Downloaded 118 times


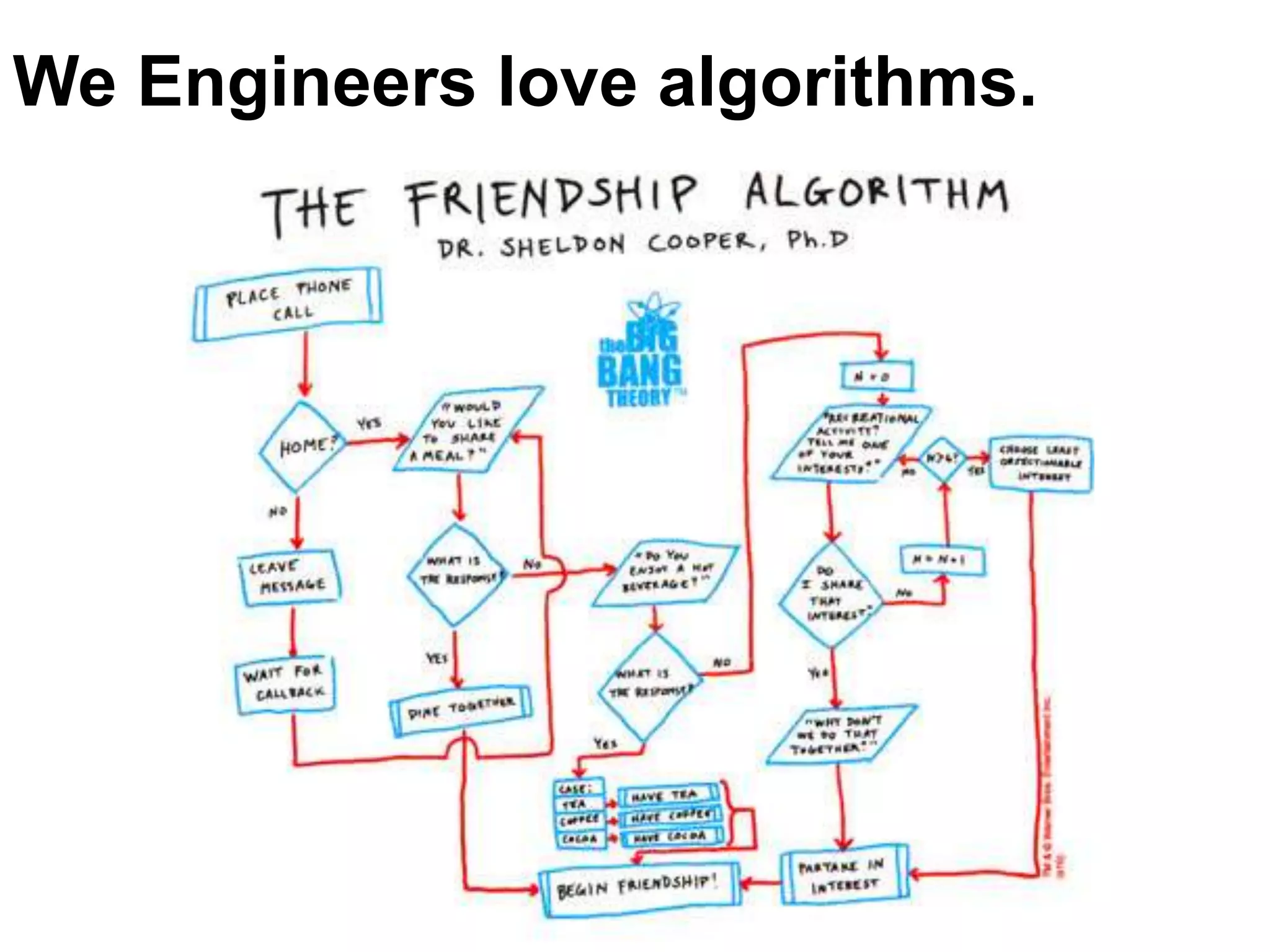






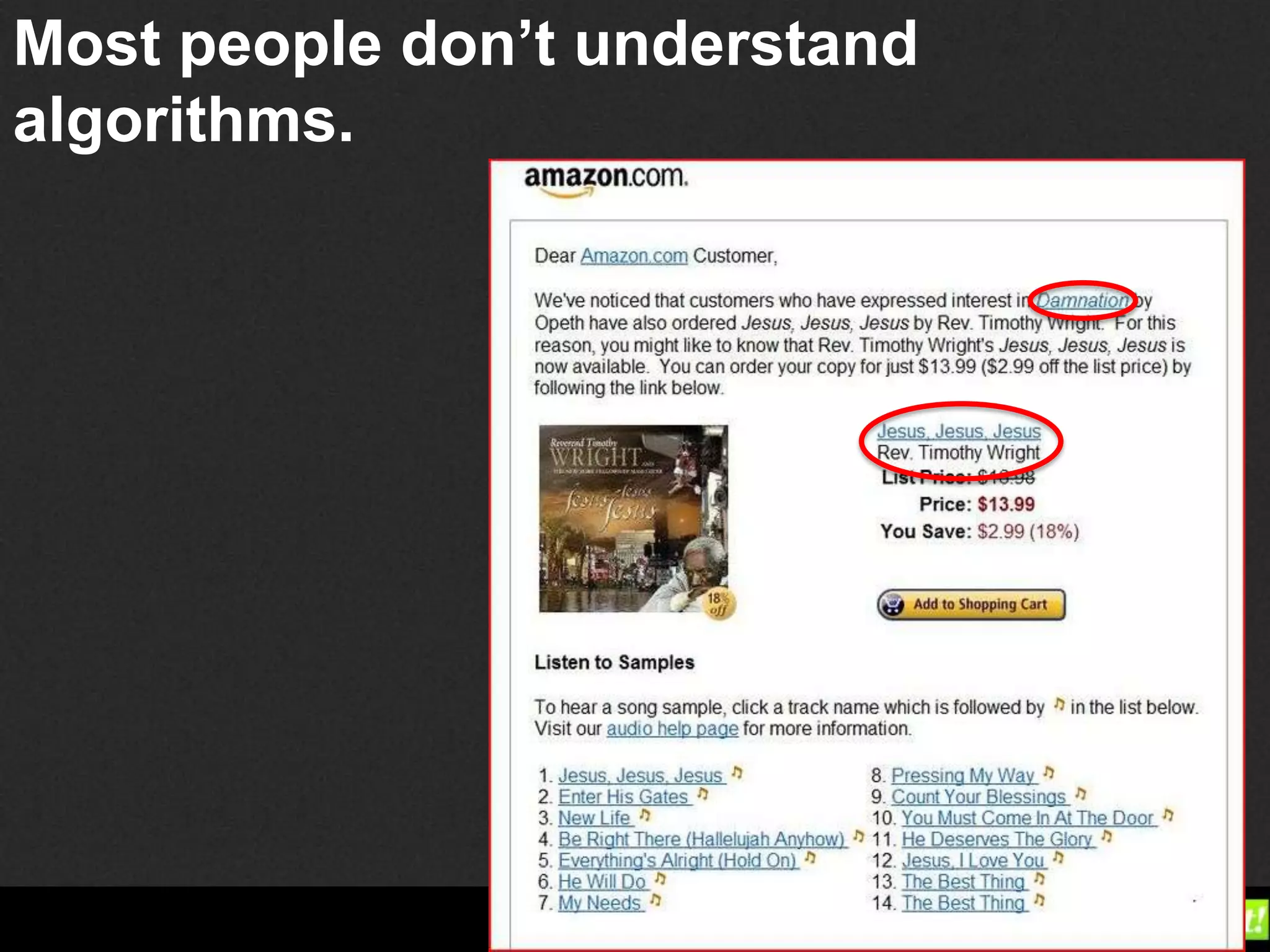
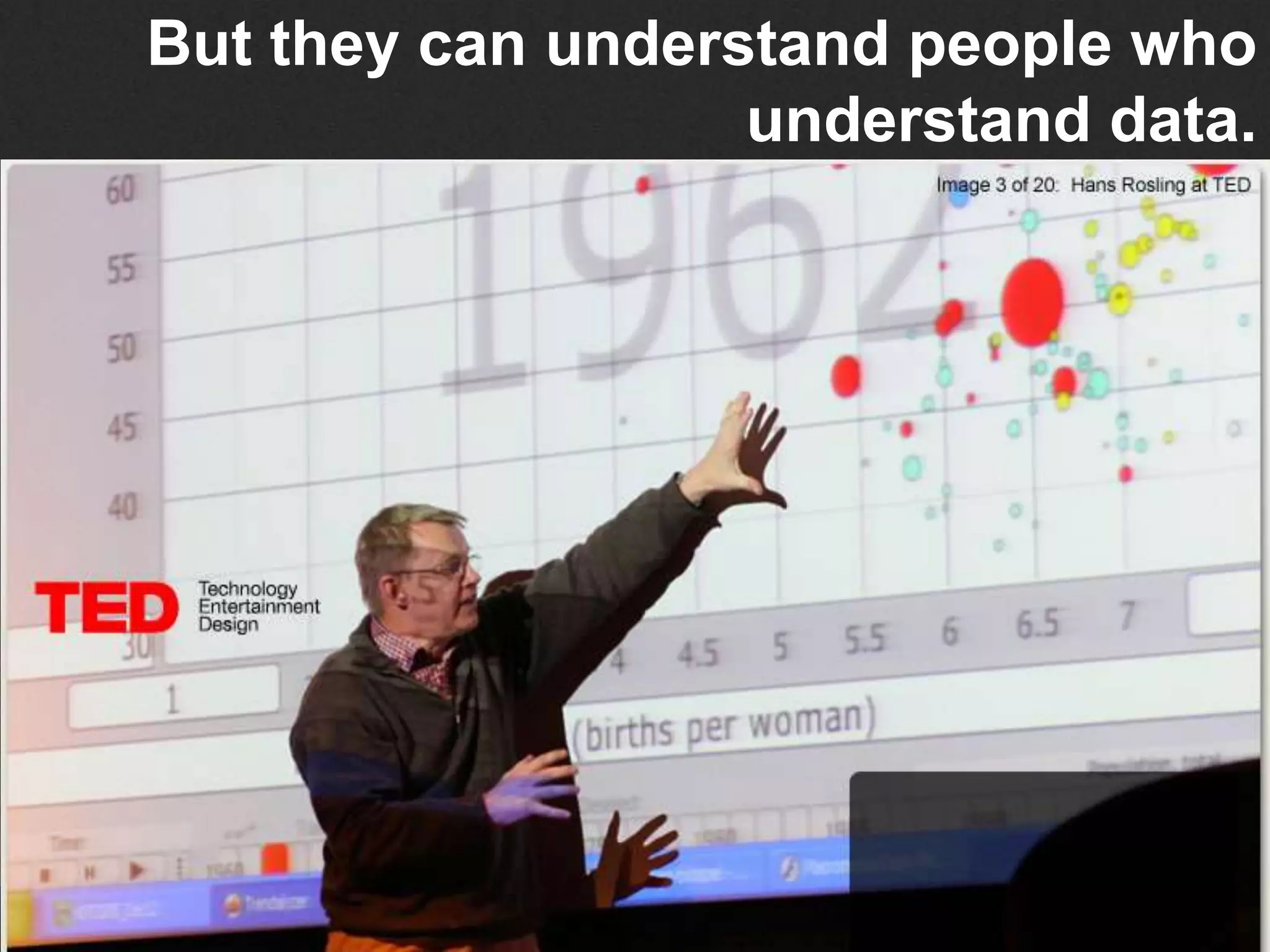



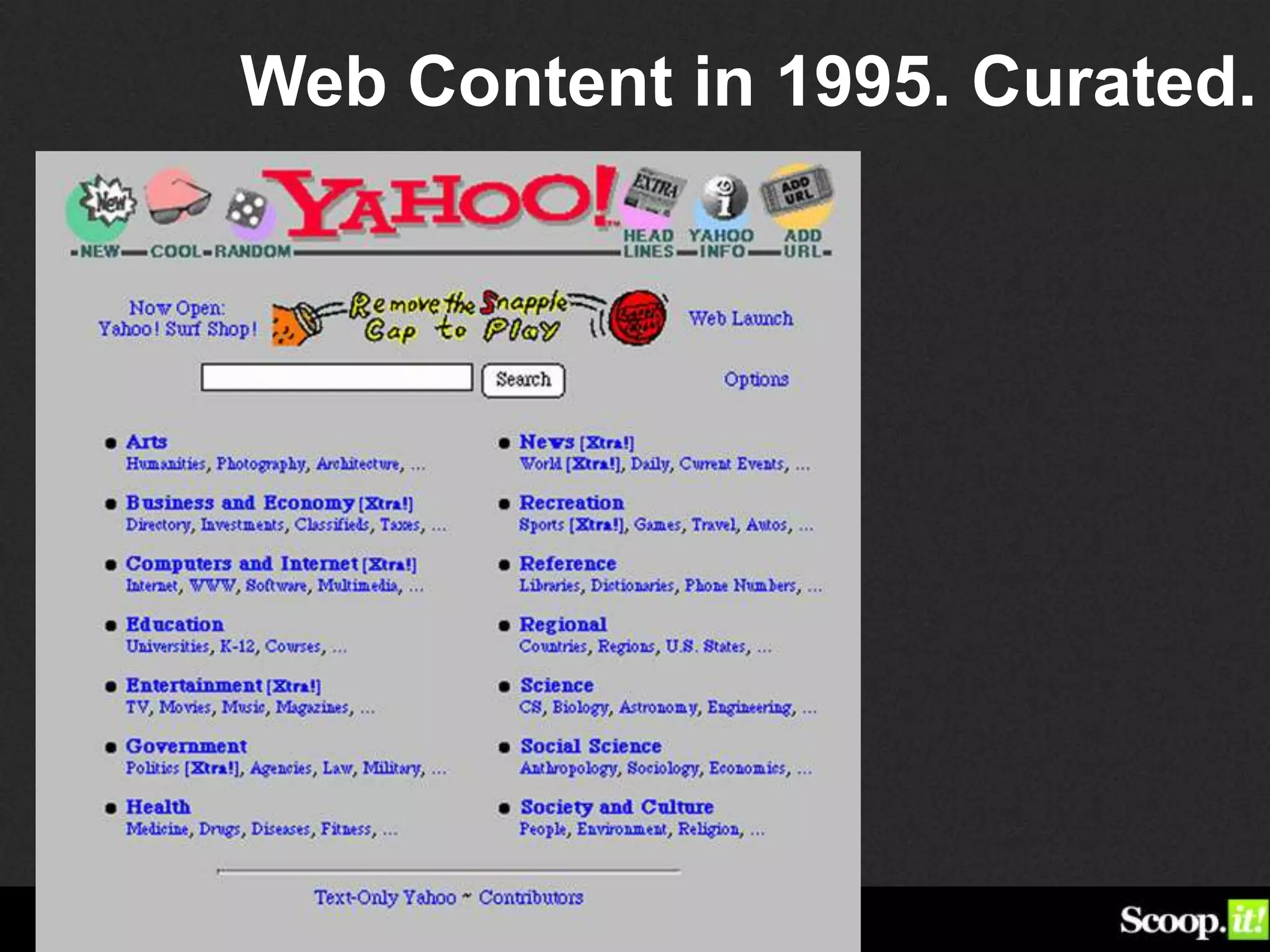
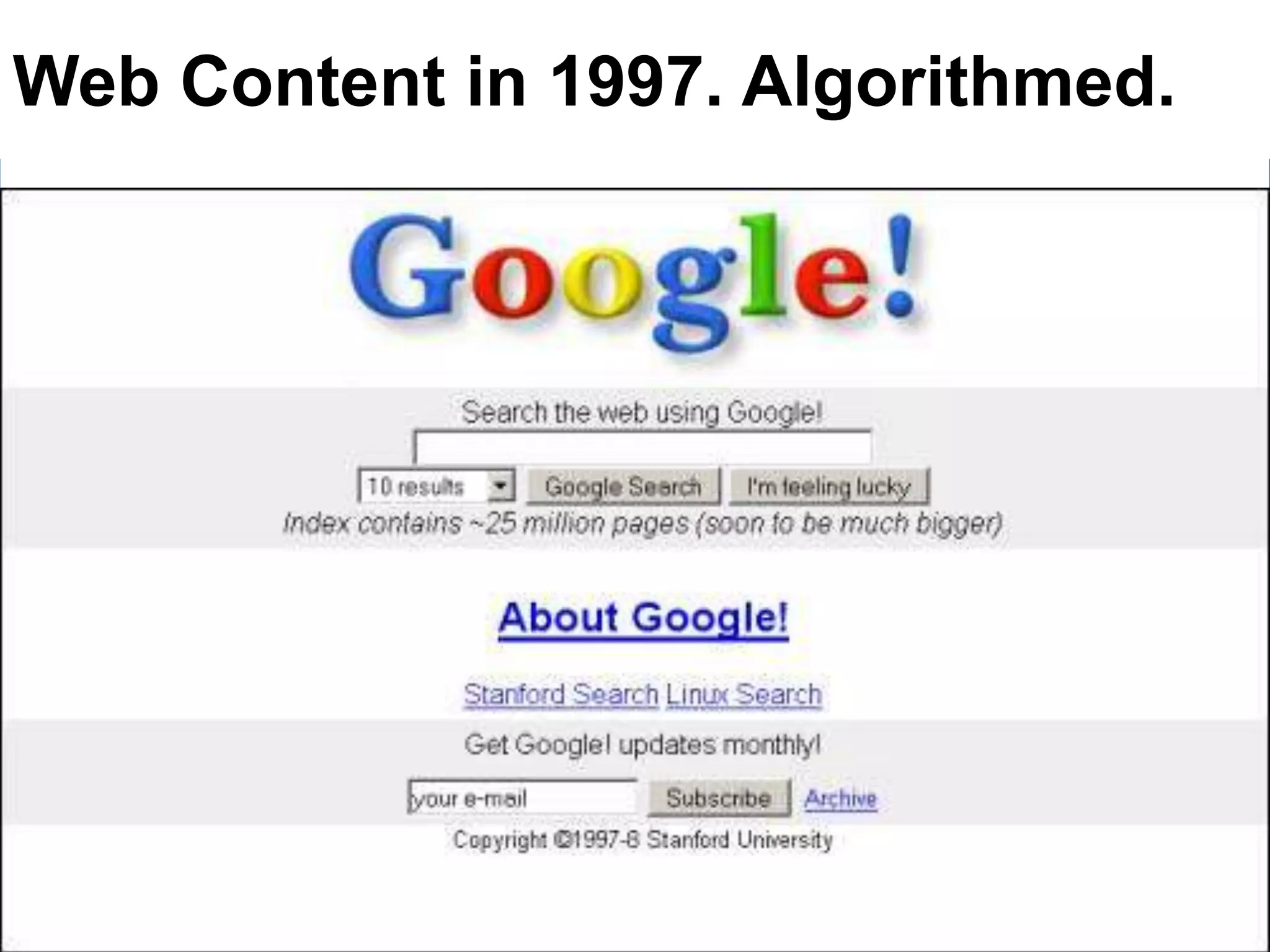






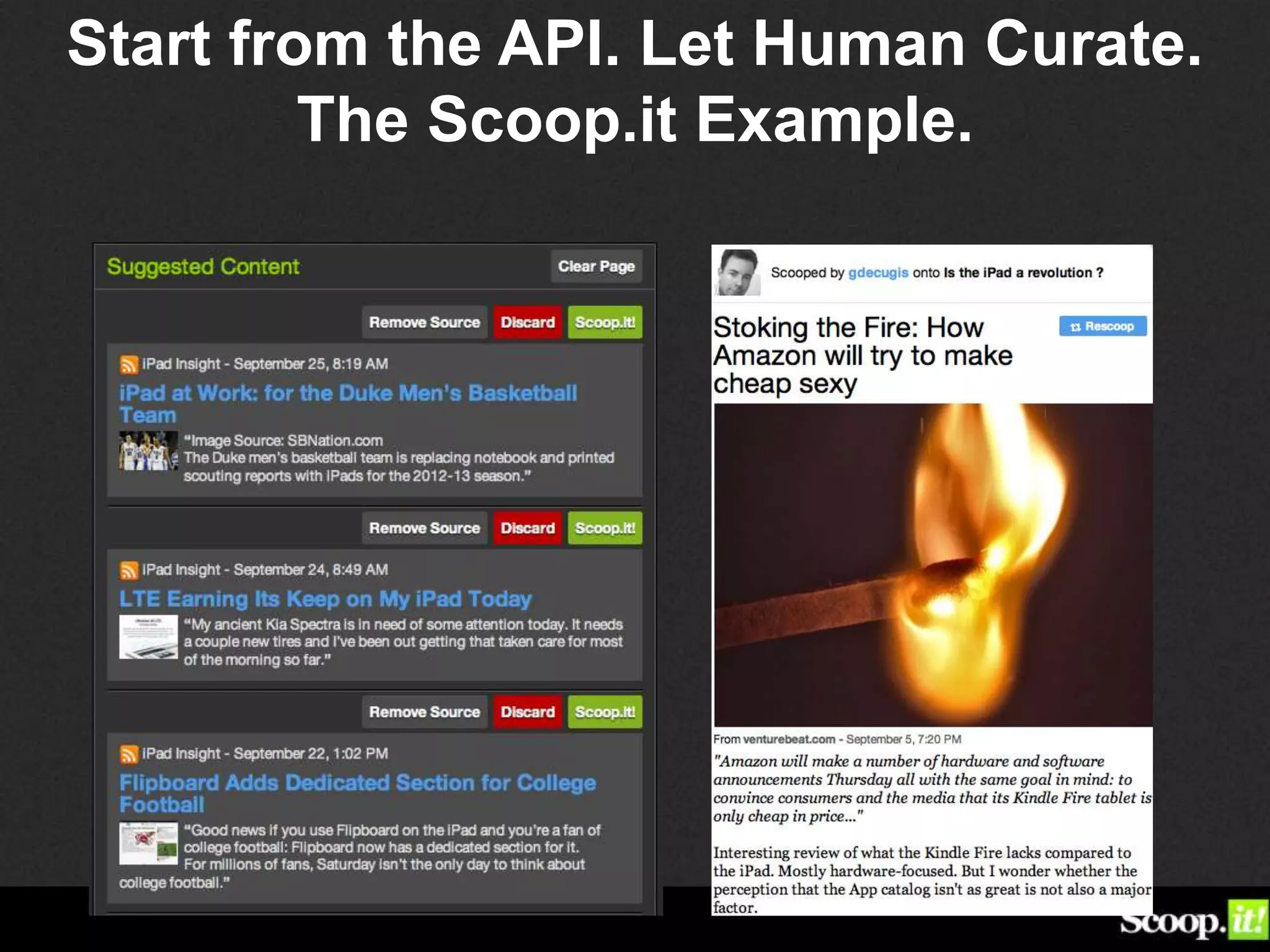




Guillaume Decugis argues that algorithms alone cannot effectively curate content, emphasizing the indispensable role of human data editors and curators. He highlights the limitations of content personalization algorithms and the importance of human input in the curation process. The document advocates for a blend of technology and human oversight in content management to ensure quality and relevance.
































![[Whitepaper] Robots in Recruiting - The Implications of AI on Talent Acquisition](https://cdn.slidesharecdn.com/ss_thumbnails/whitepaperrobotsinrecruiting-theimplicationsofaiontalentacquisition-170526132109-thumbnail.jpg?width=640&height=640&fit=bounds)









![[REPORT PREVIEW] The Customer Experience of AI](https://cdn.slidesharecdn.com/ss_thumbnails/slideshare-cx-of-ai-171116034109-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC MENA 24] Nezar_El_Kady_-_From_Turing_to_Transformers__Navigating_the_AI_...](https://cdn.slidesharecdn.com/ss_thumbnails/3flkch6oqtqw0muwpnms-nazar-el-kady-from-turing-to-transformers-navigating-the-ai-revolution-240427153005-5ee8a5b6-thumbnail.jpg?width=640&height=640&fit=bounds)


![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















