Downloaded 1,469 times





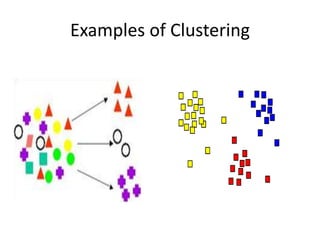













Clustering is an unsupervised learning technique used to group unlabeled data points together based on similarities. It aims to maximize similarity within clusters and minimize similarity between clusters. There are several clustering methods including partitioning, hierarchical, density-based, grid-based, and model-based. Clustering has many applications such as pattern recognition, image processing, market research, and bioinformatics. It is useful for extracting hidden patterns from large, complex datasets.












































![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)



































