Download as PDF, PPTX




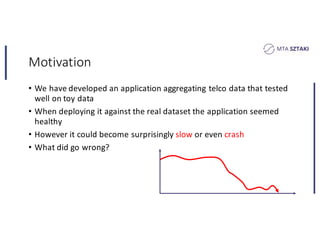
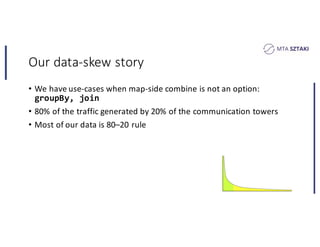
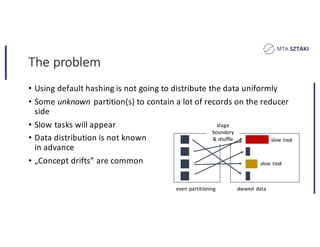

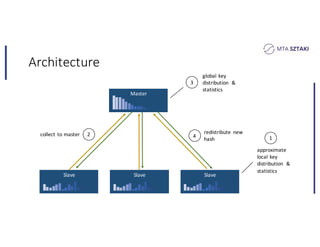


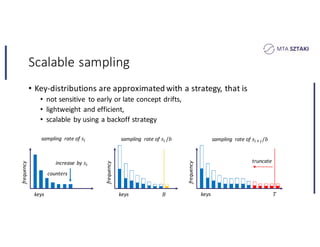





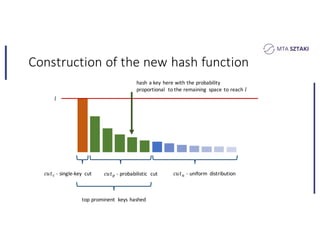


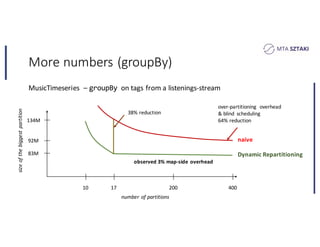
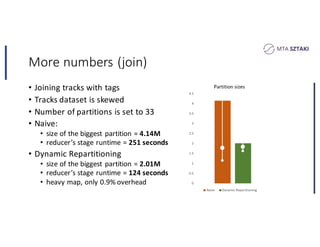

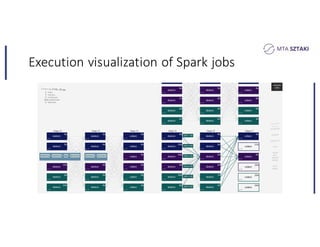
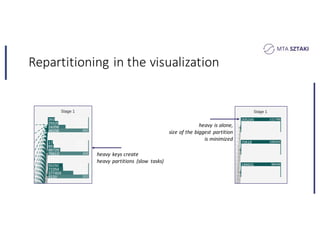



This document discusses handling data skew in Spark using dynamic repartitioning. It presents an architecture for dynamic repartitioning that collects data characteristics during job execution, decides when repartitioning is needed based on those characteristics, and constructs a new hash function to redistribute the data more uniformly. It aims to mitigate the problem of slow tasks caused by skewed data distributions. Benchmark results show the approach can significantly reduce the size of the largest partition and execution time for jobs operating on skewed data.











































































































