Download to read offline





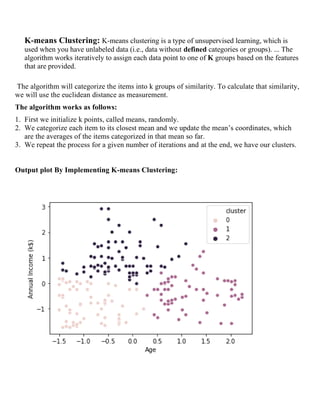


The assignment report on data mining cluster analysis outlines the clustering process, which groups similar data objects into clusters to simplify interpretation and highlight patterns in high-dimensional data. It discusses various clustering methods including BIRCH, DBSCAN, agglomerative hierarchical clustering, and k-means clustering, detailing their algorithms, parameters, and use cases. Links to Google Colab for implementing each clustering method are also provided.