
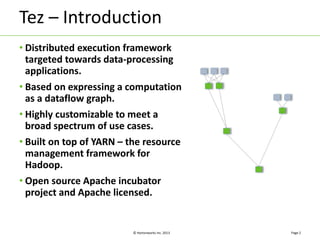




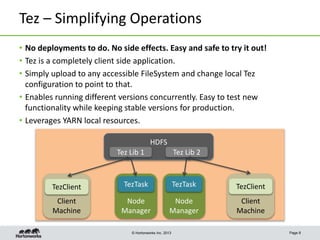



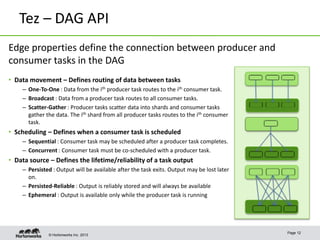




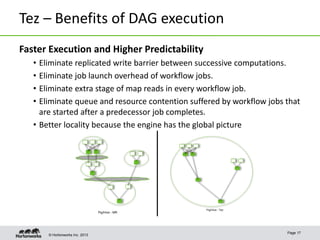




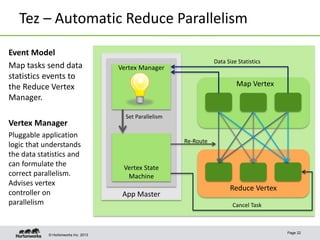

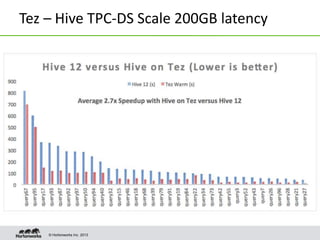






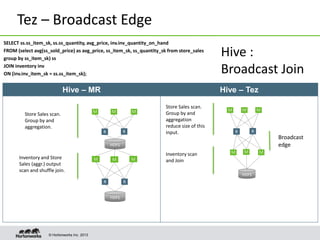








Apache Tez is a framework for accelerating Hadoop query processing. It is based on expressing a computation as a dataflow graph and executing it in a highly customizable way. Tez is built on top of YARN and provides benefits like better performance, predictability, and utilization of cluster resources compared to traditional MapReduce. It allows applications to focus on business logic rather than Hadoop internals.











































![[2C1] 아파치 피그를 위한 테즈 연산 엔진 개발하기 최종](https://cdn.slidesharecdn.com/ss_thumbnails/2b1-140929191628-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










































