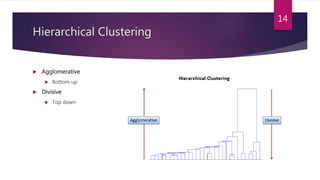
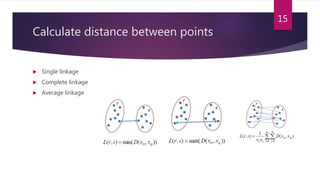
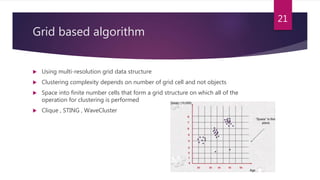
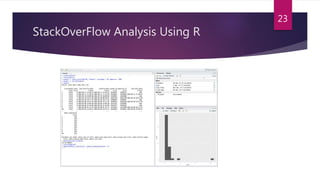
The document presents an overview of data science and its applications, particularly emphasizing machine learning and clustering algorithms. It discusses various types of clustering methods, including partitioning, hierarchical, and density-based techniques, and highlights their implementations in scenarios like market segmentation and city planning. Additionally, the document covers practical aspects, such as implementing k-means clustering with R and analyzing high-dimensional data.






































































![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)




































