Downloaded 22 times





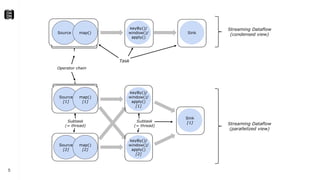
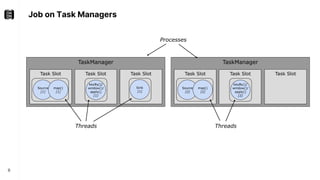





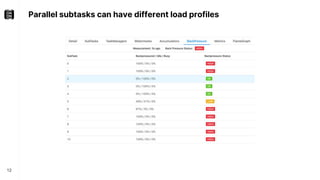
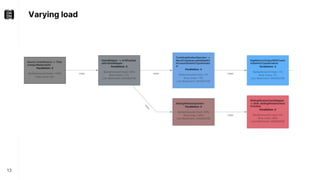
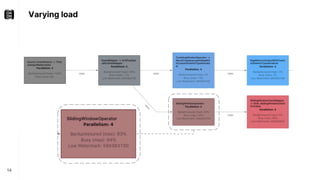





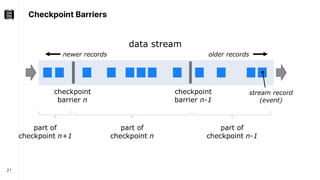
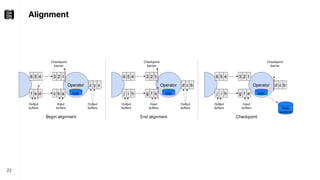
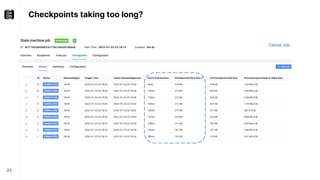










The document discusses performance troubleshooting in Apache Flink, highlighting the common bottlenecks in processing records, checkpointing, and recovery. It provides a step-by-step approach to identify and analyze performance issues, including the significance of analyzing machine metrics and leveraging profiling tools. Recommendations for improving checkpoint performance and recovery times are also outlined, emphasizing the importance of addressing backpressure and resource overload.



















































































