

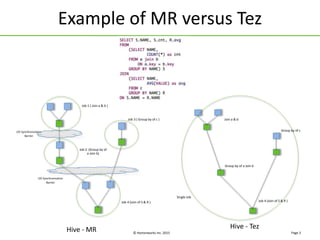
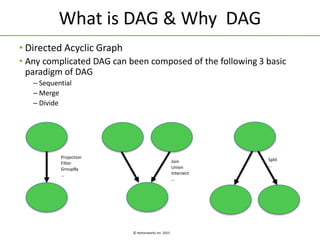


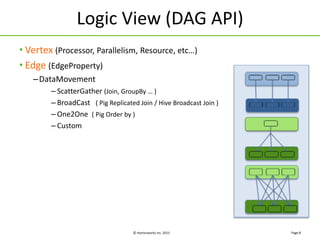





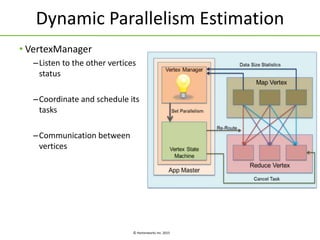


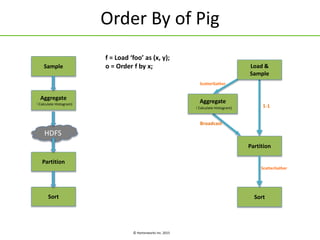



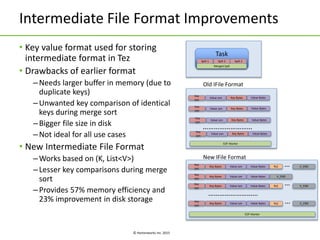



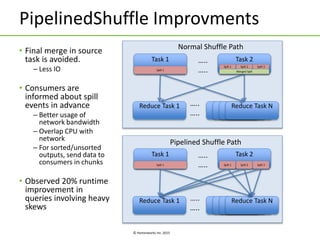

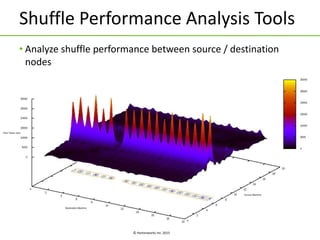
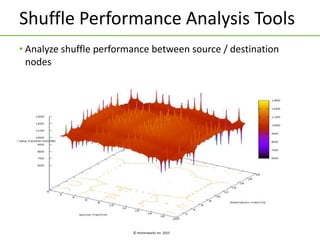

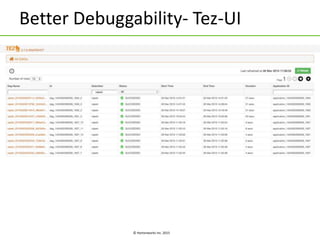
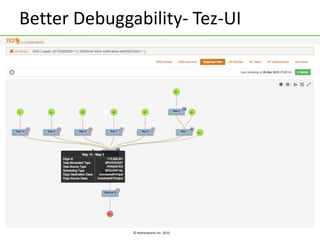

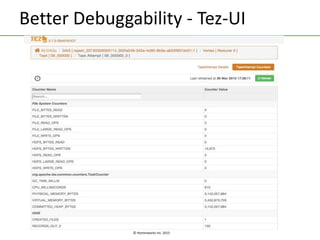




The document discusses Apache Tez, a framework for building data processing applications on Hadoop. It provides an introduction to Tez and describes key features like expressing computations as directed acyclic graphs (DAGs), container reuse, dynamic parallelism, integration with YARN timeline service, and recovery from failures. The document also outlines improvements to Tez around performance, debuggability, and status/roadmap.































































![[2C1] 아파치 피그를 위한 테즈 연산 엔진 개발하기 최종](https://cdn.slidesharecdn.com/ss_thumbnails/2b1-140929191628-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










































