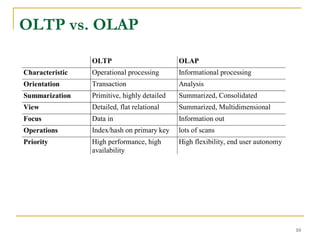
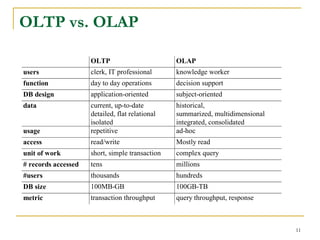
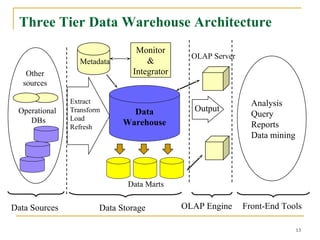
A data warehouse is a decision support database that consolidates historical data separately from operational databases, supporting management's decision-making processes. It is characterized by being subject-oriented, integrated, time-variant, and nonvolatile, with distinct functionalities compared to operational databases suited for transaction processing. Various models exist, including enterprise warehouses, data marts, and virtual warehouses, each designed to cater to specific data needs and user groups.















![19
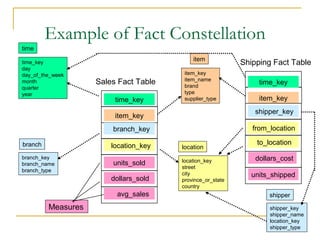
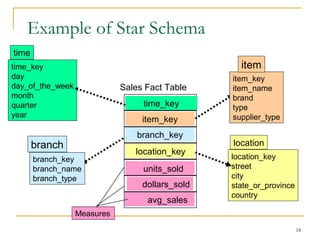
Defining Star Schema in DMQL
define cube sales_star [time, item, branch, location]:
dollars_sold = sum(sales_in_dollars), avg_sales =
avg(sales_in_dollars), units_sold = count(*)
define dimension time as (time_key, day, day_of_week, month,
quarter, year)
define dimension item as (item_key, item_name, brand, type,
supplier_type)
define dimension branch as (branch_key, branch_name,
branch_type)
define dimension location as (location_key, street, city,
province_or_state, country)](https://image.slidesharecdn.com/1-150506060450-conversion-gate01/85/1-4-data-warehouse-19-320.jpg)