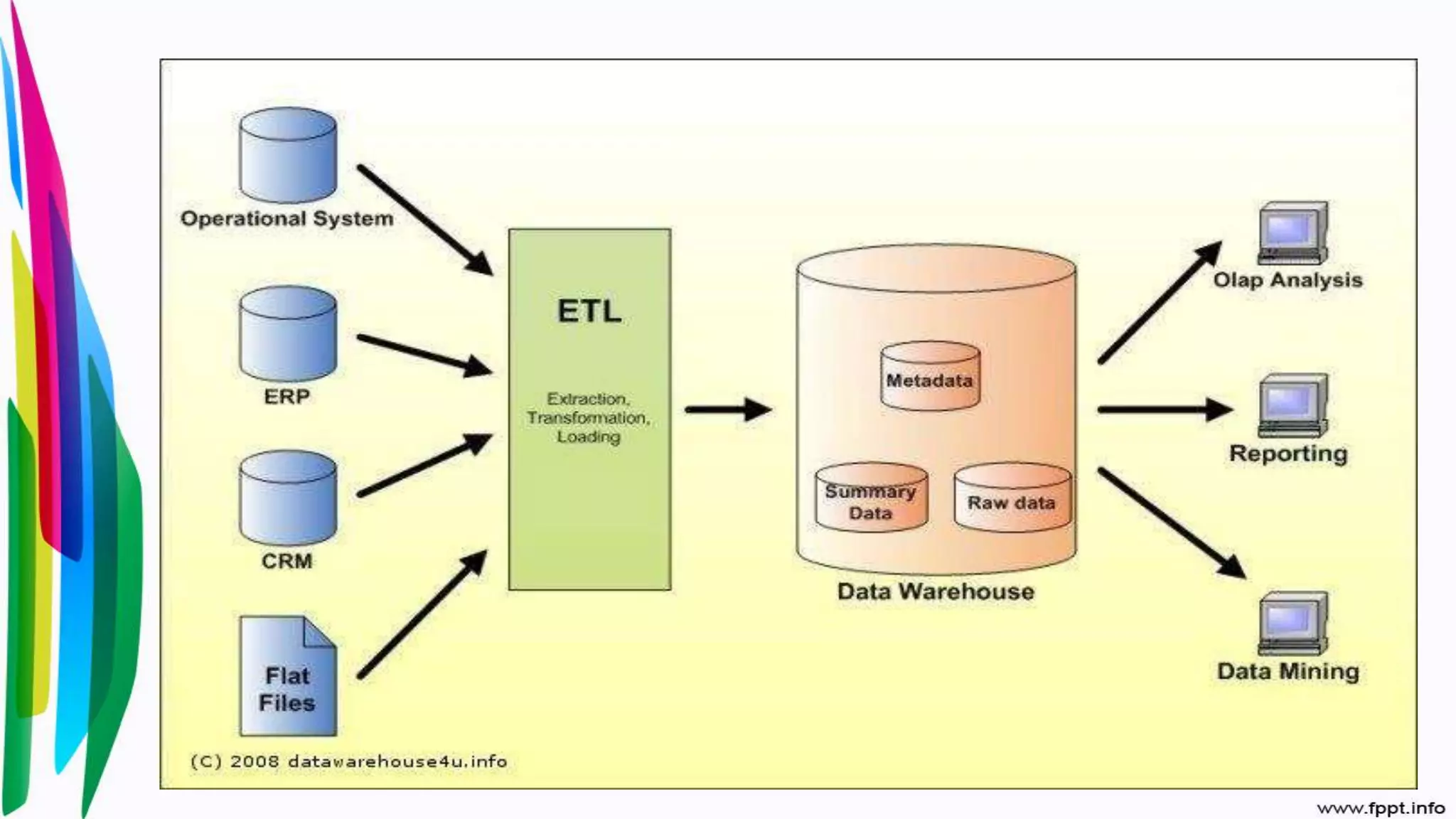
Definition and importance of ETL in data warehousing; integration of multiple data sources for a consistent data store.
List of prominent ETL tools like Google BigQuery, Informatica, and Oracle Data Integrator.
Discussion on the advantages of ETL tools including scalability, simplicity, compliance, and cost-effectiveness.
Details on the extraction phase: identifying source systems, extraction methods, issues, and best practices.
Explanation of data transformation tasks including filtering, cleaning, merging, and summarizing to standardize data.
Description of the loading phase, discussing methods to load transformed data into the data warehouse.
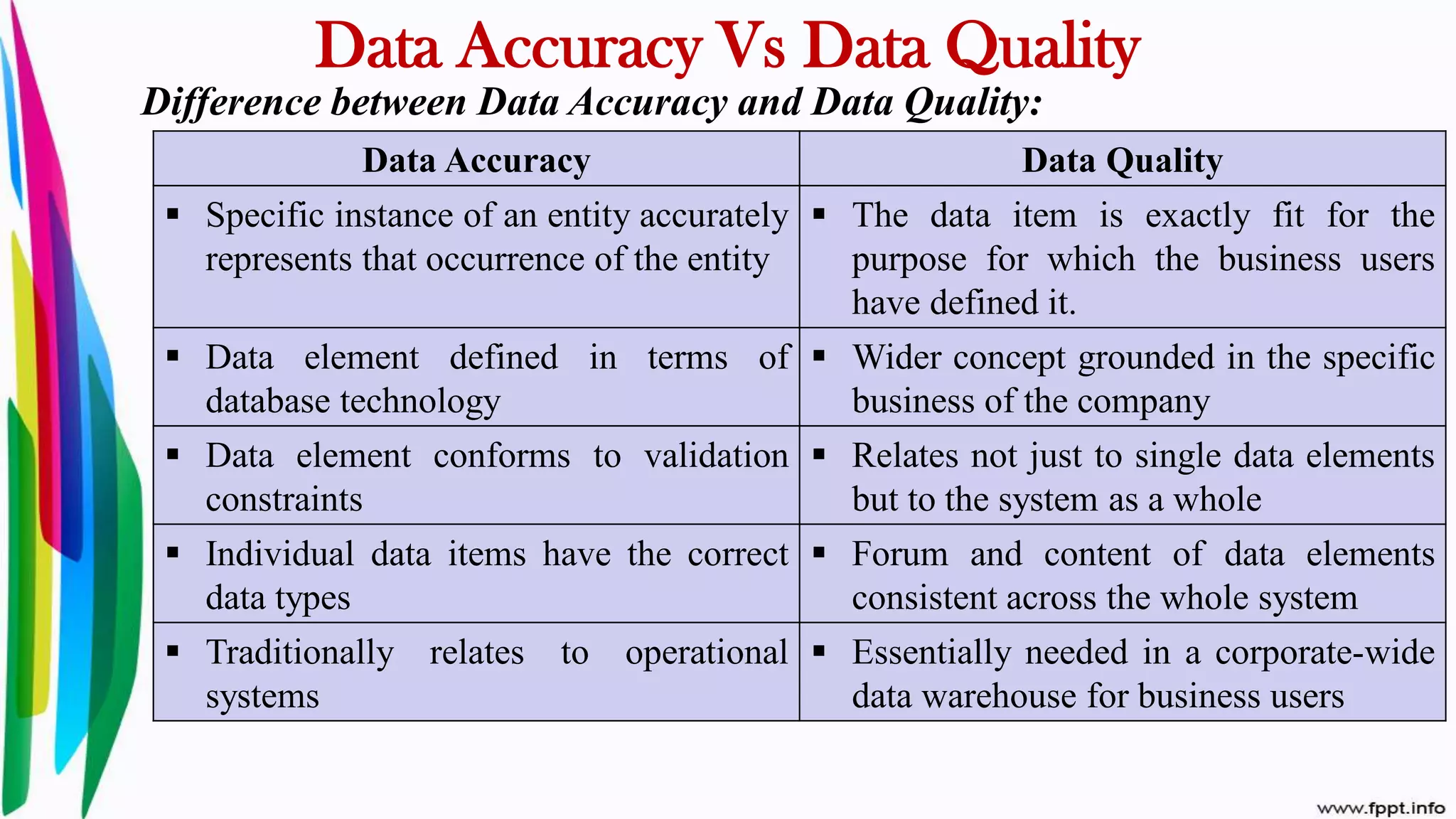
Exploration of data quality concepts, definitions, and importance for operational systems and business applications.
Characteristics of data quality including accuracy, completeness, redundancy, and timeliness.
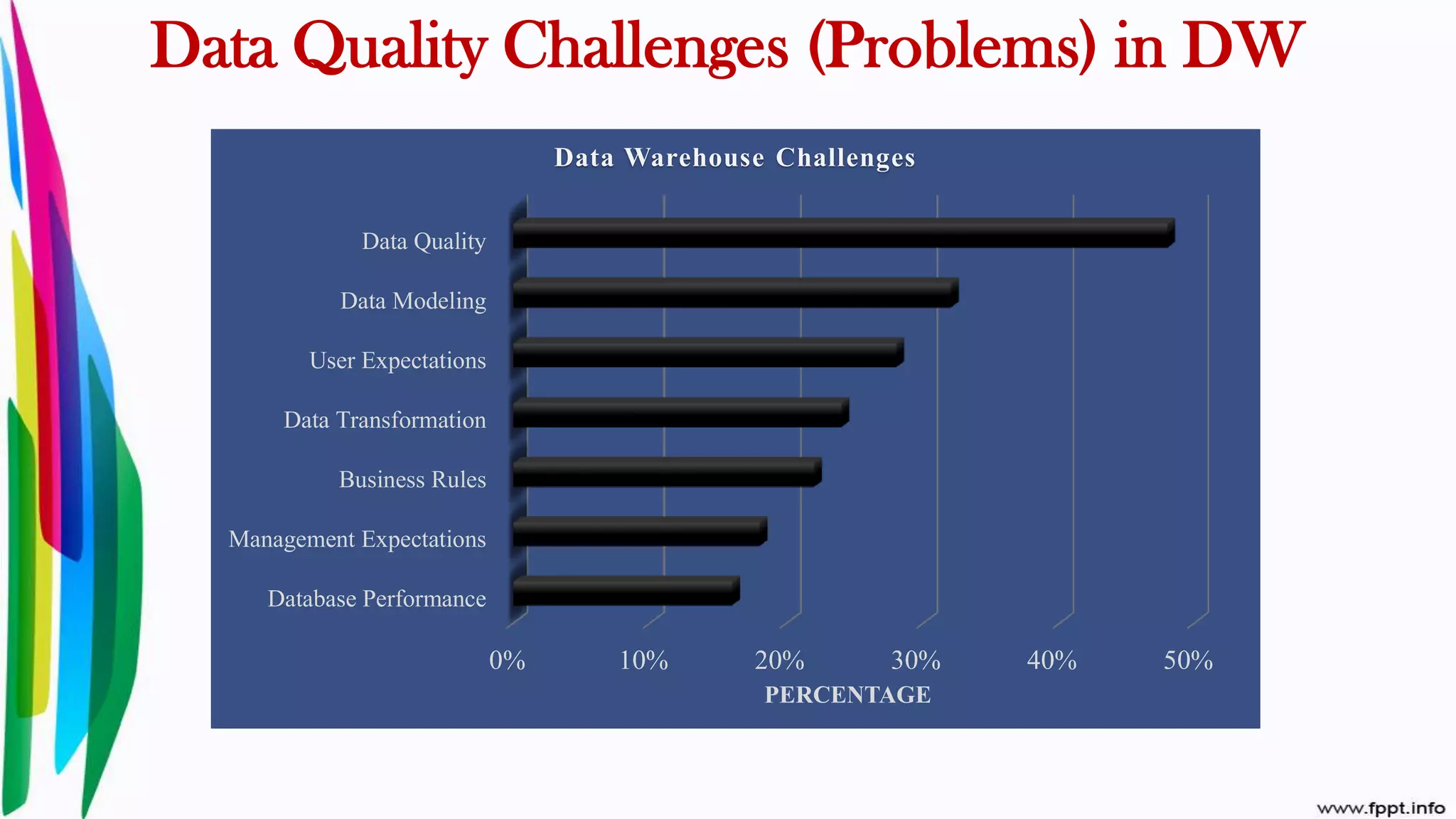
Overview of challenges faced in maintaining data quality and initiating data quality frameworks.
Description of different roles involved in ensuring data quality, including data consumers, producers, and experts.
Information on tools for data cleansing, error discovery, and features to ensure data quality.
Advantages of high data quality including better analytics, customer service, and strategic decision-making.
Importance of design reviews for quality assurance in data warehouse design and the different design views.
Three approaches for constructing data warehouses: top-down, bottom-up, and combined methods.
Steps involved in designing a data warehouse including business processes, grain selection, and dimension choice.Importance of testing for data integrity and the different levels of testing in data warehouse systems.
A structured approach to testing data warehouse functionality, covering entry points and test framework design.
Aspects of testing in operational environments, such as security and management tools within a data warehouse.
Overview of the need for monitoring data warehouses to ensure performance, usability, and compliance.























































































